| You are here: | ||
| <<< Previous | Home | Next >>> |
This chapter describes the role and taxonomy of architecture views.
Note that some of the material in this section is from The Command and Control System Target Architecture (C2STA), which was developed by the Electronic Systems Center (ESC) of the US Air Force between 1997 and 2000.
Architecture views are representations of the overall architecture that are meaningful to one or more stakeholders in the system. The architect chooses and develops a set of views that will enable the architecture to be communicated to, and understood by, all the stakeholders, and enable them to verify that the system will address their concerns.
An architecture is usually represented by means of one or more architecture models that together provide a coherent description of the system's architecture. A single, comprehensive model is often too complex to be understood and communicated in its most detailed form, showing all the relationships between the various business and technical components. As with the architecture of a building, it is normally necessary to develop multiple views of the architecture of an information system, to enable the architecture to be communicated to, and understood by, the different stakeholders in the system.
For example, just as a building architect might create wiring diagrams, floor plans, and elevations to describe different facets of a building to its different stakeholders (electricians, owners, planning officials), so an IT architect might create physical and security views of an IT system for the stakeholders who have concerns related to these aspects.
An important recent development in IT architecture practice has been the emergence of standards for architecture description, principally through the adoption by ANSI and the IEEE of ANSI/IEEE Std 1471-2000, Recommended Practice for Architectural Description of Software-Intensive Systems. One of the aims of this standard is to promote a more consistent, systematic approach to the creation of views.
At the present time, TOGAF encourages but does not mandate the use of ANSI/IEEE Std 1471-2000.
Organizations that have incorporated, or plan to incorporate, ANSI/IEEE Std 1471-2000 into their IT architecture practice should find that none of the key concepts in TOGAF is incompatible with this standard, although some of the terminology used is not completely consistent with it.
In TOGAF we endeavor to strike a balance between promoting the concepts and terminology of ANSI/IEEE Std 1471-2000 - ensuring that our usage of terms defined by ANSI/IEEE Std 1471-2000 is consistent with the standard - and retaining other commonly accepted terminology that is familiar to the majority of the TOGAF readership.
An example of common terminology retained in TOGAF is the use of the terms "Business Architecture", "Technology Architecture", etc. These terms reflect common usage, but are at variance with ANSI/IEEE Std 1471-2000 (in which "architecture" is a property of a thing, not a thing in its own right). This situation will be reviewed in future versions of TOGAF. The process of gradual convergence between TOGAF and relevant standards for architecture description will continue as ANSI/IEEE Std 1471-2000 gains increased acceptance within the industry.
More general information about ANSI/IEEE Std 1471-2000 can be obtained from the IEEE Architecture Working Group (see www.pithecanthropus.com/˜awg).
It is arguable that the term "architecture" in this document should be replaced with the term "view", in accordance with ANSI/IEEE Std 1471-2000 recommended practice. There are practical problems with this.
Firstly, there is common usage. Typically an overall enterprise architecture comprising all four "architectures" (Business, Data, Applications, Technology) will not be undertaken as a single project. Rather each "architecture" - and in some cases, subsets of them - will be undertaken as individual projects. The ultimate deliverable of such a project is commonly referred to as an "... architecture" (for example, a Business Architecture). Within such an architecture there will very likely be views, in the true ANSI/IEEE Std 1471-2000 sense.
Secondly, such individual projects - leading to a "Business Architecture", or an "Applications Architecture", etc. - are often undertaken without any intent to develop all four "architectures" and integrate them into an overall enterprise architecture. (Or at least, there may be a long-term strategic goal to develop all four, but the initial development may be intended as a free-standing architecture and not a view of some larger entity.)
In summary, therefore, choice of terminology will depend largely on the extent to which the enterprise concerned regards each of the above as a part of a larger enterprise architecture.
For the present, TOGAF retains the terminology of "Business Architecture", "Technology Architecture", etc., since the terminology associated with ANSI/IEEE Std 1471-2000 recommended practice is still relatively new to the industry and not yet in widespread use. This situation will be reviewed in future versions of TOGAF.
The following concepts are central to the topic of views. These concepts have been adapted from more formal definitions contained in ANSI/IEEE Std 1471-2000.
A system is a collection of components organized to accomplish a specific function or set of functions.
The architecture of a system is the system's fundamental organization, embodied in its components, their relationships to each other and to the environment, and the principles guiding its design and evolution.
An architecture description is a collection of artifacts that document an architecture. In TOGAF, architecture views are the key artifacts in an architecture description.
Stakeholders are people who have key roles in, or concerns about, the system; for example, as users, developers, or managers. Different stakeholders with different roles in the system will have different concerns. Stakeholders can be individuals, teams, or organizations (or classes thereof).
Concerns are the key interests that are crucially important to the stakeholders in the system, and determine the acceptability of the system. Concerns may pertain to any aspect of the system's functioning, development, or operation, including considerations such as performance, reliability, security, distribution, and evolvability.
A view is a representation of a whole system from the perspective of a related set of concerns.
In capturing or representing the design of a system architecture, the architect will typically create one or more architecture models, possibly using different tools. A view will comprise selected parts of one or more models, chosen so as to demonstrate to a particular stakeholder or group of stakeholders that their concerns are being adequately addressed in the design of the system architecture.
A viewpoint defines the perspective from which a view is taken. More specifically, a viewpoint defines: how to construct and use a view (by means of an appropriate schema or template); the information that should appear in the view; the modeling techniques for expressing and analyzing the information; and a rationale for these choices (e.g., by describing the purpose and intended audience of the view).
In summary, then, architecture views are representations of the overall architecture in terms meaningful to stakeholders. They
enable the architecture to be communicated to and understood by the stakeholders, so they can verify that the system will address
their concerns.
Concerns are the root of the process of decomposition into requirements. Concerns are represented in the architecture by these requirements. Requirements should be SMART (e.g., specific metrics).
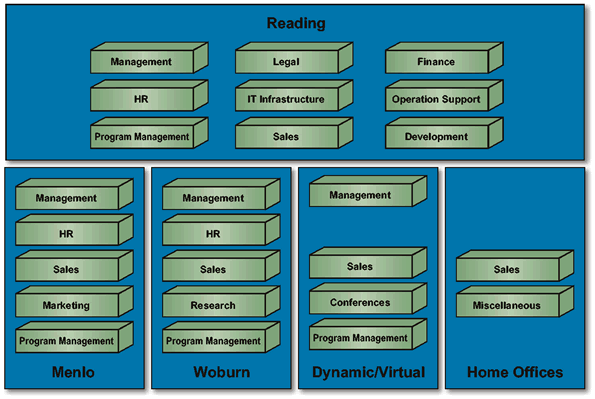
For many architectures, a useful viewpoint is that of business domains, which can be illustrated by an example from The Open Group itself.
The viewpoint is specified as follows:
|
Viewpoint Element |
Description |
|---|---|
|
Stakeholders |
Management Board, Chief Information Officer |
|
Concerns |
Show the top-level relationships between geographical sites and business functions. |
|
Modeling technique |
Nested boxes diagram. |
The corresponding view of The Open Group (in 2001) is shown in Example View - The Open Group Business Domains in 2001 .
The choice of which particular architecture views to develop is one of the key decisions that the architect has to make.
The architect has a responsibility for ensuring the completeness (fitness-for-purpose) of the architecture, in terms of adequately addressing all the pertinent concerns of its stakeholders; and the integrity of the architecture, in terms of connecting all the various views to each other, satisfactorily reconciling the conflicting concerns of different stakeholders, and showing the trade-offs made in so doing (as between security and performance, for example).
The choice has to be constrained by considerations of practicality, and by the principle of fitness-for-purpose (i.e., the architecture should be developed only to the point at which it is fit-for-purpose, and not reiterated ad infinitum as an academic exercise).
As explained in Part II: Architecture Development Method (ADM), the development of architecture views is an iterative process. The typical progression is from business to technology, using a technique such as business scenarios (see Business Scenarios) to properly identify all pertinent concerns; and from high-level overview to lower-level detail, continually referring back to the concerns and requirements of the stakeholders throughout the process.
Moreover, each of these progressions has to be made for two distinct environments: the existing environment (referred to as the baseline in the ADM) and the target environment. The architect must develop pertinent Business and Technology Architecture views of both the existing system and the target system. This provides the context for the gap analysis at the end of Phase C of the ADM, which establishes which elements of the current system must be carried forward and which must be removed or replaced.
This whole process is explained in Part II: Architecture Development Method (ADM), Step 2 .
As mentioned above, at the present time TOGAF encourages but does not mandate the use of ANSI/IEEE Std 1471-2000. The following description therefore covers both the situation where ANSI/IEEE Std 1471-2000 has been adopted and where it has not.
ANSI/IEEE Std 1471-2000 itself does not require any specific process for developing viewpoints or creating views from them. Where ANSI/IEEE Std 1471-2000 has been adopted and become well-established practice within an organization, it will often be possible to create the required views for a particular architecture by following these steps:
This approach can be expected to bring the following benefits:
However, situations can always arise in which a view is needed for which no appropriate viewpoint has been pre-defined. This is also the situation, of course, when an organization has not yet incorporated ANSI/IEEE Std 1471-2000 into its architecture practice and established a library of viewpoints.
In each case, the architect may choose to develop a new viewpoint that will cover the outstanding need, and then generate a view from it. (This is the ANSI/IEEE Std 1471-2000 recommended practice.) Alternatively, a more pragmatic approach can be equally successful: the architect can create an ad hoc view for a specific system and later consider whether a generalized form of the implicit viewpoint should be defined explicitly and saved in a library, so that it can be re-used. (This is one way of establishing a library of viewpoints initially.)
Whatever the context, the architect should be aware that every view has a viewpoint, at least implicitly, and that defining the viewpoint in a systematic way (as recommended by ANSI/IEEE Std 1471-2000) will help in assessing its effectiveness (i.e., does the viewpoint cover the relevant stakeholder concerns?).
TOGAF's core taxonomy of architecture views defines the minimum set of views that should be considered in the development of an architecture.
Since in ANSI/IEEE Std 1471-2000 every view has an associated viewpoint that defines it, this taxonomy may also be regarded as a taxonomy of viewpoints by those organizations that have adopted ANSI/IEEE Std 1471-2000.
The minimum set of stakeholders for a system that should be considered in the development of architecture viewpoints and views is:
The architecture views, and corresponding viewpoints, that may be created to support each of these stakeholders fall into the following categories. (As mentioned above, this taxonomy may be regarded as a taxonomy of viewpoints by those organizations that have adopted ANSI/IEEE Std 1471-2000.)
Examples of specific views that may be created in each category are tabulated below, and explained in detail in the following subsection.
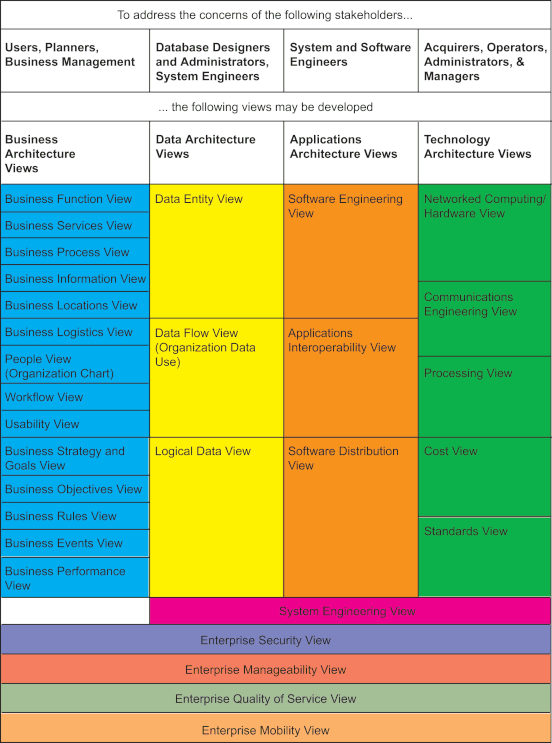
A mapping of these views to the schema of the well-known Zachman Framework is illustrated below.
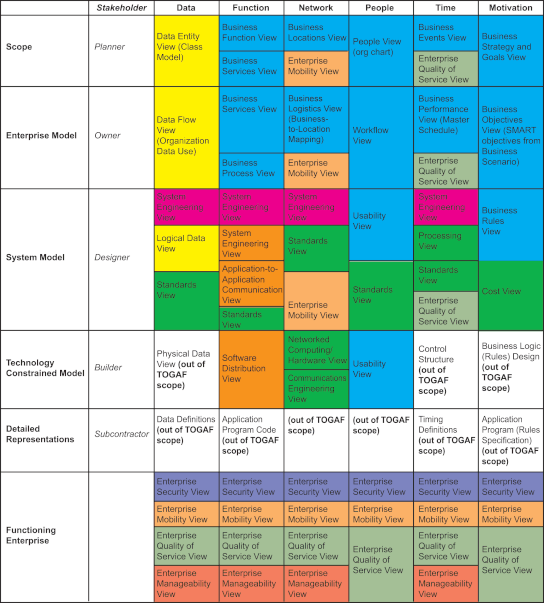
The following description explains some of the views listed above. A more detailed description of each view, and guidelines for developing it, can be obtained by following the relevant hyperlink in the following.
These views typically depict building blocks of the architecture that can be purchased, and the standards that the building blocks must adhere to in order for the building block to be most useful.
Architects also have concerns of their own which basically define the fitness-for-purpose of an effort. Architects must understand completeness, where completeness includes considering all relevant views, the relationships between those views, and dealing with the conflicts that arise from those different views. Architects also must deal with viability of the architecture: if the architecture is not capable of being implemented, then its value is in doubt.
The need for architecture views, and the process of developing them following the Architecture Development Method (ADM), are explained above. This subsection describes the relationships between architecture views, the tools used to develop and analyze them, and a standard language enabling interoperability between the tools.
In order to achieve the goals of completeness and integrity in an architecture, architecture views are usually developed, visualized, communicated, and managed using a tool.
In the current state of the market, different tools normally have to be used to develop and analyze different views of the architecture. It is highly desirable that an architecture description be encoded in a standard language, to enable a standard approach to the description of architecture semantics and their re-use among different tools.
A viewpoint is also normally developed, visualized, communicated, and managed using a tool, and it is also highly desirable that standard viewpoints (i.e., templates or schemas) be developed, so that different tools that deal in the same views can interoperate, the fundamental elements of an architecture can be re-used, and the architecture description can be shared among tools.
Issues relating to the evaluation of tools for architecture work are discussed in detail in Tools for Architecture Development .
To illustrate the concepts of views and viewpoints, consider the example of a very simple airport system with two different stakeholders, the pilot and the air traffic controller.
The pilot has one view of the system, and the air traffic controller has another. Neither view represents the whole system, because the perspective of each stakeholder constrains (and reduces) how each sees the overall system.
The view of the pilot comprises some elements not viewed by the controller, such as passengers and fuel, while the view of the controller comprises some elements not viewed by the pilot, such as other planes. There are also elements shared between the views, such as the communication model between the pilot and the controller, and the vital information about the plane itself.
A viewpoint is a model (or description) of the information contained in a view. In our example, one viewpoint is the description of how the pilot sees the system, and the other viewpoint is how the controller sees the system.
Pilots describe the system from their perspective, using a model of their position and vector toward or away from the runway. All pilots use this model, and the model has a specific language that is used to capture information and populate the model.
Controllers describe the system differently, using a model of the airspace and the locations and vectors of aircraft within the airspace. Again, all controllers use a common language derived from the common model in order to capture and communicate information pertinent to their viewpoint.
Fortunately, when controllers talk with pilots, they use a common communication language. (In other words, the models representing their individual viewpoints partially intersect.) Part of this common language is about location and vectors of aircraft, and is essential to safety.
So in essence each viewpoint is an abstract model of how all the stakeholders of a particular type - all pilots, or all controllers - view the airport system.
Tools exist to assist stakeholders, especially when they are interacting with complex models such as the model of an airspace, or the model of air flight.
The interface to the human user of a tool is typically close to the model and language associated with the viewpoint. The unique tools of the pilot are fuel, altitude, speed, and location indicators. The main tool of the controller is radar. The common tool is a radio.
To summarize from the above example, we can see that a view can subset the system through the perspective of the stakeholder, such as the pilot versus the controller. This subset can be described by an abstract model called a viewpoint, such as an air flight versus an air space model. This description of the view is documented in a partially specialized language, such as "pilot-speak" versus "controller-speak". Tools are used to assist the stakeholders, and they interface with each other in terms of the language derived from the viewpoint ("pilot-speak" versus' "controller-speak").
When stakeholders use common tools, such as the radio contact between pilot and controller, a common language is essential.
Now let us map this example to the Information Systems Architecture. Consider two stakeholders in a new small computing system: the users and the developers.
The users of the system have a view of the system, and the developers of the system have a different view. Neither view represents the whole system, because each perspective reduces how each sees the system.
The view of the user is comprised of all the ways in which s/he interacts with the system, not seeing any details such as applications or Database Management Systems (DBMS).
The view of the developer is one of productivity and tools, and doesn't include things such as actual live data and connections with consumers.
However, there are things that are shared, such as descriptions of the processes that are enabled by the system and/or communications protocols set up for users to communicate problems directly to development.
In this example, one viewpoint is the description of how the user sees the system, and the other viewpoint is how the developer sees the system. Users describe the system from their perspective, using a model of availability, response time, and access to information. All users of the system use this model, and the model has a specific language.
Developers describe the system differently than users, using a model of software connected to hardware distributed over a network, etc. However, there are many types of developers (database, security, etc.) of the system, and they do not have a common language derived from the model.
Tools exist for both users and developers. Tools such as online help are there specifically for users, and attempt to use the language of the user. Many different tools exist for different types of developers, but they suffer from the lack of a common language that is required to bring the system together. It is difficult, if not impossible, in the current state of the tools market to have one tool interoperate with another tool.
Issues relating to the evaluation of tools for architecture work are discussed in detail in Tools for Architecture Development .
This section attempts to deal with views in a structured manner, but this is by no means a complete treatise on views.
In general, TOGAF embraces the concepts and definitions presented in ANSI/IEEE Std 1471-2000, specifically the concepts that help guide the development of a view and make the view actionable. These concepts can be summarized as:
In the following subsections TOGAF presents some recommended views, some or all of which may be appropriate in a particular architecture development. This is not intended as an exhaustive set of views, but simply as a starting point. Those described may be supplemented by additional views as required. These TOGAF subsections on views should be considered as guides for the development and treatment of a view, not as a full definition of a view.
Each subsection describes the stakeholders related to the view, their concerns, and the entities modeled and the language used to depict the view (the viewpoint). The viewpoint provides architecture concepts from the different perspectives, including components, interfaces, and allocation of services critical to the view. The viewpoint language, analytical methods, and modeling methods associated with views are typically applied with the use of appropriate tools.
The Business Architecture view is concerned with addressing the concerns of users.
This view should be developed for the users. It focuses on the functional aspects of the system from the perspective of the users of the system.
Addressing the concerns of the users includes consideration of the following:
Business scenarios (see Business Scenarios) are an important technique that may be used prior to, and as a key input to, the development of the Business Architecture view, to help identify and understand business needs, and thereby to derive the business requirements and constraints that the architecture development has to address. Business scenarios are an extremely useful way to depict what should happen when planned and unplanned events occur. It is highly recommended that business scenarios be created for planned change, and for unplanned change.
The following paragraphs describe some of the key issues that the architect might consider when constructing business scenarios.
The Business Architecture view considers the functional aspects of the system; that is, what the new system is intended to do. This can be built up from an analysis of the existing environment and of the requirements and constraints affecting the new system.
The new requirements and constraints will appear from a number of sources, possibly including:
What should emerge from the Business Architecture view is a clear understanding of the functional requirements for the new architecture, with statements like: "Improvements in handling customer enquiries are required through wider use of computer/telephony integration".
The Business Architecture view considers the usability aspects of the system and its environment. It should also consider impacts on the user such as skill levels required, the need for specialized training, and migration from current practice. When considering usability the architect should take into account:
Note that, although security and management are thought about here, it is from a usability and functionality point of view. The technical aspects of security and management are considered in the enterprise security view (see Developing an Enterprise Security View) and the enterprise manageability view (see Developing an Enterprise Manageability View).
The enterprise security view is concerned with the security aspects of the system.
This view should be developed for security engineers of the system. It focuses on how the system is implemented from the perspective of security, and how security affects the system properties. It examines the system to establish what information is stored and processed, how valuable it is, what threats exist, and how they can be addressed.
Major concerns for this view are understanding how to ensure that the system is available to only those that have permission, and how to protect the system from unauthorized tampering.
The subjects of the general architecture of a "security system" are components that are secured, or components that provide security services. Additionally Access Control Lists (ACLs) and security schema definitions are used to model and implement security.
This section presents basic concepts required for an understanding of information system security.
The essence of security is the controlled use of information. The purpose of this section is to provide a brief overview of how security protection is implemented in the components of an information system. Doctrinal or procedural mechanisms, such as physical and personnel security procedures and policy, are not discussed here in any depth.
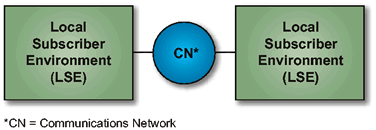
Abstract Security Architecture View depicts an abstract view of an Information Systems Architecture, which emphasizes the fact that an information system from the security perspective is either part of a Local Subscriber Environment (LSE) or a Communications Network (CN). An LSE may be either fixed or mobile. The LSEs by definition are under the control of the using organization. In an open system distributed computing implementation, secure and non-secure LSEs will almost certainly be required to interoperate.
The concept of an information domain provides the basis for discussing security protection requirements. An information domain is defined as a set of users, their information objects, and a security policy. An information domain security policy is the statement of the criteria for membership in the information domain and the required protection of the information objects. Breaking an organization's information down into domains is the first step in reducing the task of security policy development to a manageable size.
The business of most organizations requires that their members operate in more than one information domain. The diversity of business activities and the variation in perception of threats to the security of information will result in the existence of different information domains within one organization security policy. A specific activity may use several information domains, each with its own distinct information domain security policy.
Information domains are not necessarily bounded by information systems or even networks of systems. The security mechanisms implemented in information system components may be evaluated for their ability to meet the information domain security policies.
Information domains can be viewed as being strictly isolated from one another. Information objects should be transferred between two information domains only in accordance with established rules, conditions, and procedures expressed in the security policy of each information domain.
The concept of "absolute protection" is used to achieve the same level of protection in all information systems supporting a particular information domain. It draws attention to the problems created by interconnecting LSEs that provide different strengths of security protection. This interconnection is likely because open systems may consist of an unknown number of heterogeneous LSEs. Analysis of minimum security requirements will ensure that the concept of absolute protection will be achieved for each information domain across LSEs.
Generic Security Architecture View shows a generic architecture view which can be used to discuss the allocation of security services and the implementation of security mechanisms. This view identifies the architectural components within an LSE. The LSEs are connected by CNs. The LSEs include end systems, relay systems, and Local Communications Systems (LCSs), described below.
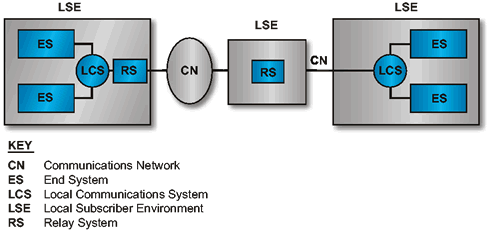
The end system and the relay system are viewed as requiring the same types of security protection. For this reason, a discussion of security protection in an end system generally also applies to a relay system. The security protections in an end system could occur in both the hardware and software.
Security protection of an information system is provided by mechanisms implemented in the hardware and software of the system and by the use of doctrinal mechanisms. The mechanisms implemented in the system hardware and software are concentrated in the end system or relay system. This focus for security protection is based on the open system, distributed computing approach for information systems. This implies use of commercial common carriers and private common-user communications systems as the CN provider between LSEs. Thus, for operation of end systems in a distributed environment, a greater degree of security protection can be assured from implementation of mechanisms in the end system or relay system.
However, communications networks should satisfy the availability element of security in order to provide appropriate security protection for the information system. This means that CNs must provide an agreed level of responsiveness, continuity of service, and resistance to accidental and intentional threats to the communications service availability.
Implementing the necessary security protection in the end system occurs in three system service areas of TOGAF. They are operating system services, network services, and system management services.
Most of the implementation of security protection is expected to occur in software. The hardware is expected to protect the integrity of the end-system software. Hardware security mechanisms include protection against tampering, undesired emanations, and cryptography.
A "security context" is defined as a controlled process space subject to an information domain security policy. The security context is therefore analogous to a common operating system notion of user process space. Isolation of security contexts is required. Security contexts are required for all applications (e.g., end-user and security management applications). The focus is on strict isolation of information domains, management of end-system resources, and controlled sharing and transfer of information among information domains. Where possible, security-critical functions should be isolated into relatively small modules that are related in well-defined ways.
The operating system will isolate multiple security contexts from each other using hardware protection features (e.g., processor state register, memory mapping registers) to create separate address spaces for each of them. Untrusted software will use end-system resources only by invoking security-critical functions through the separation kernel. Most of the security-critical functions are the low-level functions of traditional operating systems.
Two basic classes of communications are envisioned for which distributed security contexts may need to be established. These are interactive and staged (store and forward) communications.
The concept of a "security association" forms an interactive distributed security context. A security association is defined as all the communication and security mechanisms and functions that extend the protections required by an information domain security policy within an end system to information in transfer between multiple end systems. The security association is an extension or expansion of an OSI application layer association. An application layer association is composed of appropriate application layer functions and protocols plus all of the underlying communications functions and protocols at other layers of the OSI model. Multiple security protocols may be included in a single security association to provide for a combination of security services.
For staged delivery communications (e.g., email), use will be made of an encapsulation technique (termed "wrapping process") to convey the necessary security attributes with the data being transferred as part of the network services. The wrapped security attributes are intended to permit the receiving end system to establish the necessary security context for processing the transferred data. If the wrapping process cannot provide all the necessary security protection, interactive security contexts between end systems will have to be used to ensure the secure staged transfer of information.
Security management is a particular instance of the general information system management functions discussed in earlier chapters. Information system security management services are concerned with the installation, maintenance, and enforcement of information domain and information system security policy rules in the information system intended to provide these security services. In particular, the security management function controls information needed by operating system services within the end system security architecture. In addition to these core services, security management requires event handling, auditing, and recovery. Standardization of security management functions, data structures, and protocols will enable interoperation of Security Management Application Processes (SMAPs) across many platforms in support of distributed security management.
The software engineering view is concerned with the development of new software systems.
Building a software-intensive system is both expensive and time-consuming. Because of this, it is necessary to establish guidelines to help minimize the effort required and the risks involved. This is the purpose of the software engineering view, which should be developed for the software engineers who are going to develop the system.
Major concerns for these stakeholders are:
There are many lifecycle models defined for software development (waterfall, prototyping, etc.). A consideration for the architect is how best to feed architectural decisions into the lifecycle model that is going to be used for development of the system.
As a piece of software grows in size, so the complexity and inter-dependencies between different parts of the code increase. Reliability will fall dramatically unless this complexity can be brought under control.
Modularity is a concept by which a piece of software is grouped into a number of distinct and logically cohesive sub-units, presenting services to the outside world through a well-defined interface. Generally speaking, the components of a module will share access to common data, and the interface will provide controlled access to this data. Using modularity, it becomes possible to build a software application incrementally on a reliable base of pre-tested code.
A further benefit of a well-defined modular system is that the modules defined within it may be re-used in the same or on other projects, cutting development time dramatically by reducing both development and testing effort.
In recent years, the development of object-oriented programming languages has greatly increased programming language support for module development and code re-use. Such languages allow the developer to define "classes" (a unit of modularity) of objects that behave in a controlled and well-defined manner. Techniques such as inheritance - which enables parts of an existing interface to an object to be changed - enhance the potential for re-usability by allowing predefined classes to be tailored or extended when the services they offer do not quite meet the requirement of the developer.
If modularity and software re-use are likely to be key objectives of new software developments, consideration must be given to whether the component parts of any proposed architecture may facilitate or prohibit the desired level of modularity in the appropriate areas.
Software portability - the ability to take a piece of software written in one environment and make it run in another - is important in many projects, especially product developments. It requires that all software and hardware aspects of a chosen Technology Architecture (not just the newly developed application) be available on the new platform. It will, therefore, be necessary to ensure that the component parts of any chosen architecture are available across all the appropriate target platforms.
Interoperability is always required between the component parts of a new architecture. It may also, however, be required between a new architecture and parts of an existing legacy system; for example, during the staggered replacement of an old system. Interoperability between the new and old architectures may, therefore, be a factor in architectural choice.
This view considers two general categories of software systems. First, there are those systems that require only a user interface to a database, requiring little or no business logic built into the software. These systems can be called data-intensive. Second, there are those systems that require users to manipulate information that might be distributed across multiple databases, and to do this manipulation according to a predefined business logic. These systems can be called information-intensive.
Data-intensive systems can be built with reasonable ease through the use of 4GL tools. In these systems, the business logic is in the mind of the user; i.e., the user understands the rules for manipulating the data and uses those rules while doing his work.
Information-intensive systems are different. Information is defined as "meaningful data"; i.e., data in a context that includes business logic. Information is different from data. Data is the tokens that are stored in databases or other data stores. Information is multiple tokens of data combined to convey a message. For example, "3" is data, but "3 widgets" is information. Typically, information reflects a model. Information-intensive systems also tend to require information from other systems and, if this path of information passing is automated, usually some mediation is required to convert the format of incoming information into a format that can be locally used. Because of this, information-intensive systems tend to be more complex than others, and require the most effort to build, integrate, and maintain.
This view is concerned primarily with information-intensive systems. In addition to building systems that can manage information, though, systems should also be as flexible as possible. This has a number of benefits. It allows the system to be used in different environments; for example, the same system should be usable with different sources of data, even if the new data store is a different configuration. Similarly, it might make sense to use the same functionality but with users who need a different user interface. So information systems should be built so that they can be reconfigured with different data stores or different user interfaces. If a system is built to allow this, it enables the enterprise to re-use parts (or components) of one system in another.
The word "interoperate" implies that one processing system performs an operation on behalf of or at the behest of another processing system. In practice, the request is a complete sentence containing a verb (operation) and one or more nouns (identities of resources, where the resources can be information, data, physical devices, etc.). Interoperability comes from shared functionality.
Interoperability can only be achieved when information is passed, not when data is passed. Most information systems today get information both from their own data stores and other information systems. In some cases the web of connectivity between information systems is quite extensive. The US Air Force, for example, has a concept known as "A5 Interoperability". This means that the required data is available Anytime, Anywhere, by Anyone, who is Authorized, in Any way. This requires that many information systems are architecturally linked and provide information to each other.
There must be some kind of physical connectivity between the systems. This might be a Local Area Network (LAN), a Wide Area Network (WAN), or, in some cases, it might simply be the passing of a disk or CD between systems.1 Assuming a network connects the systems, there must be agreement on the protocols used. This enables the transfer of bits.
When the bits are assembled at the receiving system, they must be placed in the context that the receiving system needs. In other words, both the source and destination systems must agree on an information model. The source system uses this model to convert its information into data to be passed, and the destination system uses this same model to convert the received data into information it can use.
This usually requires an agreement between the architects and designers of the two systems. In the past, this agreement was often documented in the form of an Interface Control Document (ICD). The ICD defines the exact syntax and semantics that the sending system will use so that the receiving system will know what to do when the data arrives. The biggest problem with ICDs is that they tend to be unique solutions between two systems. If a given system must share information with n other systems, there is the potential need for n2 ICDs. This extremely tight integration prohibits flexibility and the ability of a system to adapt to a changing environment. Maintaining all these ICDs is also a challenge.
New technology such as eXtensible Markup Language (XML) has the promise of making data "self describing". Use of new technologies such as XML, once they become reliable and well documented, might eliminate the need for an ICD. Further, there would be Commercial Off-The-Shelf (COTS) products available to parse and manipulate the XML data, eliminating the need to develop these products in-house. It should also ease the pain of maintaining all the interfaces.
Another approach is to build "mediators" between the systems. Mediators would use metadata that is sent with the data to understand the syntax and semantics of the data and convert it into a format usable by the receiving system. However, mediators do require that well-formed metadata be sent, adding to the complexity of the interface.
Typically, software architectures are either two-tier or three-tier.2
Each tier typically presents at least one capability.
In a two-tier architecture, the user interface and business logic are tightly coupled while the data is kept independent. This gives the advantage of allowing the data to reside on a dedicated data server. It also allows the data to be independently maintained. The tight coupling of the user interface and business logic assure that they will work well together, for this problem in this domain. However, the tight coupling of the user interface and business logic dramatically increases maintainability risks while reducing flexibility and opportunities for re-use.
A three-tier approach adds a tier that separates the business logic from the user interface. This in principle allows the business logic to be used with different user interfaces as well as with different data stores. With respect to the use of different user interfaces, users might want the same user interface but using different COTS presentation servers; for example, Java Virtual Machine (JVM) or Common Desktop Environment (CDE).3 Similarly, if the business logic is to be used with different data stores, then each data store must use the same data model4 (data standardization), or a mediation tier must be added above the data store (data encapsulation).
To achieve maximum flexibility, software should utilize a five-tier scheme for software which extends the three-tier paradigm (see The Five-Tier Organization). The scheme is intended to provide strong separation of the three major functional areas of the architecture. Since there are client and server aspects of both the user interface and the data store, the scheme then has five tiers.5
The presentation tier is typically COTS-based. The presentation interface might be an X Server, Win32, etc. There should be a separate tier for the user interface client. This client establishes the look-and-feel of the interface; the server (presentation tier) actually performs the tasks by manipulating the display. The user interface client hides the presentation server from the application business logic.
The application business logic (e.g., a scheduling engine) should be a separate tier. This tier is called the "application logic" and functions as a server for the user interface client. It interfaces to the user interface typically through callbacks. The application logic tier also functions as a client to the data access tier.
If there is a user need to use an application with multiple databases with different schema, then a separate tier is needed for data access. This client would access the data stores using the appropriate COTS interface6 and then convert the raw data into an abstract data type representing parts of the information model. The interface into this object network would then provide a generalized Data Access Interface (DAI) which would hide the storage details of the data from any application that uses that data.
Each tier in this scheme can have zero or more components. The organization of the components within a tier is flexible and can reflect a number of different architectures based on need. For example, there might be many different components in the application logic tier (scheduling, accounting, inventory control, etc.) and the relationship between them can reflect whatever architecture makes sense, but none of them should be a client to the presentation server.
This clean separation of user interface, business logic, and information will result in maximum flexibility and componentized software that lends itself to product line development practices. For example, it is conceivable that the same functionality should be built once and yet be usable by different presentation servers (e.g., on PCs or UNIX system boxes), displayed with different looks and feels depending on user needs, and usable with multiple legacy databases. Moreover, this flexibility should not require massive rewrites to the software whenever a change is needed.
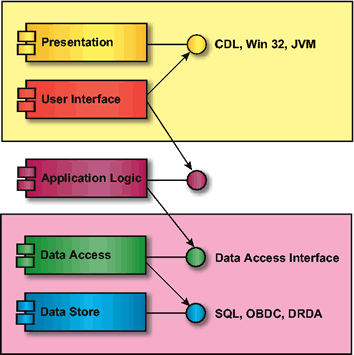
The data access tier provides a standardized view of certain classes of data, and as such functions as a server to one or more application logic tiers. If implemented correctly, there would be no need for application code to "know" about the implementation details of the data. The application code would only have to know about an interface that presents a level of abstraction higher than the data. This interface is called the Data Access Interface (DAI).
For example, should a scheduling engine need to know what events are scheduled between two dates, that query should not require knowledge of tables and joins in a relational database. Moreover, the DAI could provide standardized access techniques for the data. For example, the DAI could provide a Publish and Subscribe (P&S) interface whereby systems which require access to data stores could register an interest in certain types of data, perhaps under certain conditions, and the DAI would provide the required data when those conditions occur.
One means to instantiate a data access component is with three layers, as shown in Data Access Interface (DAI) . This is not the only means to build a DAI, but is presented as a possibility.
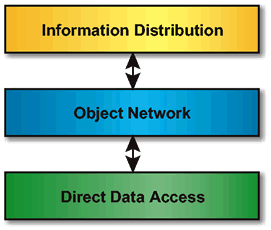
Whereas the Direct Data Access layer contains the implementation details of one or more specific data stores, the Object Network and the Information Distribution layer require no such knowledge. Instead, the upper two layers reflect the need to standardize the interface for a particular domain. The Direct Data Access layer spans the gap between the Data Access tier and the Data Store tier, and therefore has knowledge of the implementation details of the data. SQL statements, either embedded or via a standard such as DRDA or ODBC, are located here.
The Object Network layer is the instantiation in software of the information model. As such, it is an efficient means to show the relationships that hold between pieces of data. The translation of data accesses to objects in the network would be the role of the Direct Data Access layer.
Within the Information Distribution layer lies the interface to the "outside world". This interface typically uses a data bus to distribute the data (see below).7 It could also contain various information-related services; for example, a P&S registry and publication service or an interface to a security server for data access control.8 The Information Distribution layer might also be used to distribute applications or applets required to process distributed information. Objects in the object network would point to the applications or applets, allowing easy access to required processing code.
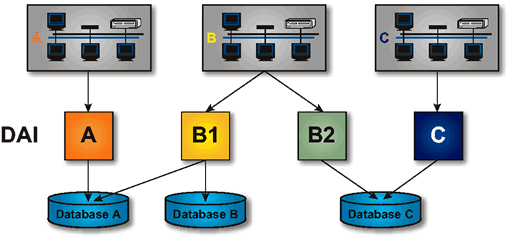
The DAI enables a very flexible architecture. Multiple raw capabilities can access the same or different data stores all through the same DAI. Each DAI might be implemented in many ways, according to the specific needs of the raw capabilities using it. Multiple Uses of a Data Access Interface (DAI) illustrates a number of possibilities, including multiple different DAIs in different domains accessing the same database, a single DAI accessing multiple databases, and multiple instantiations of the same DAI access the same database.
It is not always clear that a DAI is needed, and it appears to require additional work during all phases of development. However, should a database ever be redesigned, or if an application is to be re-used and there is no control over how the new data is implemented, using a DAI saves time in the long run.
The ISO Reference Model for Open Distributed Processing (RM-ODP) offers a meta-standard that is intended to allow more specific standards to emerge. The RM-ODP Reference Model defines a set of distribution transparencies that are applicable to the TOGAF software engineering view.
|
Transparency |
Definition |
|---|---|
|
Access |
Masks differences in data representation and invocation mechanisms to enable interworking between objects. This transparency solves many of the problems of interworking between heterogeneous systems, and will generally be provided by default. |
|
Failure |
Masks from an object the failure and possible recovery of other objects (or itself) to enable fault tolerance. When this transparency is provided, the designer can work in an idealized world in which the corresponding class of failures does not occur. |
|
Location |
Masks the use of information about location in space when identifying and binding to interfaces. This transparency provides a logical view of naming, independent of actual physical location. |
|
Migration |
Masks from an object the ability of a system to change the location of that object. Migration is often used to achieve load balancing and reduce latency. |
|
Relocation |
Masks relocation of an interface from other interfaces bound to it. Relocation allows system operation to continue even when migration or replacement of some objects creates temporary inconsistencies in the view seen by their users. |
|
Replication |
Masks the use of a group of mutually behaviorally compatible objects to support an interface. Replication is often used to enhance performance and availability. |
|
Transaction |
Masks coordination of activities amongst a configuration of objects to achieve consistency. |
The Infrastructure Bus represents the middleware that establishes the client/server relationship. This commercial software is like a backplane onto which capabilities can be plugged. A system should adhere to a commercial implementation of a middleware standard. This is to ensure that capabilities using different commercial implementations of the standard can interoperate. If more than one commercial standard is used (e.g., COM and CORBA), then the system should allow for interoperability between implementations of these standards via the use of commercial bridging software.9 Wherever practical, the interfaces should be specified in the appropriate Interface Description Language (IDL). Taken this way, every interface in the five-tier scheme represents an opportunity for distribution.
Clients can interact with servers via the Infrastructure Bus. In this interaction, the actual network transport (TCP/IP, HTTP, etc.), the platform/vendor of the server, and the operating system of the server are all transparent.
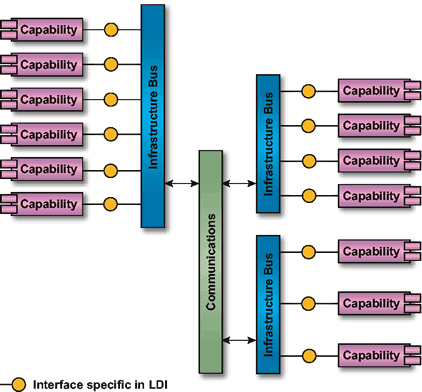
The software engineering view gives guidance on how to structure software in a very flexible manner. By following these guidelines, the resulting software will be componentized. This enables the re-use of components in different environments. Moreover, through the use of an infrastructure bus and clean interfaces, the resulting software will be location-independent, enabling its distribution across a network.
The system engineering view is concerned with assembling software and hardware components into a working system.
This view should be developed for the systems engineering personnel of the system, and should focus on how the system is implemented from the perspective of hardware/software and networking.
Systems engineers are typically concerned with location, modifiability, re-usability, and availability of all components of the system. The system engineering view presents a number of different ways in which software and hardware components can be assembled into a working system. To a great extent the choice of model determines the properties of the final system. It looks at technology which already exists in the organization, and what is available currently or in the near future. This reveals areas where new technology can contribute to the function or efficiency of the new architecture, and how different types of processing platform can support different parts of the overall system.
Major concerns for this view are understanding the system requirements. In general these stakeholders are concerned with assuring that the appropriate components are developed and deployed within the system in an optimal manner.
Developing this view assists in the selection of the best configurations for the system.
This view of the architecture focuses on computing models that are appropriate for a distributed computing environment. To support the migration of legacy systems, this section also presents models that are appropriate for a centralized environment. The definitions of many of the computing models (e.g., host-based, master/slave, and three-tiered) historically preceded the definition of the client/server model, which attempts to be a general-purpose model. In most cases the models have not been redefined in the computing literature in terms of contrasts with the client/server model. Therefore, some of the distinctions of features are not always clean. In general, however, the models are distinguished by the allocation of functions for an information system application to various components (e.g., terminals, computer platforms). These functions that make up an information system application are presentation, application function, and data management.
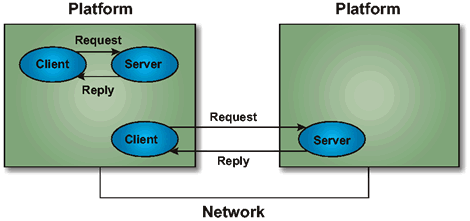
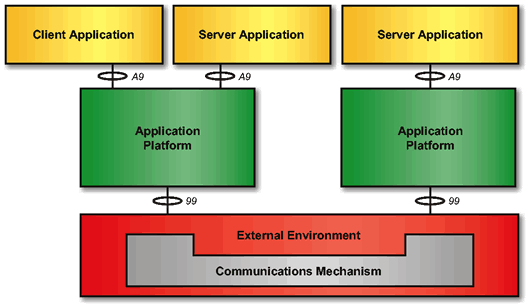
Client/server processing is a special type of distributed computing termed co-operative processing because the clients and servers co-operate in the processing of a total application (presentation, functional processing, data management). In the model, clients are processes that request services, and servers are processes that provide services. Clients and servers can be located on the same processor, different multi-processor nodes, or on separate processors at remote locations. The client typically initiates communications with the server. The server typically does not initiate a request with a client. A server may support many clients and may act as a client to another server. Basic Client/Server Model depicts a basic client/server model, which emphasizes the request-reply relationships. Reference Model Representation of Client/Server Model shows the same model drawn following the TOGAF Technical Reference Model (TRM), showing how the various entities and interfaces can be used to support a client/server model, whether the server is local or remote to the client. In these representations, the request-reply relationships would be defined in the API.
Clients tend to be generalized and can run on one of many nodes. Servers tend to be specialized and run on a few nodes. Clients are typically implemented as a call to a routine. Servers are typically implemented as a continuous process waiting for service requests (from clients). Many client/server implementations involve remote communications across a network. However, nothing in the client/server model dictates remote communications, and the physical location of clients is usually transparent to the server. The communication between a client and a server may involve a local communication between two independent processes on the same machine.
An application program can be considered to consist of three parts:
In general, each of these can be assigned to either a client or server application, making appropriate use of platform services. This assignment defines a specific client/server configuration.
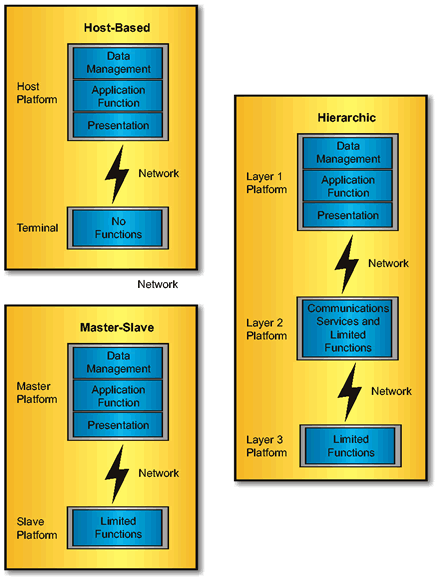
In this model, slave computers are attached to a master computer. In terms of distribution, the master/slave model is one step up from the host-based model. Distribution is provided in one direction - from the master to the slaves. The slave computers perform application processing only when directed to by the master computer. In addition, slave processors can perform limited local processing, such as editing, function key processing, and field validation. A typical configuration might be a mainframe as the master with PCs as the slaves acting as intelligent terminals, as illustrated in Host-Based, Master/Slave, and Hierarchic Models .
The hierarchic model is an extension of the master/slave model with more distribution capabilities. In this approach, the top layer is usually a powerful mainframe, which acts as a server to the second tier. The second layer consists of LAN servers and clients to the first layer as well as servers to the third layer. The third layer consists of PCs and workstations. This model has been described as adding true distributed processing to the master/slave model. Host-Based, Master/Slave, and Hierarchic Models shows an example hierarchic model in the third configuration, and below, Hierarchic Model using the Reference Model shows the hierarchic model represented in terms of the entities and interfaces of the TRM.
In the peer-to-peer model there are co-ordinating processes. All of the computers are servers in that they can receive requests for services and respond to them; and all of the computers are clients in that they can send requests for services to other computers. In current implementations, there are often redundant functions on the participating platforms.
Attempts have been made to implement the model for distributed heterogeneous (or federated) database systems. This model could be considered a special case of the client/server model, in which all platforms are both servers and clients. Peer-to-Peer and Distributed Object Management Models (A) shows an example peer-to-peer configuration in which all platforms have complete functions.
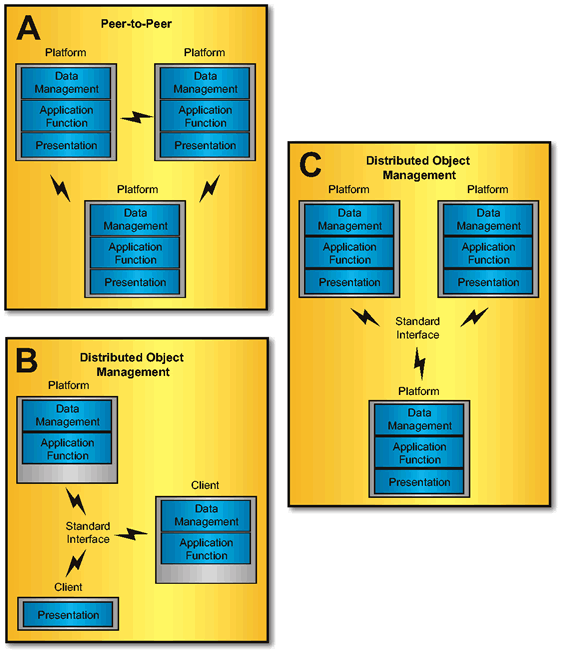
In this model the remote procedure calls typically used for communication in the client/server and other distributed processing models are replaced by messages sent to objects. The services provided by systems on a network are treated as objects. A requester need not know the details of how the object is configured. The approach requires:
This approach does not contrast with client/server or peer-to-peer models but specifies a consistent interface for communicating between co-operating platforms. It is considered by some as an implementation approach for client/server and peer-to-peer models. Peer-to-Peer and Distributed Object Management Models presents two distributed object model examples. Example B shows how a client/server configuration would be altered to accommodate the distributed object management model. Example C shows how a peer-to-peer model would be altered to accomplish distributed object management.
The Object Management Group (OMG), a consortium of industry participants working toward object standards, has developed an architecture - the Common Object Request Broker Architecture (CORBA) - which specifies the protocol a client application must use to communicate with an Object Request Broker (ORB), which provides services. The ORB specifies how objects can transparently make requests and receive responses. In addition, Microsoft's Object Linking and Embedding (OLE) standard for Windows is an example of an implementation of distributed object management, whereby any OLE-compatible application can work with data from any other OLE-compatible application.
The communications engineering view is concerned with structuring communications and networking elements to simplify network planning and design.
This view should be developed for the communications engineering personnel of the system, and should focus on how the system is implemented from the perspective of the communications engineer.
Communications engineers are typically concerned with location, modifiability, re-usability, and availability of communications and networking services. Major concerns for this view are understanding the network and communications requirements. In general these stakeholders are concerned with assuring that the appropriate communications and networking services are developed and deployed within the system in an optimal manner.
Developing this view assists in the selection of the best model of communications for the system.
Communications networks are constructed of end devices (e.g., printers), processing nodes, communication nodes (switching elements), and the linking media that connect them. The communications network provides the means by which information is exchanged. Forms of information include data, imagery, voice, and video. Because automated information systems accept and process information using digital data formats rather than analogue formats, the TOGAF communications concepts and guidance will focus on digital networks and digital services. Integrated multimedia services are included.
The communications engineering view describes the communications architecture with respect to geography, discusses the Open Systems Interconnection (OSI) reference model, and describes a general framework intended to permit effective system analysis and planning.
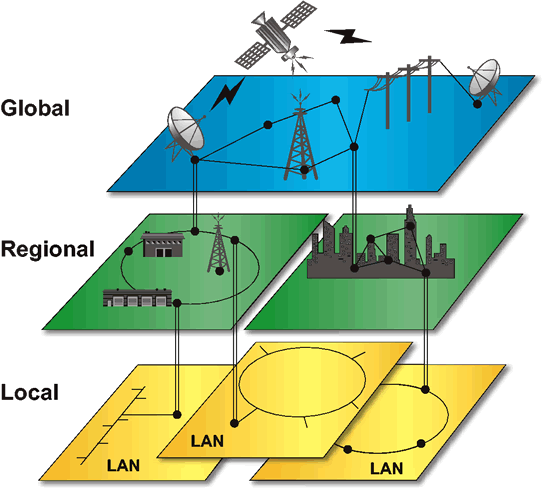
The Communications Infrastructure may contain up to three levels of transport - local, regional/metropolitan, and global, as shown in Communications Infrastructure . The names of the transport components are based on their respective geographic extent, but there is also a hierarchical relationship among them. The transport components correspond to a network management structure in which management and control of network resources are distributed across the different levels.
The local components relate to assets that are located relatively close together geographically. This component contains fixed communications equipment and small units of mobile communications equipment. LANs, to which the majority of end devices will be connected, are included in this component. Standard interfaces will facilitate portability, flexibility, and interoperability of LANs and end devices.
Regional and Metropolitan Area Networks (MANs) are geographically dispersed over a large area. A regional or metropolitan network could connect local components at several fixed bases or connect separate remote outposts. In most cases, regional and metropolitan networks are used to connect local networks. However, shared databases, regional processing platforms, and network management centers may connect directly or through a LAN. Standard interfaces will be provided to connect local networks and end devices.
Global or Wide Area Networks (WANs) are located throughout the world, providing connectivity for regional and metropolitan networks in the fixed and deployed environment. In addition, mobile units, shared databases, and central processing centers can connect directly to the global network as required. Standard interfaces will be provided to connect regional and metropolitan networks and end devices.
The geographically divided infrastructure described above forms the foundation for an overall communications framework. These geographic divisions permit the separate application of different management responsibilities, planning efforts, operational functions, and enabling technologies to be applied within each area. Hardware and software components and services fitted to the framework form the complete model.
The following sections describe the OSI Reference Model and a grouping of the OSI layers that facilitates discussion of interoperability issues.
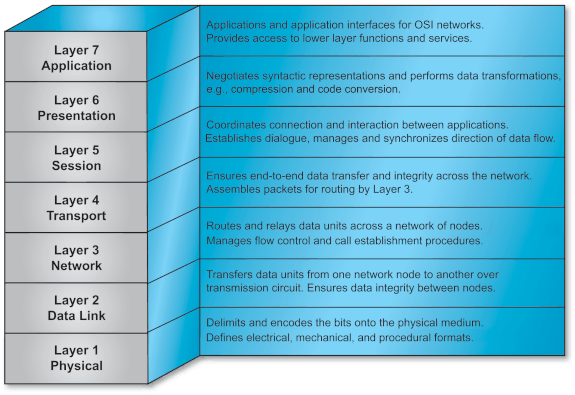
The Open Systems Interconnection (OSI) Reference Model, portrayed in OSI Reference Model , is the model used for data communications in TOGAF. Each of the seven layers in the model represents one or more services or protocols (a set of rules governing communications between systems), which define the functional operation of the communications between user and network elements. Each layer (with the exception of the top layer) provides services for the layer above it. This model aims at establishing open systems operation and implies standards-based implementation. It strives to permit different systems to accomplish complete interoperability and quality of operation throughout the network.
The seven layers of the OSI model are structured to facilitate independent development within each layer and to provide for changes independent of other layers. Stable international standard protocols in conformance with the OSI Reference Model layer definitions have been published by various standards organizations. This is not to say that the only protocols which fit into TOGAF are OSI protocols. Other protocol standards such as SNA or TCP/IP can be described using the OSI seven layer model as a reference.
Support and business area applications, as defined in TOGAF, are above the OSI Reference Model protocol stack and use its services via the applications layer.
A communications system based on the OSI Reference Model includes services in all the relevant layers, the support and business area application software which sits above the application layer of the OSI Reference Model, and the physical equipment carrying the data. These elements may be grouped into architectural levels that represent major functional capabilities, such as switching and routing, data transfer, and the performance of applications.
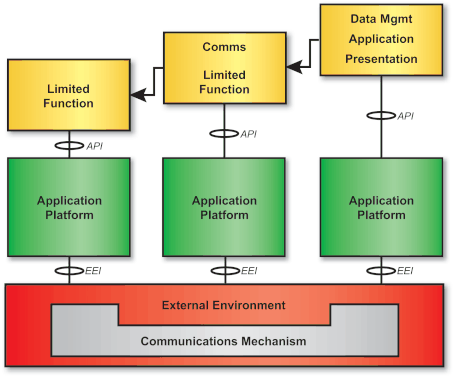
These architectural levels are:
In the TRM, OSI application layer services are considered to be part of the Application Platform entity, since they offer standardized interfaces to the application programming entity.
The communications framework is defined to consist of the three geographical components of the Communications Infrastructure (local, regional, and global) and the four architectural levels (Transmission, Network Switching, Data Exchange, and Applications Program), and is depicted in Communications Framework . Communications services are performed at one or more of these architectural levels within the geographical components. Communications Framework shows computing elements (operating at the Applications Program level) with supporting Data Exchange elements, linked with each other through various switching elements (operating at the Network Switching level), each located within its respective geographical component. Communications Framework also identifies the relationship of TOGAF to the communication architecture.
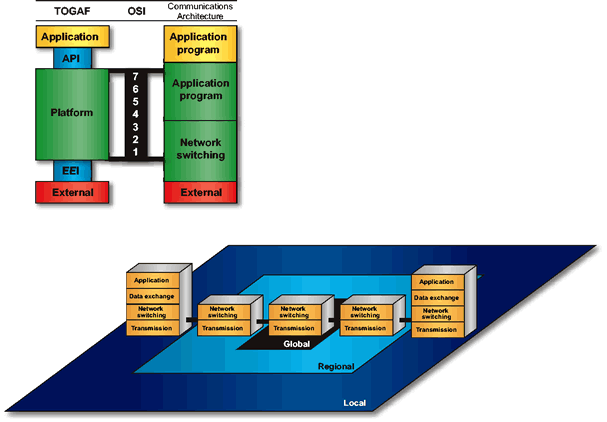
The Communications Infrastructure consists of the local, regional, and global transport components. The services allocated to these components are identical to the services of the Application Program, Data Exchange, Network Switching, or Transmission architectural levels that apply to a component. Data Exchange and Network Switching level services are identical to the services of the corresponding OSI Reference Model layers. Typically, only Network Switching and Transmission services are allocated to the regional and global components, which consist of communications nodes and transmission media. All services may be performed in the local component, which includes end devices, processing nodes, communications nodes, and linking media. Transmission, switching, transport, and applications are all performed in this component.
The data flow view is concerned with storage, retrieval, processing, archiving, and security of data.
This view should be developed for database engineers of the system.
Major concerns for this view are understanding how to provide data to the right people and applications with the right interfaces at the right time. This view deals with the architecture of the storage, retrieval, processing, archiving, and security of data. It looks at the flow of data as it is stored and processed, and at what components will be required to support and manage both storage and processing. In general these stakeholders are concerned with assuring ubiquitous access to high quality data.
The subjects of the general architecture of a "database system" are database components or components that provide database services.
The modeling of a "database" is typically done with entity-relationship diagrams and schema definitions, including document type definitions.
Data management services may be provided by a wide range of implementations. Some examples are:
Data management services include the storage, retrieval, manipulation, backup, restart/recovery, security, and associated functions for text, numeric data, and complex data such as documents, graphics, images, audio, and video. The operating system provides file management services, but they are considered here because many legacy databases exist as one or more files without the services provided by a DBMS.
Major components that provide data management services that are discussed in this section are:
These are critical aspects of data management for the following reasons. The DBMS is the most critical component of any data management capability, and a data dictionary/directory system is necessary in conjunction with the DBMS as a tool to aid the administration of the database. Data security is a necessary part of any overall policy for security in information processing.
A Database Management System (DBMS) provides for the systematic management of data. This data management component provides services and capabilities for defining the data, structuring the data, accessing the data, as well as security and recovery of the data. A DBMS performs the following functions:
A DBMS must provide:
The logical data model that underlies the database characterizes a DBMS. The common logical data models are as follows:
A Relational Database Management System (RDBMS) structures data into tables that have certain properties:
A collection of related tables in the relational model makes up a database. The mathematical theory of relations underlies the relational model - both the organization of data and the languages that manipulate the data. Edgar Codd, then at IBM, developed the relational model in 1973. It has been popular, in terms of commercial use, since the early 1980s.
The hierarchical data model organizes data in a tree structure. There is a hierarchy of parent and child data segments. This structure implies that a record can have repeating information, generally in the child data segments. For example, an organization might store information about an employee, such as name, employee number, department, salary. The organization might also store information about an employee's children, such as name and date of birth. The employee and children data forms a hierarchy, where the employee data represents the parent segment and the children data represents the child segment. If an employee has three children, then there would be three child segments associated with one employee segment. In a hierarchical database the parent-child relationship is one-to-many. This restricts a child segment to having only one parent segment. Hierarchical DBMSs were popular from the late 1960s, with the introduction of IBM's Information Management System (IMS) DBMS, through the 1970s.
The popularity of the network data model coincided with the popularity of the hierarchical data model. Some data was more naturally modeled with more than one parent per child. So, the network model permitted the modeling of many-to-many relationships in data. In 1971, the Conference on Data Systems Languages (CODASYL) formally defined the network model. The basic data modeling construct in the network model is the set construct. A set consists of an owner record type, a set name, and a member record type. A member record type can have that role in more than one set, hence the multi-parent concept is supported. An owner record type can also be a member or owner in another set. The CODASYL network model is based on mathematical set theory.
An Object-Oriented Database Management System (OODBMS) must be both a DBMS and an object-oriented system. As a DBMS it must provide the capabilities identified above. OODBMSs typically can model tabular data, complex data, hierarchical data, and networks of data. The following are important features of an object-oriented system:
A flat file system is usually closely associated with a storage access method. An example is IBM's Indexed Sequential Access Method (ISAM). The models discussed earlier in this section are logical data models; flat files require the user to work with the physical layout of the data on a storage device. For example, the user must know the exact location of a data item in a record. In addition, flat files do not provide all of the services of a DBMS, such as naming of data, elimination of redundancy, and concurrency control. Further, there is no independence of the data and the application program. The application program must know the physical layout of the data.
A distributed DBMS manages a database that is spread over more than one platform. The database can be based on any of the data models discussed above (except the flat file). The database can be replicated, partitioned, or a combination of both. A replicated database is one in which full or partial copies of the database exist on the different platforms. A partitioned database is one in which part of the database is on one platform and parts are on other platforms. The partitioning of a database can be vertical or horizontal. A vertical partitioning puts some fields and the associated data on one platform and some fields and the associated data on another platform. For example, consider a database with the following fields: employee ID, employee name, department, number of dependents, project assigned, salary rate, tax rate. One vertical partitioning might place employee ID, number of dependents, salary rate, and tax rate on one platform and employee name, department, and project assigned on another platform. A horizontal partitioning might keep all the fields on all the platforms but distribute the records. For example, a database with 100,000 records might put the first 50,000 records on one platform and the second 50,000 records on a second platform.
Whether the distributed database is replicated or partitioned, a single DBMS manages the database. There is a single schema (description of the data in a database in terms of a data model; e.g., relational) for a distributed database. The distribution of the database is generally transparent to the user. The term "distributed DBMS" implies homogeneity.
A distributed, heterogeneous database system is a set of independent databases, each with its own DBMS, presented to users as a single database and system. "Federated" is used synonymously with "distributed heterogeneous". The heterogeneity refers to differences in data models (e.g., network and relational), DBMSs from different suppliers, different hardware platforms, or other differences. The simplest kinds of federated database systems are commonly called gateways. In a gateway, one vendor (e.g., Oracle) provides single-direction access through its DBMS to another database managed by a different vendor's DBMS (e.g., IBM's DB2). The two DBMSs need not share the same data model. For example, many RDBMS vendors provide gateways to hierarchical and network DBMSs.
There are federated database systems both on the market and in research that provide more general access to diverse DBMSs. These systems generally provide a schema integration component to integrate the schemas of the diverse databases and present them to the users as a single database, a query management component to distribute queries to the different DBMSs in the federation, and a transaction management component, to distribute and manage the changes to the various databases in the federation.
The second component providing data management services, the Data Dictionary/Directory System (DD/DS), consists of utilities and systems necessary to catalog, document, manage, and use metadata (data about data). An example of metadata is the following definition: a six-character long alphanumeric string, for which the first character is a letter of the alphabet and each of the remaining five characters is an integer between 0 and 9; the name for the string is "employee ID" . The DD/DS utilities make use of special files that contain the database schema. (A schema, using metadata, defines the content and structure of a database.) This schema is represented by a set of tables resulting from the compilation of Data Definition Language (DDL) statements. The DD/DS is normally provided as part of a DBMS but is sometimes available from alternate sources. In the management of distributed data, distribution information may also be maintained in the network directory system. In this case, the interface between the DD/DS and the network directory system would be through the API of the network services component on the platform.
In current environments, data dictionaries are usually integrated with the DBMS, and directory systems are typically limited to a single platform. Network directories are used to expand the DD/DS realms. The relationship between the DD/DS and the network directory is an intricate combination of physical and logical sources of data.
Data administration properly addresses the Data Architecture, which is outside the scope of TOGAF. We discuss it briefly here because of areas of overlap. It is concerned with all of the data resources of an enterprise, and as such there are overlaps with data management, which addresses data in databases. Two specific areas of overlap are the repository and database administration, which are discussed briefly below.
A repository is a system that manages all of the data of an enterprise, which includes data and process models and other enterprise information. Hence, the data in a repository is much more extensive than that in a DD/DS, which generally defines only the data making up a database.
Data administration and database administration are complementary processes. Data administration is responsible for data, data structure, and integration of data and processes. Database administration, on the other hand, includes the physical design, development, implementation, security, and maintenance of the physical databases. Database administration is responsible for managing and enforcing the enterprise's policies related to individual databases.
The third component providing data management services is data security. This includes procedures and technology measures implemented to prevent unauthorized access, modification, use, and dissemination of data stored or processed by a computer system. Data security also includes data integrity (i.e., preserving the accuracy and validity of the data), and protecting the system from physical harm (including preventative measures and recovery procedures).
Authorization control allows only authorized users to have access to the database at the appropriate level. Guidelines and procedures can be established for accountability, levels of control, and type of control. Authorization control for database systems differs from that in traditional file systems because, in a database system, it is not uncommon for different users to have different rights to the same data. This requirement encompasses the ability to specify subsets of data and to distinguish between groups of users. In addition, decentralized control of authorizations is of particular importance for distributed systems.
Data protection is necessary to prevent unauthorized users from understanding the content of the database. Data encryption, as one of the primary methods for protecting data, is useful for both information stored on disk and for information exchanged on a network.
The enterprise manageability view is concerned with operations, administration, and management of the system.
This view should be developed for the operations, administration, and management personnel of the system.
Major concerns for these stakeholders are understanding how the system is managed as a whole, and how all components of the system are managed. The key concern is managing change in the system and predicting necessary preventative maintenance.
In general these stakeholders are concerned with assuring that the availability of the system does not suffer when changes occur. Managing the system includes managing components such as:
Business scenarios are an extremely useful way to depict what should happen when planned and unplanned events occur. It is highly recommended that business scenarios be created for planned change, and for unplanned change.
The following paragraphs describe some of the key issues that the architect might consider when constructing business scenarios.
The enterprise manageability view acts as a check and balance on the difficulties and day-to-day running costs of systems built within the new architecture. Often, system management is not considered until after all the important purchasing and development decisions have been taken, and taking a separate management view at an early stage in architecture development is one way to avoid this pitfall. It is good practice to develop the enterprise manageability view with close consideration of the system engineering view, since in general management is difficult to retrofit into an existing design.
Key elements of the enterprise manageability view are:
Key technical components categories that are the subject of the enterprise manageability view deal with change, either planned upgrades, or unplanned outages. The following table lists specific concerns for each component category.
|
Component Category |
Planned Change Considerations |
Unplanned Change Considerations |
|---|---|---|
|
Security Components |
How is a security change propagated throughout the system? Who is responsible for making changes; end users, or security stewards? |
What should happen when security is breached? What should happen if a security component fails? |
|
Data Assets |
How are new data elements added? How is data imported/exported or loaded/unloaded? How is backup managed while running continuously? How is data change propagated in a distributed environment? |
What are the backup procedures and are all the system capabilities there to backup in time? |
|
Software Assets |
How is a new application introduced into the systems? What procedures are there to control software quality? How are application changes propagated in a distributed environment? How is unwanted software introduction restricted given the Internet? |
What do you want to happen when an application fails? What do you want to happen when a resource of the application fails? |
|
Hardware Assets |
How do you assess the impact of new hardware on the system, especially network load? |
What do you want to happen when hardware outages occur? |
|
Networking Assets |
How do you assess the impact of new networking components? How do you optimize your networking components? |
|
The acquirer's view is concerned with acquiring Commercial Off-The-Shelf (COTS) software and hardware.
This view should be developed for personnel involved in the acquisition of any components of the subject architecture.
Major concerns for these stakeholders are understanding what building blocks of the architecture can be bought, and what constraints (or rules) exist that are relevant to the purchase. The acquirer will shop with multiple vendors looking for the best cost solution while adhering to the constraints (or rules) applied by the architecture, such as standards.
The key concern is to make purchasing decisions that fit the architecture, and thereby to reduce the risk of added costs arising from non-compliant components.
The acquirer's view is normally represented as an architecture of Solution Building Blocks (SBBs), supplemented by views of the standards to be adhered to by individual building blocks.
The acquirer typically executes a process similar to the one below. Within the step descriptions we can see the concerns and issues that the acquirer faces.
|
Procurement Process Steps |
Step Description and Output |
|---|---|
|
Acquisition Planning |
Creates the plan for the purchase of some component. For IT systems the following considerations are germane to building blocks. This step requires access to Architecture Building Blocks (ABBs) and Solution Building Blocks (SBBs).
|
|
Concept Exploration |
In this step the procurer looks at the viability of the concept. Building blocks give the planner a sense of the risk involved; if many ABBs or SBBs exist that match the concept, the risk is lower. This step requires access to ABBs and SBBs. The planner needs to know what ABBs apply constraints (standards), and needs to know what candidate SBBs adhere to these standards. |
|
Concept Demonstration |
In this step, the procurer works with development to prototype an implementation. The procurer recommends the re-usable SBBs based upon standards fit, and past experience with suppliers. This step requires access to re-usable SBBs. |
|
Development |
In this step the procurer works with development to manage the relationship with the vendors supplying the SBBs. Building blocks that are proven to be fit-for-purpose get marked as approved. This step requires an update of the status to "procurement approved" of an SBB. |
|
Production |
In this step, the procurer works with development to manage the relationship with the vendors supplying the SBBs. Building blocks that are put into production get marked appropriately. This step requires an update of the status to "in production" of SBBs, with the system identifier of where the building block is being developed. |
|
Deployment |
In this step, the procurer works with development to manage the relationship with the vendors supplying the SBBs. Building blocks that are fully deployed get marked appropriately. This step requires an update of the status to "deployed" of SBBs, with the system identifier of where the building block was deployed. |
The TOGAF document set is designed for use with frames. To navigate around the document:
Downloads of the TOGAF documentation, are available under license from the TOGAF information web site. The license is free to any organization wishing to use TOGAF entirely for internal purposes (for example, to develop an information system architecture for use within that organization). A hardcopy book is also available from The Open Group Bookstore as document G063.