| You are here: | ||
| <<< Previous | Home | Next >>> |
The Enterprise Continuum provides methods for classifying architecture and solution artifacts, both internal and external to the Architecture Repository, as they evolve from generic Foundation Architectures to Organization-Specific Architectures.
The Enterprise Continuum enables the architect to articulate the broad perspective of what, why, and how the Enterprise Architecture has been designed with the factors and drivers considered. The Enterprise Continuum is an important aid to communication and understanding, both within individual enterprises, and between customer enterprises and vendor organizations. Without an understanding of "where in the continuum you are", people discussing architecture can often talk at cross-purposes because they are referencing different points in the continuum at the same time, without realizing it.
Any architecture is context-specific; for example, there are architectures that are specific to individual customers, industries, subsystems, products, and services. Architects, on both the buy side and supply side, must have at their disposal a consistent language to effectively communicate the differences between architectures. Such a language will enable engineering efficiency and the effective leveraging of Commercial Off-The-Shelf (COTS) product functionality. The Enterprise Continuum provides that consistent language.
The Enterprise Continuum enables the organization of re-usable architecture artifacts and solution assets to maximize the Enterprise Architecture investment opportunities.
The simplest way of thinking of the Enterprise Continuum is as a view of the repository of all the architecture assets. It can contain Architecture Descriptions, models, building blocks, patterns, architecture viewpoints, and other artifacts - that exist both within the enterprise and in the IT industry at large, which the enterprise considers to have available for the development of architectures for the enterprise.
Examples of internal architecture and solution artifacts are the deliverables of previous architecture work, which are available for re-use. Examples of external architecture and solution artifacts are the wide variety of industry reference models and architecture patterns that exist, and are continually emerging, including those that are highly generic (such as the TOGAF TRM); those specific to certain aspects of IT (such as a web services architecture, or a generic manageability architecture); those specific to certain types of information processing, such as e-Commerce, supply chain management, etc.; and those specific to certain vertical industries, such as the models generated by vertical consortia like the TM Forum (in the Telecommunications sector), ARTS (Retail), Energistics (Petrotechnical), etc.
The Enterprise Architecture determines which architecture and solution artifacts an organization includes in its Architecture Repository. Re-use is a major consideration in this decision.
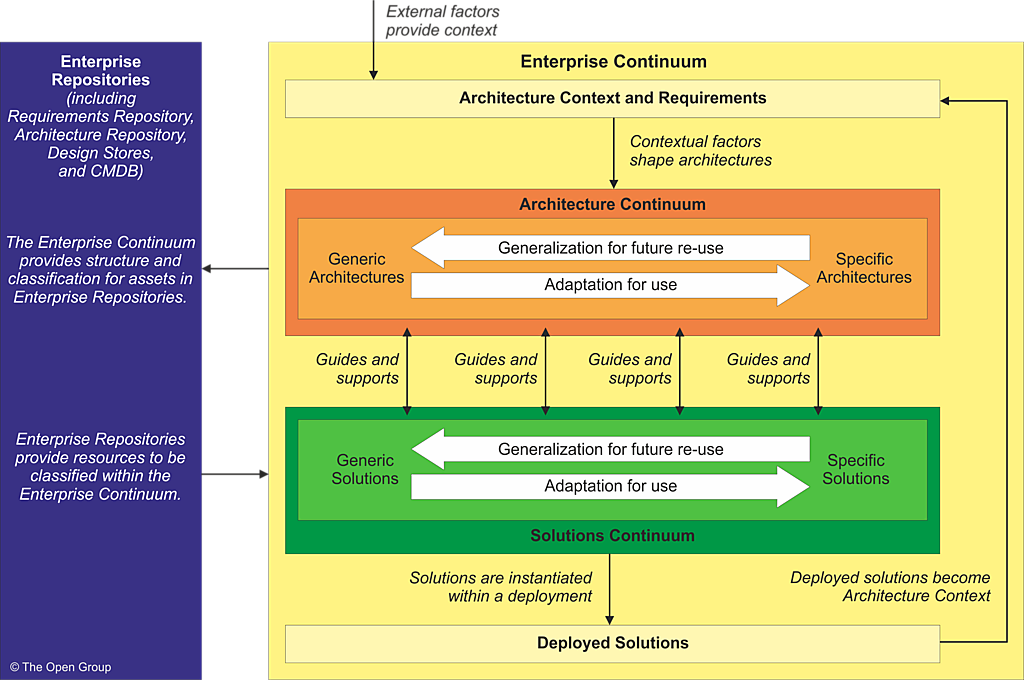
An overview of the context and constituents of the Enterprise Continuum is shown in Figure 35-1 .
The Enterprise Continuum is partitioned into three distinct continua as follows:
The Enterprise Continuum classes of assets may influence architectures, but are not directly used during the ADM architecture development. The Enterprise Continuum classifies contextual assets used to develop architectures, such as policies, standards, strategic initiatives, organizational structures, and enterprise-level capabilities. The Enterprise Continuum can also classify solutions (as opposed to descriptions or specifications of solutions). Finally, the Enterprise Continuum contains two specializations, namely the Architecture and Solutions Continua.
The Architecture Continuum represents a structuring of Architecture Building Blocks (ABBs) which are re-usable architecture assets. ABBs evolve through their development lifecycle from abstract and generic entities to fully expressed Organization-Specific Architecture assets. The Architecture Continuum assets will be used to guide and select the elements in the Solutions Continuum (see below). The Architecture Continuum shows the relationships among foundational frameworks (such as the TOGAF framework), common system architectures (such as the III-RM), industry architectures, and Enterprise Architectures. The Architecture Continuum is a useful tool to discover commonality and eliminate unnecessary redundancy.
The Solutions Continuum defines what is available in the organizational environment as re-usable Solution Building Blocks (SBBs). The solutions are the results of agreements between customers and business partners that implement the rules and relationships defined in the architecture space. The Solutions Continuum addresses the commonalities and differences among the products, systems, and services of implemented systems.
The Enterprise Continuum classifies architecture assets that are applicable across the entire scope of the Enterprise Architecture. These assets, which may be referred to as building blocks, can represent a variety of elements that collectively define and constrain the Enterprise Architecture. They can take the form of business goals and objectives, strategic initiatives, capabilities, policies, standards, and principles.
The Enterprise Continuum also contains the Architecture Continuum and the Solutions Continuum. Each of these continua is described in greater detail in the following sections.
The Enterprise Continuum is intended to represent the classification of all assets that are available to an enterprise. It classifies assets that exist within the enterprise along with other assets in the wider environment that are relevant to the enterprise, such as products, research, market factors, commercial factors, business strategies, and legislation.
The TOGAF standard is intended to be a framework for conducting Enterprise Architecture and as a result many of the assets that reside within the Enterprise Continuum are beyond the specific consideration of the TOGAF framework. However, architectures are fundamentally shaped by concerns outside the practice of architecture and it is therefore of paramount importance that any architecture must accurately reflect external context.
The specific contextual factors to be identified and incorporated in an architecture will vary from architecture to architecture. However, typical contextual factors for architecture development are likely to include:
By observing the context for architecture, it can be seen that architecture development activity exists within a wider enterprise lifecycle of continuous change.
ABBs are defined in relation to a set of contextual factors and then realized through SBBs. SBBs are deployed as live solutions and become a part of the baseline operating model of the enterprise. The operating model of the enterprise and empiric information on the performance of the enterprise shapes the context and requirements for future change. Finally, these new requirements for change create a feedback loop to influence the creation of new Target Architectures.
The Architecture Continuum illustrates how architectures are developed and evolved across a continuum ranging from Foundation Architectures, such as the TOGAF® Series Guide: The TOGAF® Technical Reference Model (TRM), through Common Systems Architectures, and Industry Architectures, and to an enterprise's own Organization-Specific Architectures.
The arrows in the Architecture Continuum represent the relationship that exists between the different architectures in the Architecture Continuum. The leftwards direction focuses on meeting enterprise needs and business requirements, while the rightwards direction focuses on leveraging architectural components and building blocks.
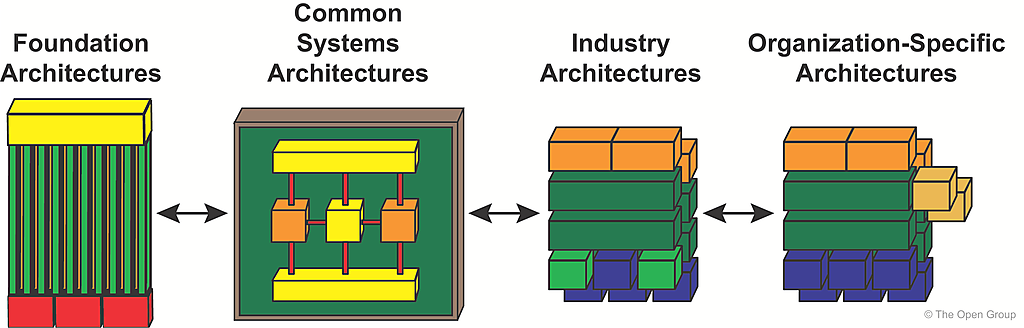
The enterprise needs and business requirements are addressed in increasing detail from left to right. The architect will typically look to find re-usable architectural elements toward the left of the continuum. When elements are not found, the requirements for the missing elements are passed to the left of the continuum for incorporation. Those implementing architectures within their own organizations can use the same continuum models specialized for their business.
The four particular architecture types illustrated in Figure 35-2 are intended to indicate the range of different types of architecture that may be developed at different points in the continuum; they are not fixed stages in a process.
Many different types of architecture may occur at points in between those illustrated in Figure 35-2 . Although the evolutionary transformation continuum illustrated does not represent a formal process, it does represent a progression, which occurs at several levels:
At each point in the continuum, an architecture is designed in terms of the design concepts and building blocks available and relevant to that point.
The four architectures illustrated in Figure 35-2 represent main classifications of potential architectures, and will be relevant and familiar to many architects. They are analyzed in detail below.
A Foundation Architecture consists of generic components, inter-relationships, principles, and guidelines that provide a foundation on which more specific architectures can be built. The TOGAF ADM is a process that would support specialization of such Foundation Architectures in order to create organization-specific models.
The TOGAF TRM is an example of a Foundation Architecture. It is a fundamental architecture upon which other, more specific architectures can be based. See the TOGAF® Series Guide: The TOGAF® Technical Reference Model (TRM) for more details.
Common Systems Architectures guide the selection and integration of specific services from the Foundation Architecture to create an architecture useful for building common (i.e., highly re-usable) solutions across a wide number of relevant domains.
Examples of Common Systems Architectures include: a security architecture, a management architecture, a network architecture, an operations architecture, etc. Each is incomplete in terms of overall system functionality, but is complete in terms of a particular problem domain (security, manageability, networking, operations, etc.), so that solutions implementing the architecture constitute re-usable building blocks for the creation of functionally complete operating states of the enterprise.
Other characteristics of Common Systems Architectures include:
The TOGAF Integrated Information Infrastructure Reference Model (III-RM) - see the TOGAF® Series Guide: The TOGAF Integrated Information Infrastructure Reference Model (III-RM) - is a reference model that supports describing Common Systems Architecture in the Application Domain that focuses on the requirements, building blocks, and standards relating to the vision of Boundaryless Information Flow.
Industry Architectures guide the integration of common systems components with industry-specific components, and guide the creation of industry solutions for targeted customer problems within a particular industry.
A typical example of an industry-specific component is a data model representing the business functions and processes specific
to a particular vertical industry, such as the Retail industry's "Active Store" architecture, or an Industry Architecture that
incorporates the Energistics Data Model (refer to www.energistics.org).
Other characteristics of Industry Architectures include:
Organization-Specific Architectures describe and guide the final deployment of solution components for a particular enterprise or extended network of connected enterprises.
There may be a variety of Organization-Specific Architectures that are needed to effectively cover the organization's requirements by defining the architectures in increasing levels of detail. Alternatively, this might result in several more detailed Organization-Specific Architectures for specific entities within the global enterprise. Breaking down Organization-Specific Architectures into constituent pieces is addressed in 36. Architecture Partitioning .
The Organization-Specific Architecture guides the final customization of the solution, and has the following characteristics:
The Solutions Continuum represents the detailed specification and construction of the architectures at the corresponding levels of the Architecture Continuum. At each level, the Solutions Continuum is a population of the architecture with reference building blocks - either purchased products or built components - that represent a solution to the enterprise's business need expressed at that level. A populated repository based on the Solutions Continuum can be regarded as a solutions inventory or re-use library, which can add significant value to the task of managing and implementing improvements to the enterprise.
The Solutions Continuum is illustrated in Figure 35-3 .
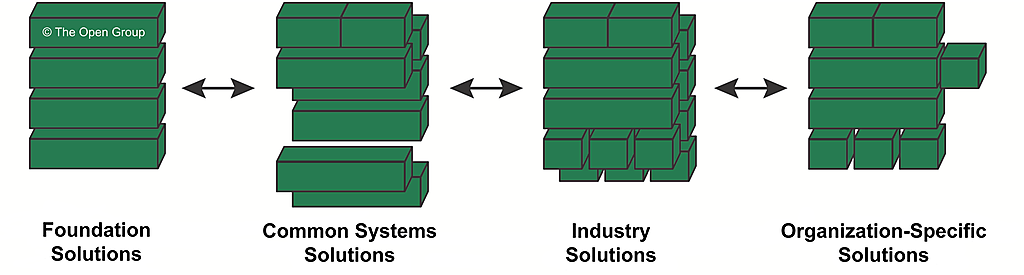
"Moving to the right" on the Solutions Continuum is focused on providing solutions value (i.e., foundation solutions provide value in creating common systems solutions; common systems solutions are used to create industry solutions; and industry solutions are used to create organization-specific solutions). "Moving to the left" on the Solutions Continuum is focused on addressing enterprise needs. These two viewpoints are significant for a company attempting to focus on its needs while maximizing the use of available resources through leverage.
The following subsections describe each of the solution types within the Solutions Continuum.
Foundation Solutions are highly generic concepts, tools, products, services, and solution components that are the fundamental providers of capabilities. Services include professional services - such as training and consulting services - that ensure the maximum investment value from solutions in the shortest possible time; and support services - such as Help Desk - that ensure the maximum possible value from solutions (services that ensure timely updates and upgrades to the products and systems).
Example Foundation Solutions would include programming languages, operating systems, foundational data structures (such as EDIFACT), generic approaches to organization structuring, foundational structures for organizing IT operations (such as ITIL or the IT4IT Reference Architecture), etc.
A Common Systems Solution is an implementation of a Common Systems Architecture comprised of a set of products and services, which may be certified or branded. It represents the highest common denominator for one or more solutions in the industry segments that the Common Systems Solution supports.
Common Systems Solutions represent collections of common requirements and capabilities, rather than those specific to a particular customer or industry. Common Systems Solutions provide organizations with operating environments specific to operational and informational needs, such as high availability transaction processing and scalable data warehousing systems. Examples of Common Systems Solutions include: an enterprise management system product or a security system product.
Computer systems vendors are the typical providers of technology-centric Common Systems Solutions. "Software as a service" vendors are typical providers of common application solutions. Business process outsourcing vendors are typical provides of business capability-centric Common Systems Solutions.
An Industry Solution is an implementation of an Industry Architecture, which provides re-usable packages of common components and services specific to an industry.
Fundamental components are provided by Common Systems Solutions and/or Foundation Solutions, and are augmented with industry-specific components. Examples include: a physical database schema or an industry-specific point-of-service device.
Industry Solutions are industry-specific, aggregate procurements that are ready to be tailored to an individual organization's requirements.
In some cases an industry solution may include not only an implementation of the Industry Architecture, but also other solution elements, such as specific products, services, and systems solutions that are appropriate to that industry.
An Organization-Specific Solution is an implementation of the Organization-Specific Architecture that provides the required business functions. Because solutions are designed for specific business operations, they contain the highest amount of unique content in order to accommodate the varying people and processes of specific organizations.
Building Organization-Specific Solutions on Industry Solutions, Common Systems Solutions, and Foundation Solutions is the primary purpose of connecting the Architecture Continuum to the Solutions Continuum, as guided by the architects within an enterprise.
An Organization-Specific Solution will be structured in order to support specific Service-Level Agreements (SLAs) to ensure support of the operational systems at desired service levels. For example, a third-party application hosting provider may offer different levels of support for operational systems. These agreements would define the terms and conditions of that support.
Other key factors to be defined within an Organization-Specific Solution are the key operating parameters and quality metrics that can be used to monitor and manage the environment.
The Enterprise Continuum can provide a key link between architecture, development, and operations personnel by allowing them to communicate and reach agreement on anticipated operational support requirements. Operations personnel can in turn access the Enterprise Continuum to obtain information regarding the operation concepts and service support requirements of the deployed system.
The TOGAF ADM describes the process of developing an enterprise-specific architecture and an enterprise-specific solution(s) which conform to that architecture by adopting and adapting (where appropriate) generic architectures and solutions (left to right in the continuum classification). In a similar fashion, specific architectures and solutions that prove to be credible and effective will be generalized for re-use (right to left in the continuum classification).
At relevant places throughout the TOGAF ADM, there are pointers to useful architecture assets at the relevant level of generality in the continuum classification. These assets can include reference models from The Open Group and industries at large.
The TOGAF Library provides reference models for consideration for use in developing an organization's architecture.
However, in developing architectures in the various domains within an overall Enterprise Architecture, the architect will need to consider the use and re-use of a wide variety of different architecture assets, and the Enterprise Continuum provides an approach for categorizing and communicating these different assets.
The preceding sections have described the Enterprise Continuum, the Architecture Continuum, and the Solutions Continuum. The following sections describe the relationships between each of the three continua and how these relationships should be applied within your organization.
Each of the three continua contains information about the evolution of the architectures during their lifecycle:
The relationships between the Architecture Continuum and Solutions Continuum are shown in Figure 35-4 .
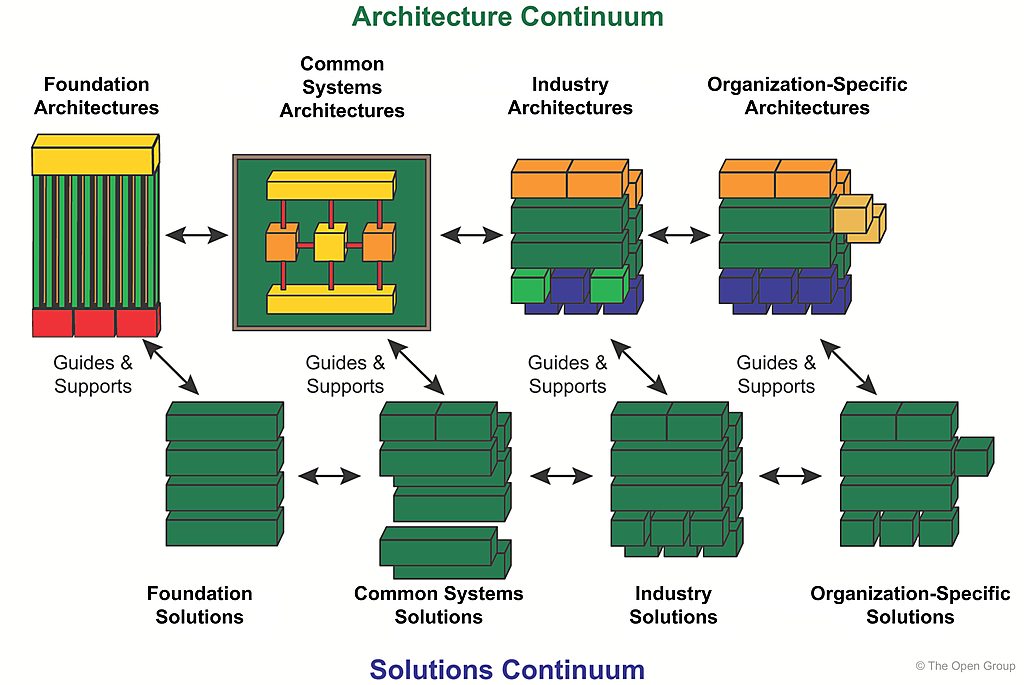
The relationship between the Architecture Continuum and the Solutions Continuum is one of guidance, direction, and support. For example, Foundation Architectures guide the creation or selection of Foundation Solutions. Foundation Solutions support the Foundation Architecture by helping to realize the architecture defined in the Architecture Continuum. The Foundation Architecture also guides development of Foundation Solutions, by providing architectural direction, requirements and principles that guide selection, and realization of appropriate solutions. A similar relationship exists between the other elements of the Enterprise Continuum.
The Enterprise Continuum presents mechanisms to help improve productivity through leverage. The Architecture Continuum offers a consistent way to understand the different architectures and their components. The Solutions Continuum offers a consistent way to understand the different products, systems, services, and solutions required.
The Enterprise Continuum should not be interpreted as representing strictly chained relationships. Organization-Specific Architectures could have components from a Common Systems Architecture, and Organization-Specific Solutions could contain Foundation Solutions. The relationships depicted in Figure 35-1 are an illustration showing opportunities for leveraging architecture and solution components.
The TOGAF standard provides a method for you to "architect" the systems in your enterprise. Your architecture organization will have to deal with each type of architecture described above. For example, it is recommended that you have your own Foundation Architecture that governs all of your systems. You should also have your own Common Systems Architectures that govern major shared systems - such as the networking system or management system. You may have your own industry-specific architectures that govern the way your systems must behave within your industry. Finally, any given department or organization within your business may need its own individual Organization-Specific Architecture to govern the systems within that department.
Your architecture organization will either adopt or adapt existing architectures, or will develop its own architectures from the
ground up. In either case, the TOGAF standard is a tool to help. It provides a method to assist you in generating/maintaining any
type of architecture within the Architecture Continuum while leveraging architecture assets already defined, internal or external
to your organization. The TOGAF ADM helps you to re-use architecture assets, making your architecture organization more efficient
and effective.
![]() return to top of page
return to top of page