The standard output is a text file (encoded in the
character set of the current locale)
that begins with the line:
"begin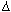 %s%s\n", <mode>,
decode_pathname
%s%s\n", <mode>,
decode_pathname
and ends with the line:
end\n
In both cases, the lines have no preceding or trailing
blank characters.
The algorithm that is used for lines in between
begin
and
end
takes three octets as input
and writes four characters of output by splitting the input at six-bit
intervals into four octets, containing data in the lower six bits only.
These octets are converted to characters by adding
a value of 0x20
to each octet, so that each octet
is in the range 0x20-0x5f, and then
it is assumed to
represent a printable character in the ISO/IEC 646:1991 standard
encoded character set.
It then will be translated into the corresponding
character codes for the codeset in use in the current locale.
(For example, the octet 0x41, representing
A,
would be translated to
A
in the current codeset, such as 0xc1 if it were EBCDIC.)
Where the bits of two octets are combined, the least significant bits of
the first octet are shifted left and combined with the most significant
bits of the second octet shifted right.
Thus the three octets A, B, C are converted into the four octets:
0x20 + (( A >> 2 ) & 0x3F)
0x20 + (((A << 4) ' |' ((B >> 4) & 0xF)) & 0x3F)
0x20 + (((B << 2) ' |' ((C >> 6) & 0x3)) & 0x3F)
0x20 + (( C ) & 0x3F)
These octets are then translated into the local character set.
Each encoded line contains a length character, equal to the number
of characters to be decoded plus 0x20 translated to the local
character set as described above, followed by the encoded
characters.
The maximum number of octets to be encoded on each line is 45.
The file is expanded by 35 percent
(each three octets become four, plus control information)
causing it to take longer to transmit.
Since this utility is intended to create files to
be used for data interchange between systems with possibly
different codesets,
and to represent binary data as a text file,
the ISO/IEC 646:1991 standard
was chosen for a midpoint in the algorithm as a known reference point.
The output from
uuencode
is a text file on the local system.
If the output were in the ISO/IEC 646:1991 standard
codeset, it might not be a text file (at least because the
newline characters
might not match), and the goal of creating a text file
would be defeated.
If this text file was then carried to another machine
with the same codeset, it would be perfectly compatible
with that system's
uudecode.
If it was transmitted over a mail system
or sent to a machine with a different codeset,
it is assumed that, as for every other text file, some translation mechanism
would convert it (by the time it reached a user on the other system) into an
appropriate codeset.
This translation only makes sense from the local
codeset, not if the file has been put into a ISO/IEC 646:1991 standard
representation first.
Similarly, files processed by
uuencode
can be placed in
pax
archives, intermixed with other text files in the same codeset.
The algorithm is described in terms of 8-bit quantities, or octets.
Since no byte alignment is implied, it will encode data from machines
with any number of bits per byte.
However, unless that encoded data is then decoded on a
machine with the same number of bits per byte,
the output might not be useful.