
This chapter presents an overview of aspects of the writing systems
of a large family of languages that are collectively called
complex-text languages.
Not all the languages of the world have these characteristics.
In this document, complex-text languages are defined as those languages for which the text has a different layout when presented from when it is stored for data processing. The term layout, which is equivalent, in this context, to the term format, refers to the shape of the characters and the direction of portions of the text.
An additional characteristic of complex-text languages (with the exception of Vietnamese) is the fact that they do not have upper-case or lower-case characters.
Typical complex-text languages are those with a
bidirectional script.
There is nothing in these languages themselves that is more complex than in the Latin-based languages; they are special only in that the presented text does not necessarily look identical to the text as stored.
Though the term complex is used to describe the text of the bidirectional and some other Asian languages, enabling a program to work in these languages is relatively simple, once the peculiarities of these languages are understood.
These transformations have to take into account specific text
attributes, including directionality, shaping, composition of
characters and national numbers.
Text attributes that describe bidirectional writing systems are defined in
An internationalised application must be designed to deal automatically with this kind of transformation and related attributes.
In a bidirectional language, the general flow of text proceeds horizontally from right to left, but numbers are written from left to right, the same way as they are written in English. In addition, if an English or another left-to-right language text (addresses, acronyms or quotations) is embedded, it is also written from left to right.
Arabic is a Semitic language that originated with the Arabs of the Hejaz and Nejd regions of Saudi Arabia. There are several spoken dialects of Arabic, but all are derived from the same root: the classical Arabic, which is taught at school in all Arab countries, and is used in all these countries for writing. The written form of the language has different levels of sophistication, depending on the use. These levels range from newspaper style to literary style, passing through technical, business and administration styles.

The following characters are added to the basic set, in a way similar to the accented characters in Latin-based languages:
In addition, two special characters (Aleph Wasla and superscripted Aleph) are sometimes used in language education and linguistics.
The Arabic alphabet is also the root from which several other alphabets, such as Farsi and Urdu, are derived. In addition to the characters of the Arabic alphabet, the Farsi and Urdu alphabets have a few more specific characters. Farsi adds four consonants to the Arabic alphabet, and Urdu adds eight.

In a text string, both the connection capabilities of a character and its neighbours, and its position in the word determine its actual presentation shape.
In countries using Arabic script, the decimal system is in use. In addition to the "Arabic" digits used in the Western world, national digit shapes, known as Hindi shapes, are in use. The equivalent of the Arabic digits 1, 2, 3, 4, 5, 6, 7, 8, 9 and 0 are:
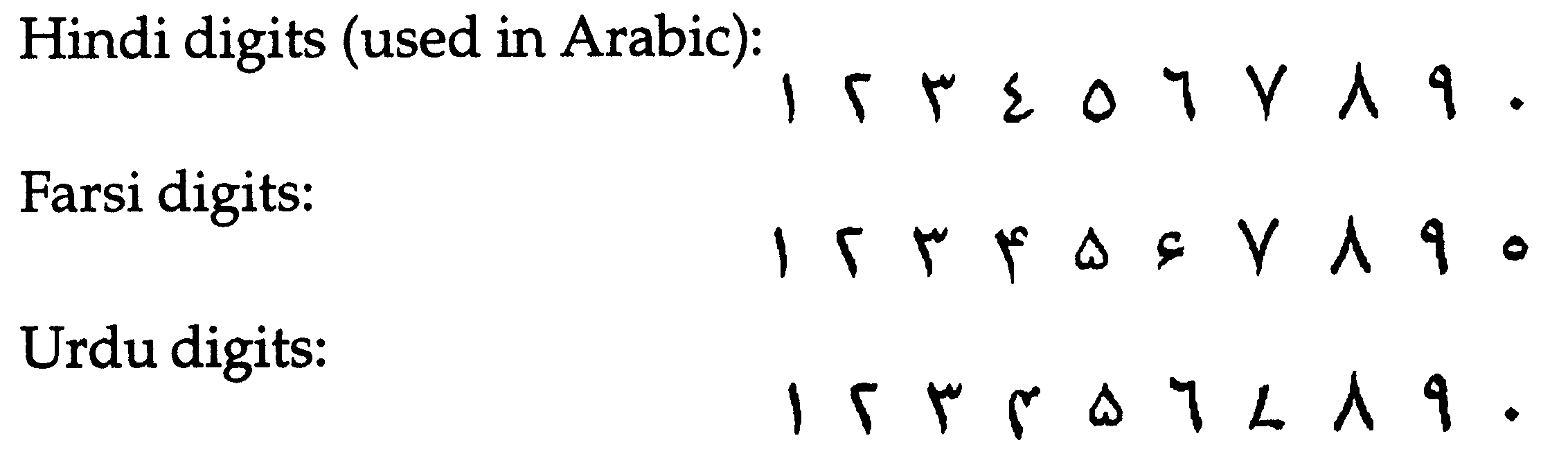

The Hebrew language dates back to biblical times. It remained relatively unchanged for about 2000 years until the end of the nineteenth century, when the birth of the modern Hebrew language took place. Since that time, the Academy of the Hebrew Language has extended traditional Hebrew to include Hebrew words for modern objects and concepts.
Hebrew is used mainly in Israel.

Vowels are represented in two ways:
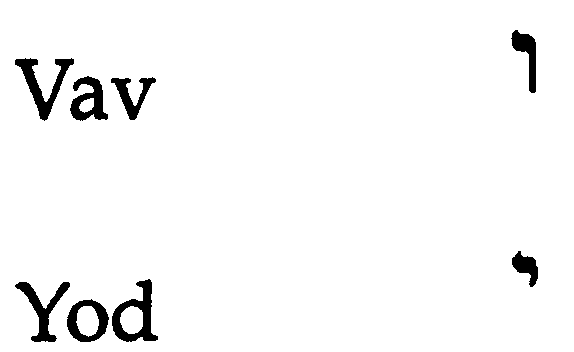
Written Hebrew has no equivalent to capital letters. Hebrew does not have a cursive script: the letters are not connected. Unlike Arabic, Hebrew letters do not take on different shapes depending on the surrounding letters. The five final shape letters are considered additional, separate letters of the alphabet.

This section discusses aspects of bidirectional texts,
related to directionality, shaping and
These attributes are described below.
A bidirectional text may consist of a main part that has one directionality (for example, an Arabic text written from right to left), and portions that have an opposite directionality (for example, an English address written from left to right.) The portion of text with a different directionality is called a segment. A bidirectional text thus might have a body bgcolor="#FFFFFF" of right-to-left text with embedded left-to right segments. Sometimes a segment with one directionality might itself have embedded or nested within it an additional segment with an opposite directionality. It is conceptually possible to have many levels of nesting; in most cases, however, there are no more than two levels.
One level of nesting is necessary for the entry of numbers within Arabic or Hebrew text. To simulate bidirectional scripts in the following examples, Hebrew and Arabic text is represented by lower-case English letters, while English text is represented by upper-case letters.
In Hebrew, it is customary to write the name of the street
before the number of the house,
as shown below:
The street name is entered from right to left. The flow then has to be
reversed to allow correct entry of the number from left to right (this being
the nested left-to-right segment.)
Then the flow must be reversed again to allow the entry of the entrance
information from right to left.
b ecnartne 25 teerts elpam
<--------- -> <-----------
Imagine somebody bgcolor="#FFFFFF" writing a letter in English to somebody who
can read Hebrew too, and writing
his or her address in Hebrew.
In this case, the address in Hebrew is actually a
nested segment of the English text.
Because the nested segment of the address has itself a nested segment
(the street number), there are two levels of nesting.
MY ADDRESS IS b ecnartne 25 teerts elpam THIS MONTH.
------------><--------- -> <----------- --------->
NEST LEVEL: 0000000000000011111111111221111111111111000000000000
Bidirectional text may consist of mainly
right-to-left text with some left-to-right nested segments
(such as an Arabic text with some information in English), or
mainly left-to-right with some right-to-left segments
(such as an English letter with a Hebrew address nested within it).
The predominant direction is called the global orientation;
it cannot always be quickly deduced from the general context.
This sentence has one meaning when the reading is from
left to right (Fred does not believe I always say that), and
another meaning when read from
right to left (I always say that Fred does not believe).
In the first half of the above example,
the global orientation
of the text is left-to-right and in the second half
it is right-to-left.
FRED DOES NOT BELIEVE taht yas syawla i
Because the global orientation is not always obvious from the context2
it must be known to the application developer
whose product is processing the bidirectional data.
There are different approaches to how bidirectional
text is to be reordered, and at present none
can be said to be prevalent.
The concept text-type is used to point to which approach
is applicable for a specific text.
The physical and logical order and the different text-types are
discussed further below.
The global orientation is left-to-right. The first letter in the
text is M, followed by Y and so forth.
In the physical order,
after the letters I and S comes the letter i of the segment
containing my wife's name in Hebrew. Note, however, that my wife's
name is pronounced "nili". In the logical order
the first letter of the name segment is thus the letter n, followed
by i, l and i.
MY WIFE'S NAME IS ilin
Sometimes, for example in on-line help, it is convenient to store the bidirectional text exactly as presented - that is, in the physical order. But if there is an intent to process the text (for example, to sort it), the segments must be stored in their logical order. There is no meaning, in the above example, to sort the name "ilin". It makes sense to reorder the text, so the directional segment containing the name "nili" is inverted, before being stored for further processing. The logical order is the preferred sequence for entering text and for processing. Conceptually, any storage device can be seen as storing the data from left to right. If a programmer wants to perform straightforward processing on the stored text (sorting, collating, indexing) without the need to preprocess each segment, the bidirectional data has to be stored in its logical sequence. This means reversing segments whose direction is opposite to the global orientation.
Different text-types require different approaches to reordering:
Thus, a text with visual text-type is stored in its physical order, and a text with an implicit text-type is stored in its logical order, which is better suited for automatic processing. A text with an explicit text-type is usually stored in logical order, but because of the embedded controls in the text, the automatic processing is not always straightforward.
There is no one type of text that can be used in all cases. The implicit techniques are usually heuristic and thus have some limitations as noted previously. The explicit techniques, while alleviating the limitations of implicit techniques, introduce other limitations such as the need for automatic processes to cope with embedded controls.
One specific technique, the Basic Display Algorithm,4 tries to be a bridge between the implicit and explicit techniques. In principle it is an implicit reordering algorithm, but it can deal with a few specific directional controls embedded in the text.
There are applications and related databases for all three text-types. It is possible for bidirectional text that is presented one way to be stored in a different layout. A programmer need only know what text-type or reordering algorithm was used, to correctly transform or process the bidirectional text.
Some characters, such as the greater-than sign, have an implied directional meaning and have a complementary symmetric character with an opposite directional meaning (the less-than sign). When used within a segment that is presented right-to-left but is inverted (left-to-right) when stored for processing, such a character might have to be replaced by its symmetric sibling to ensure that the correct meaning of the text is preserved. The replacement of such a character by its complement during transformation of a bidirectional text is called symmetrical swapping.
b < a
is read as a is greater than b.
In storage the orientation is always left-to-right; the first character
in storage is thus a, followed by <
and then b.
So the result in storage is:
a < b
which is of course incorrect.
In this case, to preserve the correct meaning of the expression,
the < character must be exchanged in storage with >.
Other graphic characters that require symmetrical swapping include the parentheses, square brackets, braces, and so on.
Although symmetrical swapping is a characteristic of bidirectional languages, it is not always mandatory for the software functions that transform different bidirectional-language text layouts. Sometimes this function is performed automatically by the workstation hardware or microcode.
Shaping is the process by which characters are rendered in the appropriate presentation forms. This might involve the presentation of characters in a form different from the one in which they are stored. In general, to simplify processing, an unshaped (abstract or basic) representation is used internally. Shaping takes into account the character being shaped and the characters in its vicinity, and replaces its abstract representation (or that of its parts) with the proper shape. Shaping is a characteristic of many complex text languages, in particular the languages of the Middle East.
The Arabic scripts are cursive. A writing system is cursive if it is suited to handwriting rather than printing, with adjacent characters in a word connected to each other. Some letters can only connect to the letter on their right. This is the only way in which Arabic script is used, whether in books, newspapers, signs, or workstation displays. (English can be handwritten in a cursive style, for personal communications, but is seldom published or displayed that way. Thus English is not considered a cursive script.)
The proper shape can be selected by a shape determination routine, which allows for automatic (algorithmic) selection of the appropriate shape according to the context as directed by the software or the user. It may allow for user or software controlled selection of any of the four shapes mentioned above. Alternatively, it may allow transparent throughput of data: that is, it may become temporarily deactivated under software or user control. Whenever cursive-language characters are folded by processing to one shape, they must be reshaped using the same algorithm prior to presentation. In some very specific cases, data may be corrupted by this processing, as the algorithm may not be perfectly reversible. As an analogy, in English, converting 12Ab2 to upper case would result in 12AB2; the return to lower case would result in 12ab2, which is not the same as the original.
Though in most cases a cursive language text would be stored in basic shapes only, there are cases where it may be stored with characters shaped as presented, as in the case of messages or on-line help text.
As a compromise, given existing limitations (in the graphical capabilities and resolution of the display devices and the number of code points available), bidirectional languages such as Hebrew have in many implementations given up the ability to represent vowels by diacritics. The vowels sounds have to be surmised by readers based on their knowledge of the language and according to the semantics of the text.
However this guesswork is not acceptable for specific applications, such as poetry or processing of a classical text, which requires the use of diacritics. In some complex-text languages, such as Thai, the use of vowel symbols and tone marks is mandatory.
In Arabic, spacing diacritics are currently used as a compromise. In the present Arabic systems, some or all of the Arabic diacritics are implemented as separate characters to be rendered following the character to which the diacritics belong.
It is important to understand that in most cases, the text stored for processing has numbers encoded in their Arabic (western) code. When it comes to presentation, these numbers might be presented using either national glyphs for digits or ordinary Arabic digits, according to the intent of the user or application developer.
There are two typing interfaces to consider:
The manual method also supports an Automatic Push (Auto Push) mode. When the Auto Push setting is active, the Push Mode is started and terminated automatically, according to the actual characters being typed.
When the manual typing method is active, the keyboard language group and cursor direction are handled separately by the system. This means that the user has separate control for:
With this method, the system automatically determines how to display characters in the correct order when the user switches keyboard language groups.
Another feature of this method is that it handles text in typing order; that is, the system remembers the order in which the characters were initially typed. It then uses this knowledge along with a set of predefined rules, to determine how the text is displayed, processed and deleted by the application.
If the cursor is in the Home position (the first logical position in the field or window) and a character of a language other than the default language of the current orientation is entered, the screen or window orientation is reversed automatically. That is, if the character entered is Hebrew, the window orientation is right-to-left; if the character is English, the window orientation is left-to-right.
The Thai writing system was developed from the Devanagari system, which originated in India and came to Thailand from Cambodia. A major difference between the Chinese and Thai writing systems is that while Chinese makes use of a large number of pictorial symbols, Thai uses an alphabet of consonants, vowels, tone marks, diacritics and special symbols. With some exceptions, a Thai word can be pronounced correctly on sight, in a similar manner to Italian or French.

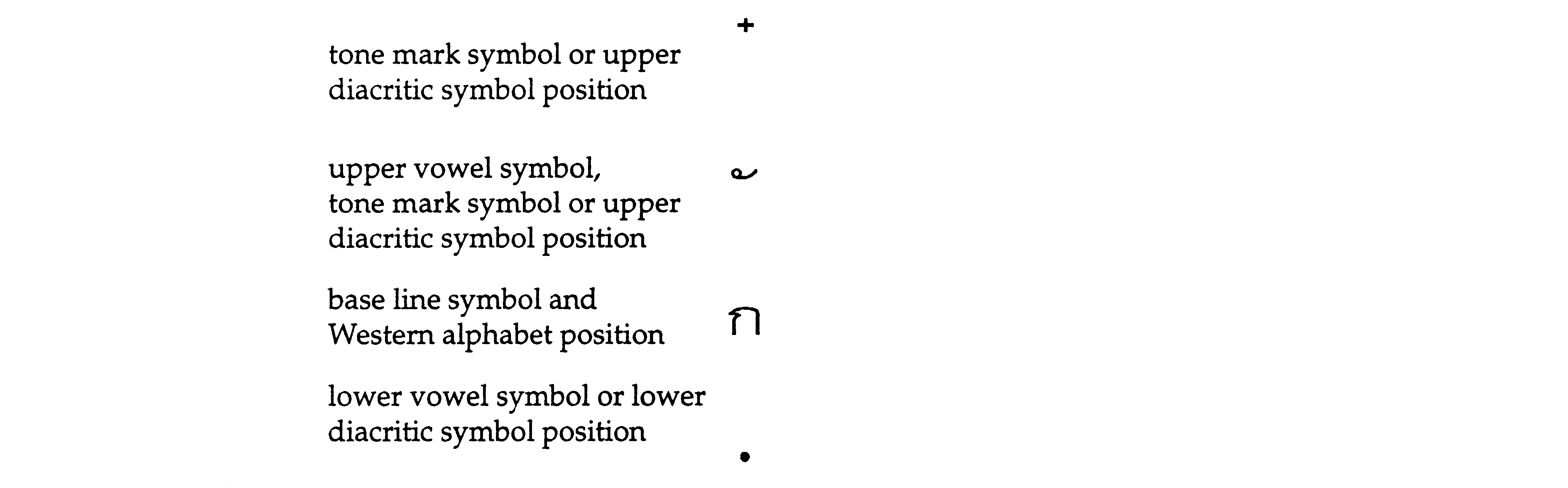
A line of Thai text can be considered to be logically divided into four parallel lines:
Generally speaking, the more than 2,000 characters in the Thai writing system can be categorised into 20 types of written symbols, with 88 basic symbols:
Normally, Thai data is encoded using a single-byte code page, where each symbol has an adequate code point. The symbols are used to enter Thai data on a Thai keyboard. Thus the Thai data is stored, for processing purposes, as symbol elements. These elements have to be combined into characters for rendering purposes.
In the most common writing order, first a base line symbol is written, and then optionally, an upper vowel or lower vowel symbol is written above or below it. A tone mark symbol may then optionally be written either above the base line symbol, or above the upper vowel symbol, if present.
This order of writing is taught in Thai elementary schools. However, writing-order inconsistencies exist between individuals. The valid combinations of symbols for Thai composed characters are:
Any other combinations would be considered invalid.
From a linguistic or phonetic point of view, the Thai writing system is actually more complex than that described above. Consonants are written on the base line. A middle vowel can be written either before, after or straddling the related consonant. Upper-vowels are written above, and lower vowels below, their related consonant. Vowels are always pronounced and collated after the consonant. The tone mark is usually written after the upper vowel or lower vowel, but some people might write it after the consonant. The left and right pieces of a middle vowel, which straddle a consonant, are included as separate components in some encoding schemes.
To prevent confusion, the term composed character is used here for the representation of one syllable at a writing position, and the term symbol is used for the components of a composed character.
Although Western numerals (Arabic numbers) are now widely used in Thai writing, there are also ten Thai glyphs for numbers. In Thai, the equivalent of the Arabic digits 1, 2, 3, 4, 5, 6, 7, 8, 9 and 0 are respectively:
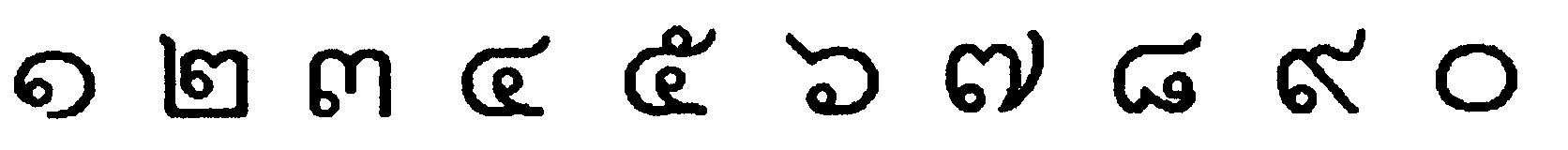
According to the rules for writing Thai, only certain combinations of symbols are possible. When someone fluent in Thai is writing or reading a line, a process of composition is taking place. In about 74 percent of cases a character is formed from a single symbol; in about 22 percent of cases, it is formed from two symbols; and in 4 percent of cases it is formed from three symbols.
A Thai speaker does not think of a composed character as, for example, an accented character in French. This difference in thinking is reflected in the difference between European and Thai keyboards. In European keyboards, dead keys are used to place accents on characters. The dead key is pressed first to show the accent, and then the character key is pressed. The cursor moves only after the character has been entered. All character manipulation is done at the cursor position.
In Thai the consonant or middle vowel is entered first. It is displayed, and the cursor then moves one position to the right. The upper and lower (dead key) vowels and tone marks are then added to the character to the left of the cursor. The rightmost column of positions on the screen is used to display the cursor only, and data is not allowed in this column. Usually vowels and tone marks are stacked on the consonants to compose syllables. The exception is middle vowels, which stay independently at the same level as the consonants.
Quality font rendering (for example, for desktop publishing), requires additional changes to be made to a Thai composite character form, and sometimes to other characters in its vicinity.
It is thus possible to recognise a similarity between character composition in Thai, and ligatures composition and shaping in bidirectional languages. The character presented is not identical with the symbols stored, so a shaping or composing algorithm must be applied.
Similarly, there are cases where the shaping transformation must not to be performed at rendering, but at a previous stage. When using the high-quality printers adapted for double-byte character set (DBCS), a shaping of characters (maximum three-symbol), is performed as part of the transformation of text to a double-byte encoding scheme. In this case, the text can be considered stored in a shaped form for higher-efficiency printing. This resembles the case in which Arabic message text is kept in storage in a shaped layout.
The official writing system of Korean is known as
Hangul, which means "the Korean letter" in Korean. It was created
Hanja, which means "Chinese letter", is a term sometimes used to describe the ideograms used to express words borrowed from Chinese. Likewise, the English alphabet is used to express some English terminology. Nevertheless, contemporary Koreans regard Hangul as the writing system for the Korean language, and as such the Korean writing system is not ideographic.
Korean script uses Arabic figures to represent numbers in most cases. The pronunciation of figures can be expressed using either Hangul or Hanja.
These cluster elements are called Jamo in Korean, where Ja means consonant and mo means vowel.
In standard Hangul, there are 24 basic Jamo elements, of which 14 are used for consonants. In the case of sounds that are not representable by the basic Jamo elements, Hangul grammar allows them to be represented by combining two or more elements. About 27 additional Jamo elements, of which 16 are used for consonants, belong to such combined Jamo elements.
There are 19 permissible initial consonants, 21 vowels and 28 final consonants. The total number of possible combinations of Hangul Consonant-Vowel-Consonant (CVC) is thus 11,172 (19x21x28). Everyday Korean, however, makes do with approximately 2,500 combinations.
The major graphic distinction in Hangul is between vowels and consonants. Vowels are based on long horizontal or vertical lines that have distinguishing marks. The basic vowel Jamo elements are as follows:

Consonants are represented by more compact, two-dimensional signs; the basic consonant Jamo elements are as follows:

The shapes of the consonants were apparently chosen by King Sejong to represent highly stylised pictures of the tongue and mouth when the equivalent sounds are pronounced. For example, the Hangul sign:
In Korean, words are made up of syllables, and the words are separated by spaces. There are two ways in which syllables are juxtaposed to create words and text: vertically (top to bottom and right to left) and horizontally (left to right and top to bottom.)
In South Korea, although newspapers are printed from top to bottom in vertical columns that shift from right to left, horizontal writing is very much in use. The script is Hangul, with occasional Chinese (Hanja) characters as well as Latin-based characters for English text.
In North Korea, newspapers are printed horizontally with Korean script (Hangul only, without Hanja characters).
If, hypothetically, English were written like Hangul, and the vowel
O belonged to the set of vowels written under the initial
consonant while the vowels A and E were written to the right of the
initial consonant, then an English term such as common market
would be presented in the following manner:
Horizontal direction:
C M M A K E
O O R T
M N
Vertical direction of writing:
C
O
M
M
O
N
M A
R
K E
T
The following figure shows actual Hangul Jamo elements and their corresponding composition. The right-most column is an example of vertical writing; the bottom line is an example of horizontal writing.

Korean uses two character sets:
Application developers should be aware of the fact that in the complex-text languages there is a need for transformations between the different text layouts. They should allow for user or system exits to facilitate invoking these transformations, in those places where a transformation might be expected (at input, before output, before a collating process, and so on). Programs must be able to identify the location and content of the complex-text attributes, and be able to change their content if needed.
Just as for any other language, an application meant to be used for complex-text languages should utilise the appropriate language code page and cultural data (date and time layout, collating sequence, monetary layout, and so on).
Application developers should design their products in such a way that they use, as much as possible, the standard functions and controls provided by the operating system services or toolkits for these languages. They might choose to use the APIs offered in the national language versions of the operating system services or toolkits to perform such transformations (when available).
It would be good practice to concentrate all the functions related to National Language in a specific program area for easy maintainability and change support.
| Contents | Next section | Index |