This chapter provides a general description of the programming model implemented by the RPC Application Programming Interface (API). This description includes definitions of many of the concepts used throughout the RPC API manual pages. As such, it is a necessary prerequisite to the understanding of the manual pages, and the manual pages assume knowledge of this chapter, even when they do not make explicit reference to it.
The description serves three purposes:
The general information covers topics, such as binding and name service usage, that are relevant to many of the manual pages. Typically, several routines perform tasks related to a given topic. This introduction provides a general model within which the tasks performed by individual routines and suites of routines can be understood. This general model also provides a rationale for the set of routines included in this document. It describes the underlying operations required for RPC programming and shows how the set of RPC APIs included in this document gives access to these operations.
In showing how the RPC API routines are meant to be used, this chapter provides certain guidelines for consistent RPC client/server interface usage. These guidelines cover such areas as using the naming services and organising server resources. By following them, programmers can simplify the task of maintaining and enhancing server interfaces and writing client programs.
The RPC programming model can be viewed along two axes:
Each view describes important aspects of the use of the RPC API.
The client/server view of RPC programming describes the distributed resource model implemented by the RPC mechanism. In this view, programming tasks are divided between servers, which provide services or make resources available to remote clients, and clients, which seek and make use of these services or resources.
The central component of the client/server model is the interface.
An interface is a set of remotely callable operations
offered by a server and invokable by clients.
The RPC mechanism itself imposes few restrictions on the organisation
of operations into interfaces.
RPC does provide a means to specify interface versions and a protocol
to select a compatible interface version at bind time (see
The RPC paradigm makes remote calls an extension of the familiar local procedure call mechanism. Specifically, the call itself is made as a local procedure call, and the underlying RPC mechanism handles the remoteness transparently. Server interface programming is thus similar to local procedure call programming, except that the handler of the call runs in a separate address space and security domain.
From this point of view, a local procedure call is a special simple case of the more general call mechanism provided by RPC. RPC semantics extend local procedure call semantics in a variety of ways:
The RPC API provides programmers with the means to apply these extended semantics, but it shields applications from the rigours of transport level send-and-receive programming. The RPC programming paradigm gives the programmer control of the remote semantics at two points: in the interface specification and through the RPC API.
A remote procedure call requires a remote binding. The calling client must bind to a server that offers the interface it wants, and the client's local procedure call must invoke the correct manager operation on the bound-to server. Because the various parts of this process occur at run time, it becomes possible to exercise nearly total programmatic control of binding. The RPC API provides access to all aspects of the binding process.
Each binding consists a set of components that can be separately manipulated by applications, including protocol and addressing information, interface information and object information. This allows servers to establish many binding paths to their resources and allows clients to make binding choices based on all of the components. These capabilities are the basis for defining a variety of server resource models.
Servers need to make their resources widely available, and clients need some way to find them without knowing the details of network configuration and server installation. Hence, the RPC mechanism supports the use of name services, where servers can advertise their bindings and clients can find them, based on appropriate search criteria. The RPC API provides clients and servers with a variety of routines that can be used to export and import bindings to and from name services.
The client/server model views servers as exporters of services-via RPC interfaces-and clients as importers of those services. Exported services typically take the form of access to resources, such as computational procedures, data, communications facilities, hardware facilities, or any other capabilities available to an application on a networked host. The RPC mechanism does not distinguish among such resource types in any way. On the contrary, it provides a uniform means of access-the remote procedure call-and allows the programmer to define the underlying resource model freely.
RPC does, however, provide specific mechanisms that implicitly support different approaches to resource modeling. These mechanisms take advantage of the flexibility of the binding process and the name services. The RPC mechanism supports three basic resource models:
The RPC programming mechanism does not explicitly enforce these models. Instead, they are supported implicitly by making available a set of run-time binding and name service facilities through the RPC API. Programmers may use these facilities according to their application requirements. However, this document recommends that programs follow the models specified here in order to ensure consistent use of the client/server interface.
The RPC API provides access to a variety of security services: client-to-server and server-to-client authentication, authorisation of access to server resources (which may carry delegation information inserted by security routines), and varying degrees of cryptographic protection of client/server communications.
The client/server view of RPC is necessarily asymmetric. The model is based on providing services remotely via the export of RPC interfaces. Since servers are the means for implementing remote interfaces, the model is server-centred. The RPC architecture provides certain server facilities that make the implementation of servers more efficient. These include
The application/stub/run-time system view of RPC describes the division of labour between application code and other RPC components in implementing a remote procedure call.
At the core of this model is the RPC run-time system, which is a library of routines and a set of services that handle the network communications that underlie the RPC mechanism. In the course of an RPC call, client-side and server-side run-time systems' code handle binding, establish communications over an appropriate protocol, pass call data between the client and server, and handle communications errors.
The RPC API is the programmer's interface to the run-time system. The run-time system makes use of a number of services, such as the endpoint mapper, name services and security services. The RPC API also provides an interface to these services for carrying out RPC-specific operations. Portable usage of the RPC API is fully specified in this section of this document.
The stub is application-specific code, but it is not directly generated by the application writer and therefore appears as a separate layer from the programmer's point of view. The function of the stub is to provide transparency to the programmer-written application code. On the client side, the stub handles the interface between the client's local procedure call and the run-time system, marshaling and unmarshaling data, invoking the RPC run-time protocol, and if requested, carrying out some of the binding steps. On the server side, the stub provides a similar interface between the run-time system and the local manager procedures that are executed by the server.
RPC transparency to the application programmer is provided by the
interface specification mechanism.
The programmer specifies interfaces using an Interface Definition
Language (IDL), and
This chapter does not cover the interface specification mechanism
itself; this is documented in
RPC application code falls into two categories:
In the first category are the procedures written by the programmer to
implement the client and server operations of the remote procedure call.
On the client side, these are simply local calls to the stub
interfaces for the remote procedures.
On the server side, these are a set of manager routines that implement
the operations of the interface.
The programmer-written application code interacts with the RPC run-time system
principally through the stub.
This makes run-time operations largely transparent to the application
code.
Nevertheless, in order to control binding, security and other aspects
of the RPC mechanism, the application often needs direct access to
run-time operations.
The RPC API provides applications with such access to the RPC run-time system
and related services.
The RPC API provides access to an extensive set of run-time operations.
Subsequent sections of this chapter cover many of these groups of operations in detail.
Binding-related operations establish a relationship between a client and server that makes possible a remote procedure call. These operations may be roughly divided into two categories:
Operations in the first category include the creation of
communications endpoints by the server for the set of protocols over
which it wishes to receive remote procedure calls.
Servers typically export information about the bindings thus created
to a name service and an endpoint map.
Clients typically import such binding information from a name service
and an endpoint map (see
Operations in the second category establish a set of mappings that the server can use to route calls internally to the appropriate manager routine. This routing is based on the interface and version, operation and any object requested by the call.
The RPC name service API includes an extensive set of operations for exporting and importing binding information to and from name services. These operations make use of a set of RPC-specific name service entry attributes to structure the exported binding information so that it can easily be found and interpreted by clients.
Servers listen for remote procedure call requests over one or more
protocol-specific endpoints.
Typically, such endpoints are allocated dynamically when a server
begins to listen, and their lifetime is only a single server
instantiation.
RPC provides an endpoint mapper
Endpoint operations are used by servers to register their endpoints with the endpoint mapper.
These operations establish the authentication and authorisation services and protection levels used by remote procedure calls.
These operations are used by applications to implement character and code set interoperability, which permits clients and servers to transfer international character data in a heterogeneous character set and code sets environment.
These operations are used by applications to manage stub memory. They are typically used by RPC applications that pass pointer data.
Management operations include a variety of operations with the potential to affect applications other than the one making the management call. Servers automatically export a set of remote management functions.
UUIDs (Universal Unique Identifiers) are used frequently by the RPC
mechanism for a variety of purposes.
The UUID operations enable applications to manipulate UUIDs.
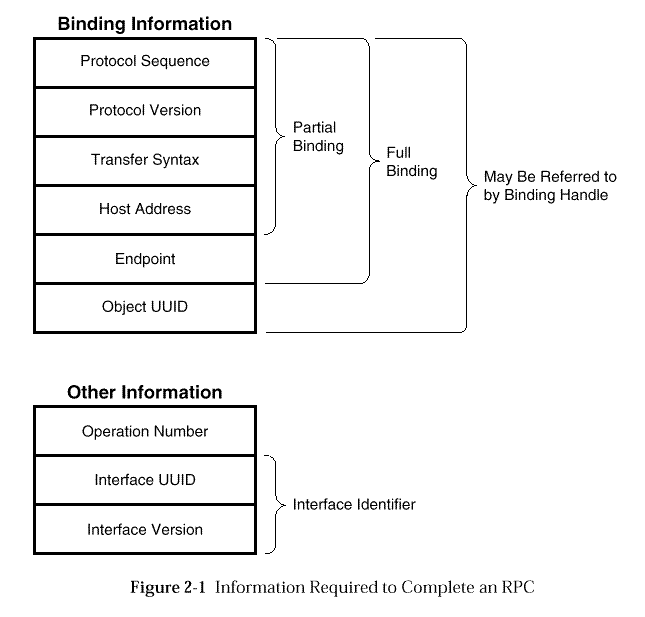
Binding refers to the establishment of a relationship between a client
and a server that permits the client to make a remote procedure call
to the server.
In this document, the term "binding" usually refers specifically to
a protocol relationship between a client and either the server host
or a specific endpoint on the server host, and "binding
information" means the set of protocol and addressing information
The binding information itself covers the first five elements of the list-the protocol and address information required for RPC communications to occur between a client and server.
In RPC terminology, such a binding can be partial or full.
A partial binding is one that contains the
The binding information required to make remote procedure calls is maintained by the client and server run-time systems on behalf of applications. The run-time system provides applications with opaque binding handles to refer to locally maintained binding information. Applications use binding handles to manipulate bindings via calls to the RPC API.
It is important to understand that binding handles are only valid in
the context of the local client or server instance that created them.
They are not used directly to communicate binding information between
servers and clients.
Typically, servers advertise binding information by exporting it
to name service entries.
When a client imports binding information from a name service, it
receives a binding handle from the client run-time system
that refers to the local copy of the imported binding information.
Binding information may refer either to a server or a client.
Most of the time, binding information refers to servers, since it
is servers to which clients need to bind in order to make remote
procedure calls.
When a binding refers to a server, a binding handle for it is
called a server binding handle.
Server binding handles are used both by clients and servers
in the course of the binding process.
In some cases, servers need binding information for clients that call them.
A binding handle that refers to such binding information is
called a client binding handle.
A small number of RPC APIs take client binding handles as arguments.
Applications obtain server binding handles by calling any of several
RPC API routines.
(See
A server obtains a client binding handle as the first argument passed
by the run-time system to a server manager routine.
A string binding is a string representation of binding
information, including an optional object UUID.
String bindings provide binding information in human-readable form.
Applications can use RPC API calls to request a string binding from
the run-time system or convert a string binding into a binding that the
runtime system can use to make a remote procedure call.
String binding format is specified in
In order to complete an RPC call, all of the elements listed in
RPC is close to the other dynamic extreme. It purposely avoids creating static links among all the elements so that a final routing-from the client procedure call to the server manager routine invoked-can be dynamically determined at the time of the RPC. From the programmer's point of view, one of the principal differences between a local procedure call and a remote procedure call is that the binding process-the way all these components are linked together-occurs at run time and can be carried out, optionally, under application program control.
This serves several purposes:
The binding process consists of a series of steps taken by the client and server to create, make available and assemble all the necessary information, followed by the actual RPC, which creates the final binding and routing using the elements established by the previous steps. To break the process down in more detail:
Each of the components listed in
The server takes a number of steps to establish binding state in the server side run-time system, the name service and the endpoint mapper. The server's basic task is to acquire a set of endpoints from the run time and set up a series of relationships among binding elements that will then be used to construct the final routing at call time.
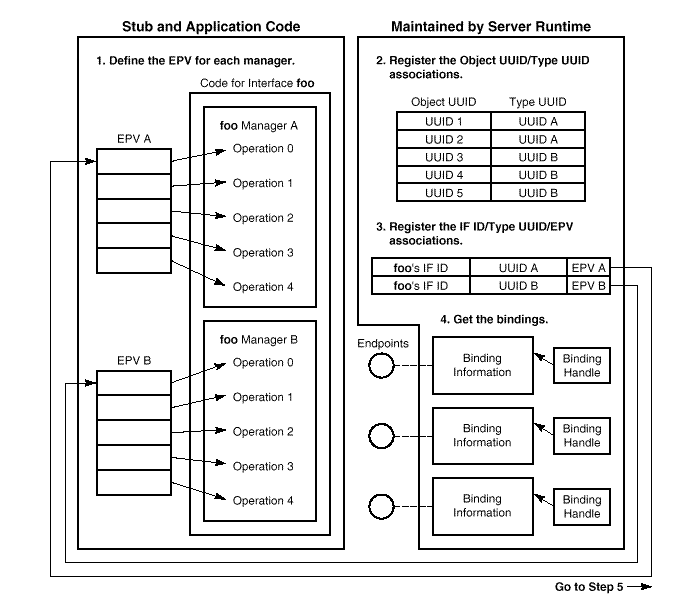
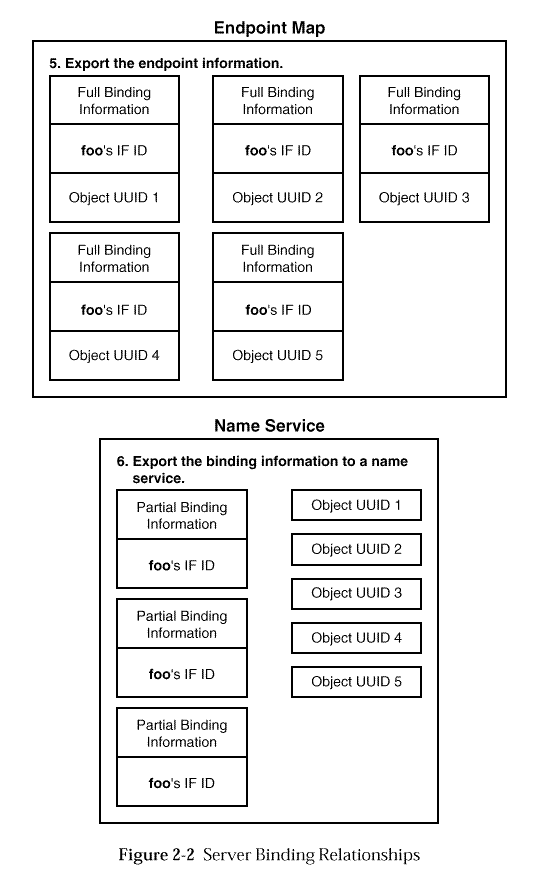
The server takes several steps (some of them optional) to establish
the necessary relationships, as indicated in
(The format is also different.
See
Note that not all of these steps are required.
Servers may construct their own bindings, by using string bindings,
rather than request them
Having completed the required steps, the server has established a set of relationships that allows the server run-time system to construct a complete binding, with routing to a specific server operation, for a call that contains the following information:
The algorithms used are described in some detail in
Note that the server run-time enironment
itself maintains only a very limited set
of relationships: interface identifier/type UUID/manager EPV and
object UUIDs/type UUIDs.
It is especially worth noting that
When the exported information is used by clients to find the server,
client calls arriving at the server endpoints should contain interface
identifier/object UUID pairs that the server can, in fact, service,
although the RPC mechanism itself can provide no guarantee of this.
This means that name service operations, while they are not, strictly
The indirect mapping from object UUID to type UUID to EPV (and hence
to the manager called) also gives the server great flexibility in
organising its resources based on objects UUIDs.
This is explained in
The client binding steps are considerably simpler than those taken by
the server.
The basic task of the client is to find a suitable binding and use
it to make a call, as described in the following steps.
To make a call, the client needs a compatible binding: that is, one
Clients find compatible bindings by making calls to RPC API routines that search the name service. Recall that a name service entry binding attribute stores a set of associations between interface IDs and binding information. The client needs to find an element that specifies the desired interface and an acceptable protocol sequence and import the binding information from that element.
Typically, the client specifies the interface desired, and the run-time system takes responsibility for finding bindings with protocol sequences that it can use. The client may also further select a specific protocol sequence.
The client's selection of a binding may also depend on an object UUID.
Recall that each name service entry may also store a set of object
UUIDs.
If the client requires a specific object UUID, it imports
For each binding that the client imports, the run-time system provides a
server binding handle that refers to the binding information
Once the server and client have taken all the necessary steps to set
up server and client side relationships, the call mechanism can use
them to construct a complete binding and call routing when the call is
made.
This section specifies the algorithms used.
In following these algorithms, it may be useful to refer to
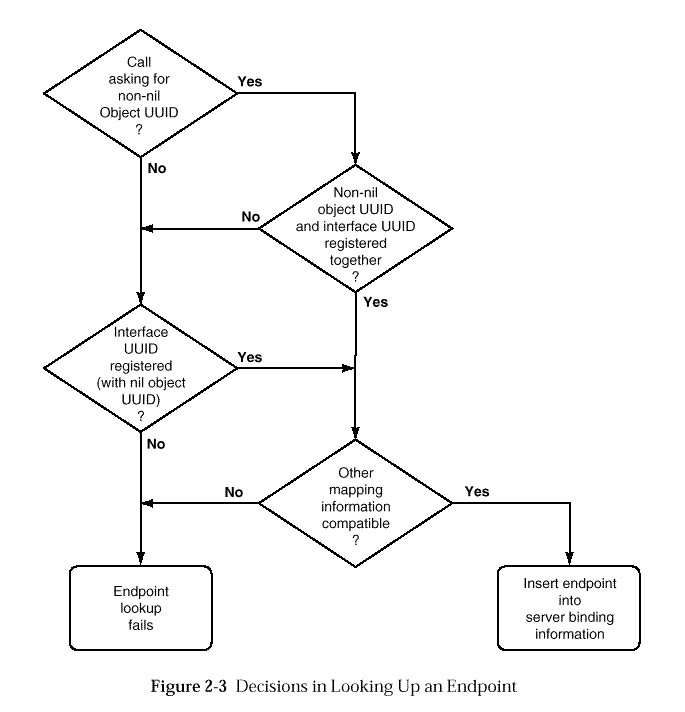
What is important to note in this algorithm is that the interface and protocol information must match to find an endpoint, but an object UUID match may not be required. A server can provide a default UUID match by registering the nil UUID. Calls with a nil or unmatched object UUID follow the default path.
The endpoint map permits multiple endpoints to be registered with identical interface, protocol and object UUID information. Such endpoints are assumed to be interchangeable, and the endpoint mapper selects among them using an implementation-dependent algorithm.
Recall, however, that the RPC mechanism makes it possible for a server
to implement multiple managers for an interface.
Hence it may be
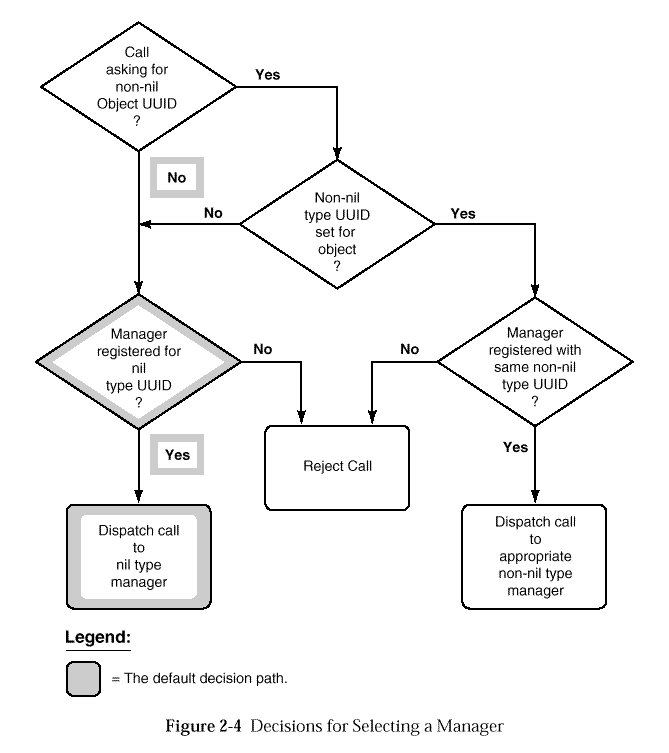
Here the server provides a default path by registering a default
manager for the nil type UUID.
Calls containing the nil object UUID, or any UUID
Once the manager is selected, the call is dispatched via the selected
manager EPV.
Recall that a manager EPV is a vector of pointers to
The actual call-via the manager EPV-to the server manager code
is made by the server stub.
Up to this point, the binding discussion has deliberately avoided
questions of implementation.
The run-time system maintains a set of relationships logically required by
the binding algorithms, but the way in which these are implemented
is entirely outside the purview of this document.
The case of the manager EPV is different, however.
The manager EPV is an interface-specific data structure that must
be declared by server code.
The stub normally declares a default manager EPV, but when there is
more than one manager for an interface, the application code must
declare further manager EPVs.
Client applications can exercise varying degrees of control over the
binding process outlined in
The automatic and implicit binding methods are interface wide and thus mutually exclusive. The explicit binding method may be specified per call and takes precedence over implicit or automatic binding specified for an interface.
Clients applications choose a binding method for an interface by
specifying an ACS binding attribute, as documented in
The RPC API provides an extensive name service interface that applications use to export and import binding information. In general, name services can support much broader usage, but the RPC API is designed to support the RPC binding mechanism, rather than as a generalised name service interface. The following sections describe those aspects of name services that are relevant to the name service interface and binding.
The name service interface is designed to be independent of the
underlying name service.
Hence, it is referred to as the Name Service-independent (NSI)
interface.
As far as possible, these sections describe the name service interface
without reference to any specific underlying name service.
However, applications using the name service interface need to
pass name service-specific names to the interface and therefore
must be aware of the details of naming for the underlying services.
These issues are discussed in
The name service interface is designed to allow servers to export
binding information, and clients to find it, in an efficient manner.
The interface permits servers to organise their binding information in
a variety of ways.
These support the server resource models described in
The name service interface makes two general assumptions about the underlying name service:
The name service interface is used to store associations between
bindings, interfaces and objects in name service entries.
For each interface offered by a server, the server exports a set of
protocol towers to the name service.
A protocol tower combines binding
Clients make name service API calls to search for suitable bindings, specifying the interface and, possibly, any object UUID they are interested in, as well as a starting point for the search. The name service search operations search name service entries and return bindings that are compatible with the requirements of the client.
A client search of the namespace beginning at a given entry follows
a path through name service entries determined by the algorithm given in
The name service interface maintains its name service independence by
using name syntax tags.
Each interface that takes an entry name
RPC ISO C implementations provide an RPC_DEFAULT_ENTRY_SYNTAX
environment variable that specifies a default entry name syntax tag.
The name service interface defines four RPC-specific name service attributes. These are as follows:
While the name service interface does not impose any explicit
restrictions on the use of these entries (there are no enforced
schema), the name service model is designed to support applications
that structure their name service entries according to the following
recommended rules:
The following sections describe the contents of the entry types in detail.
Server entries contain bindings for a single server. Server entries may also contain an object attribute that specifies a set of object UUIDs associated with the server.
The binding attribute in a server entry stores a set of protocol towers.
Recall that a protocol tower consists of an interface
The information stored by the binding attribute does not include
object UUIDs.
Instead, when a server wishes to associate object UUIDs
A group entry contains names of one or more server entries, other groups or both. A group provides a way to organise the server entries of different servers that offer a common RPC interface or object. Since a group can contain group names, groups can be nested. Each server entry or group named in a group is a member of the group. A group's members should offer one or more RPC interfaces, objects or both in common.
A profile is an entry that contains a prioritised set of profile elements.
A profile element is a database record that
This field is the search key for the profile.
The interface identifier consists of the interface UUID and the
interface version numbers.
The entry name of one of the following kinds of name service entries:
The annotation string is textual information used to identify the profile. It is not used by NSI search operations but can provide valuable information to namespace and server administrators.
Additionally, a profile can contain at most one default profile
element.
A default profile element is the element that a name
The code sets attribute stores a server's code sets array, which is the list of the code sets that the server supports. This information is used by the internationalization support routines. The code sets array structure consists of a version number member (version), followed by a count member (count), followed by an array of code set data structures (rpc_cs_c_set_t). This array is declared to be a conformant array so that its size will be determined at runtime. The count member indicates the number of code sets contained in the array.
The first element in the code sets array represents the server process's local code set. The second through nth elements represent one or more intermediate code sets that the process can use to transmit character data over the network. The remaining elements represent other code sets supported by the server.
See
Routines to extract information from a name service are present in the API in suites of three. Each suite includes:
In general, applications use these suites as follows:
The begin routine returns a handle used by a subsequent series of search operations. The handle refers to information maintained by the run-time system about the search, including search context information-such as matching criteria-and information about the current state of the search. Each call to the begin routine returns a handle that maintains the context for a distinct series of subsequent search operations.
The next routine returns elements, or sets of elements, one by one along the path being searched. The application calls this routine one or more times with a handle obtained from the begin routine. Each call returns another element or a status code that indicates that no more elements remain. Calls to the next routine using the same handle form part of one series of search operations along a search path. Calls to the next routine using different handles pertain to distinct and independent searches.
The done routine frees the search context referred to by the
handle and invalidates the handle.
The name service search operations traverse a path through one or more
In each name service entry, searches ignore non-RPC attributes
and process the name service entry attributes in the following order:
If a search path includes a group attribute, the search path can encompass every entry named as a group member. If a search path includes a profile attribute, the search path can encompass every entry named as the member of a profile element that contains the target interface identifier.
The following pseudocode presents the algorithm for retrieving bindings from a namespace. This describes the order in which bindings are returned by the routines rpc_ns_binding_import_done() and rpc_ns_binding_lookup_next().
In the pseudocode, each entryName, group member and profile element represent names that may be found in the namespace. Associated with each of these entries in the namespace may be any of the eight possible combinations of the binding, group and/or profile attributes.
The order in which bindings are returned is significant and is
indicated in the algorithm.
This algorithm only indicates the order of search.
Local buffering constraints may cause the search to be interrupted
and resumed.
Procedure GetBindings (someName) {
/* "someName" represents the name of an entry in the namespace. */
/* The following procedure recursively searches for bindings */
Procedure Search(entryName)
{
Check entryName for binding attribute;
If (binding attribute found)
{
Retrieve bindings from binding attribute;
Randomise the bindings obtained from this attribute;
Add these bindings to the bottom of the global list of bindings;
}
Check entryName for group attribute;
If (group attribute found)
{
Retrieve members from group attribute and save in a list;
Randomise the members in this list;
Do
{
Select the first member and remove from the list;
/* */
/* Cycle checking requires knowledge of other */
/* names referenced within the scope of a call */
/* to GetBindings. */
/* */
Check for a cycle;
If (not a cycle)
{
If (member selected exists)
{
Search (member selected);
}
}
}
Until (list of members is empty);
}
Check entryName for profile attribute;
If (profile attribute found)
{
Retrieve elements from profile attribute and save in a list;
Sort profile elements in list by priority, highest first;
Randomise the profile elements within each priority;
Do
{
Select the first profile element and remove from the list;
/* */
/* Cycle checking requires knowledge of other */
/* names referenced within the scope of a call */
/* to GetBindings. */
/* */
Check for a cycle;
If (not a cycle)
{
If (element selected exists)
{
Search (element selected);
}
}
}
Until (list of profile elements is empty);
}
}
/* This is the body of the main routine starting the search */
Initialize a global ordered list of bindings to empty;
Search (someName);
return ordered list of bindings;
}
Name service interface operations may cache name service data to avoid
unnecessary lookups in the name service database.
Whether caching occurs is implementation-dependent, but it is
expected that most implementations will use caching.
For implementations that cache, this document specifies the semantics
of caching to be governed by an expiration age as follows.
Cached name service data is given an
The RPC run-time system sets the expiration age to a default value. Applications can specify another value either globally for the application or for a specific name service handle. The global value applies, by default, to all name service operations performed by the application. A handle-specific value applies only to operations performed using a specific name service handle.
When an application changes its global expiration age, or even the expiration age for a single handle, the effects may not be entirely confined to the application itself. Frequent updates of name service cache data may affect the performance of other clients of the name service and applications sharing the same cache. For this reason, operations that affect expiration age are considered to be management operations.
A non-caching implementation may be considered as a degenerate case of
a caching implementation that behaves as if every cache item had
outlived its expiration age.
The RPC model is server-centred in the sense that RPC provides many facilities to support varied and powerful server implementations, often with relatively little programming effort. These include:
The RPC design assumes that servers export resources that may be widely available and possibly in high demand. The RPC model therefore provides for automatic concurrent service and buffering of RPC requests.
RPC provides server concurrency without requiring application code to
spawn additional threads or processes explicitly.
When beginning to listen for a call, the server application requests
a number of call threads, and the RPC run-time system automatically
provides the requested
Implementations may also allow additional requests that cannot be
executed concurrently to be queued for subsequent execution.
Otherwise they are rejected.
Applications may make buffer size requests when registering a
protocol sequence, although the actual
Servers automatically implement, in addition to the interfaces
specified by the programmer, a set of remote management interfaces
that can be used for such operations as making remote inquiries to and
stopping servers.
These are accessible, both locally and remotely, via management RPC
routines.
The RPC API gives programs a high degree of control of the process by which bindings are constructed, component by component. This allows programs to specify the precise service required by any given instance of a remote procedure call. At the same time, the name service interface permits applications to structure binding information stored by a name service in a variety of ways. Together, these capabilities are the basis for a variety of strategies for organising server resources, based on the way the components of a binding are made available by a server.
The RPC API does not require server resources to be organised in any specific way; it simply provides facilities that permit a variety of forms of organisation. The resource models outlined here are only conventions. However, this document recommends following these conventions. Servers provide resources that may be widely available, and they make use of a common resource-the name services-to advertise their bindings. Organising server resources according to well-defined conventions makes it easier to construct clients that can find the resources they need.
This document recommends three basic server resource models:
These models are not mutually exclusive.
In the server-oriented model, it is the server that is of interest to clients looking for bindings. In the simplest case, each server exports its bindings to one server entry and clients can go directly to a server entry to find bindings. Server instances may be interchangeable if they are running on the same host and offer the same interfaces and objects. Entries for interchangeable server instances may be organised as a group, and clients may begin their binding searches at the group entry.
In the service-oriented model, clients are interested in some service, as defined by an interface (and its versions). The interface may be exported by more than one server, and server entries for servers that export a given interface may be organised in the same group. However, client applications seeking services normally do not have knowledge of the local namespace that will lead them directly to the required group entry. Typically, such clients use profiles to find the local instantiations of services they want.
In the object-oriented model, a server associates some resource that it offers with an object UUID. Several servers may offer the same interface but different objects. Each server then exports the object UUIDs it offers to one or more separate server entries.
In order to make object UUIDs available to clients seeking a specific object, servers offering an object typically export object UUIDs to a group entry for that object. The group entry name is thus effectively associated with the object. Clients seeking a specific object can begin by importing an object UUID from the group entry for the object. The client then imports bindings for the object and interface it wants, beginning its search with the object entry.
Servers that export object UUIDs may or may not explicitly map these
to type managers. In the simplest case, the server only registers an
interface with a nil type UUID, causing all calls on the interface to
be handled by the default manager. In this case, the association
between object UUID and resource exists only in the namespace, and
the server must assume that a client interested in a given object has,
in fact, imported its binding correctly. On the other hand, servers
may use object/type mappings to dispatch calls precisely according to
object UUID. (See
The RPC API provides a small number of interfaces that applications
can use to set the authentication and authorisation services and the
protection levels used by remote procedure calls. Servers that want
Once the required authentication state is set, authentication and protection are carried out transparently by the RPC run-time system, using the specified services. If the server principal name and authentication service specified by the client do not match a pair registered by the server, the call fails. A server can specify a non-default authentication key retrieval function, but is not otherwise required (or allowed) to implement any of the authentication mechanism.
If the authentication requested is successful, the server manager routine can retrieve the caller's authentication, authorisation and protection-level information from the run-time system. Since the server may have registered more than one principal name/authentication service pair, the application code may still want to make an authentication decision at this point.
The server manager code also makes authorisation decisions based on the authorisation information it retrieves from the run-time system. The server is free to use this authorisation information to make whatever authorisation decisions are appropriate for the application.
The RPC security-related API is designed to be independent of any
specific authentication and authorisation services. Servers and
clients specify the required services via parameters to the
authentication-related calls. The run-time system carries out authentication
using the requested authentication service, passes authorisation
service-specific authorisation information with the call, and provides
protection that corresponds (in a service specific way) to the
requested protection level. Supported values for the authorisation,
authentication and protection-level parameters are specified in
The RPC API provides a number of routines that support
internationalized applications by enabling character and code set
interoperability, which permits clients and servers to transfer
international character data in a heterogeneous character set and code
sets environment. Interoperability is achieved by the appropriate
implementation of character and code set evaluation and conversion.
A locale defines the subset of a user's environment that depends upon language and cultural conventions and determines, among other things, the character sets and code sets used in that environment. (Locale definition functions are specific to operating systems.) A character set is a group of characters such as the American English alphabet or Japanese Kanji; a given locale generally defines one primary character set. A code set is a mapping of the members of a character set to specific numeric code values; examples include ASCII, JIS X0208 (Japanese Kanji), and ISO 8859-1 (Latin 1). The same character set can be encoded in different code sets; consequently, clients and servers may use the same character set but represent that character set in different numeric encodings.
Distributed applications running in a network of heterogeneous
operating systems need to be able to identify the character sets and
code sets in use by clients and servers in order to accurately
transfer data between them. DCE RPC, through the NDR transfer syntax,
supports automatic conversion of characters that are included in the
Portable Character Set (PCS) and are encoded in the ASCII and EBCDIC code
sets. RPC protocol requires all clients and servers to support the
PCS; the IDL base type specifiers char and
idl_char identify the included characters. The RPC run-time
system transparently converts such characters, if necessary, when they
are passed between client and server. (See
International character data consist of characters that are not
part of the PCS and the ASCII or EBCDIC code sets.
Applications that must transfer international characters can use the
provided IDL constructs and RPC routines to achieve accurate and
reliable character and code set conversion. For example, such an
application might handle European, Chinese, or Japanese characters
mapped to ISO 8859-4 (Latin 4), Big5, or SJIS encodings.
The code set registry allows the internationalisation support
routines to uniquely identify the code sets they encounter by
assigning a unique identifier to each code set. Because the
registry's code set identifiers are consistent across the network,
applications need not rely on operating system-specific string names.
The code set data structure contains a 32-bit hexadecimal value
(c_set) that uniquely identifies the code set, followed by a
16-bit decimal value (c_max_bytes) that indicates the maximum
number of bytes the code set uses to encode a single character.
A code sets array contains the list of the code sets that a
client or server supports. The first element in the code sets array
represents the code set in use in the client or server's local
environment. The second element through nth elements represent
one or more intermediate code sets that can be used to transmit
international character data over the network. Applications can
convert data into such an intermediate code set when their host does
not provide a converter for the remote local code set but does provide
a converter for the intermediate code set. All of the
internationalisation support routines support one intermediate code
set, the ISO 10646 Universal character/code set. Consequently, DCE
requires host systems running applications that transfer international
characters to provide converters for this code set. The csrc
utility can be used to designate other intermediate code sets to be
used in preference to ISO 10646. The remaining elements in the array
represent other code sets that the application's host supports.
Client and server applications converting international character data
must perform the following tasks in addition to those required for
other RPC applications:
For a list of the RPC API routines supporting internationalisation, see
The RPC API provides a consistent error handling mechanism for all
routines. Each routine includes a status output argument,
RPC calls return protocol and run-time error status codes through
fault_status and comm_status parameters, as described in
The status codes documented in this document must be supported by all implementations. Implementations may support additional status codes, but these are not required.
RPC provides a remote cancel notification mechanism that can forward asynchronous cancel notifications to servers. When a client thread receives a cancel notification during an RPC, the run-time environment forwards the notification to the server. When the server run-time system receives the forwarded notification, it attempts to notify the server application thread that is handling the call. This can result in one of three outcomes for the RPC call on the client side:
Client applications may want to avoid waiting an indeterminate amount
of time before a cancelled call returns. The RPC mechanism therefore
allows client applications to specify a cancel time-out period.
While stubs are generally transparent to the application code, applications may need to be aware of certain stub characteristics:
This version of this document specifies C-language stub bindings only.
Stubs generated from the IDL specification of an interface contain language-specific bindings for the interface operations. Client calls to remote procedures, and the server operations that implement these procedures, must conform to the bindings defined by the stubs. Therefore, applications must be aware of the mappings from the IDL data types that appear in an interface specification to the data types that appear in the stub declarations.
The C-language mappings are specified in
Stubs may contain a default manager EPV as described in
Each stub declares an interface handle, which is a reference to
interface specific information that is required by certain RPC APIs.
(See
RPC attempts to extend local procedure call parameter memory
management semantics to a situation in which the calling and called
procedure no longer share the same memory space. In effect, parameter
memory has to be allocated twice, once on the client side, once on the
server side. Stubs do as much of the extra allocation work as
possible so that the complexities of parameter allocation are
transparent to applications. In some cases, however, applications may
have to manage parameter memory in a way that differs from the usual
local procedure call semantics. This typically occurs in applications
that pass pointer parameters that change value during the course of
the call. Detailed rules for stub memory management by applications
are given in
The following sections summarise the RPC API routines, classifying them according to the kinds of functions they perform.
The routines in this group manipulate binding information. Most of these routines use binding handle parameters to refer to the underlying binding information. The string binding routines provide a way to manipulate binding information directly in string format.
A number of routines from the Object Operations and the Authentication and Authorisation groups also manipulate the information referenced by binding handles.
The routines in this group manipulate interface information. Many of these routines take interface handle arguments. These handles are declared by stubs to reference the stubs' interface specifications. The routine rpc_server_register_if() is used to establish a server's mapping of interface identifiers, type UUIDs and manager EPVs. The routine rpc_if_inq_id() can be used to return the interface identifier (interface UUID and version numbers) from an interface specification.
The routines in this group deal with protocol sequences. The various server_use* routines are used by servers to tell the run-time system which protocol sequences to use to receive remote procedure calls. After calling one of these routines, the server calls rpc_server_inq_bindings() to get binding handles for all the protocol sequences on which it is listening for calls.
The routines in this group manipulate information in an application host's local endpoint map. These include the routines that servers typically use to register and unregister their binding information in the local endpoint map. A set of endpoint management routines is also available for more general manipulation of local and remote endpoint maps.
The routines in this group manipulate object related information. Servers use rpc_object_set_type() to establish their object UUID/type UUID mappings. Clients typically specify the object UUID they wish to associate with a binding when they import bindings from a name service. However, clients can use rpc_binding_set_object() to associate a different object UUID with a binding. Servers can use rpc_object_set_inq_fn() to establish private object UUID/type UUID mappings.
Applications use the routines in this subgroup to the export and import bindings to and from name service server entries. These include two suites of begin/next/done routines that applications can use to import bindings, as well as three routines for manipulating protocol towers.
Applications use the routines in this group to return information about name service entries of various types.
Applications use the routines in this group to manipulate name service group entries.
Applications use the routines in this group to manipulate name service profile entries.
Applications use the routines in this group to manipulate the authentication, authorisation and protection-level information used by authenticated remote procedure calls.
Applications use the routines in this group to implement character and code set interoperability, which permits clients and servers to transfer international character data in a heterogeneous character set and code sets environment.
This routine performs the final step in server initialisation, causing the server to begin to listen for remote procedure calls.
Applications use this routine to free the string memory allocated by RPC API routines that return strings.
The routines in this group manipulate UUIDs.
The routines in this group enable applications to participate in stub memory management.
The routines in this group provide a more general interface for manipulating endpoint maps than the one provided by the Local Endpoint Operations group. Routines in this group allow the examination of endpoint map elements one at a time and permit operations both on the application host's local endpoint map and on remote endpoint maps. These are considered management operations because of their potential to affect applications other than the one making the management call.
The routines in this group carry out operations typically done by name service management applications or only infrequently done by most applications. These are considered management operations because of their potential to affect applications other than the one making the management call.
The routines in this group provide a set of miscellaneous local operations that servers and clients can use to manage their RPC interactions.
Applications can use the routines in this group to query and stop servers remotely. Servers can also use these operations to query and stop themselves.
The dce_error_inq_text() routine provides a locale-independent
way to get error message text for a status code returned by an RPC API
routine. Because this routine is not RPC-specific, it is documented in
Please note that the html version of this specification may contain formatting aberrations. The definitive version is available as an electronic publication on CD-ROM from The Open Group.
| Contents | Next section | Index |