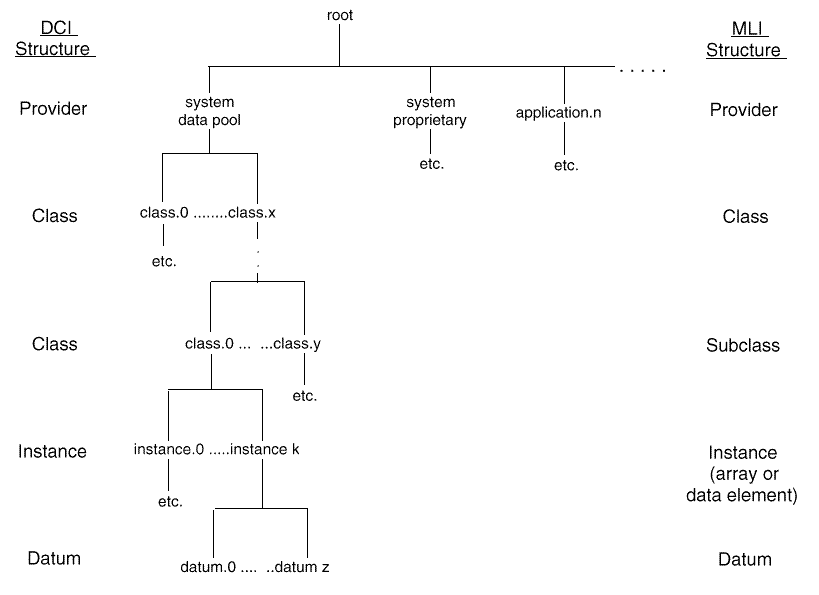
The UMA Data Pool groups data into classes and subclasses. Each data class can have several subclasses. The class identifies the major grouping (for example, memory, processor) and the subclass provides a specific grouping with class (virtual memory usage, block I/O counters). Within a subclass there is data (or metrics) which can be used to represent various kinds of data, including absolute counts, different counter values over an interval, and event data.
First, there are the levels of granularity as seen by an MLI or DCI consumer. These levels descend through class, subclass, instances and individual data items. Instances are used to identify specific occurrences of data, for example, a process id or disk drive address. In addition, there are metric attributes that describe the data itself. These include data type, units, labels, and event attributes. An MLI application accesses these by requesting specific UMA Configuration subclasses. A DCI consumer can request these through a set of API calls.
Another characteristic is that of a provider dimension (shown as the first level under the name space root). The UNIX kernel is one such provider, albeit one for which the class definitions have been already addressed in detail. Providers for other operating systems are not only possible but will be encouraged, as will providers for user application components such as DBMS or transaction management components. End-users may also wish to instrument their mission-critical applications and include this performance data in the UMA name space as well.
It should be noted that there are some differences between the MLI and DCI views of the name space. The DCI maintains a name space structure which allows multiple class and instance levels (instances and data may only occur at the lowest class level in order to avoid object naming ambiguities). The MLI consumer (that is, a MAP) sees data assembled in simple class/subclass structures presented in data messages. Instances of a metric are either uniquely designated by an identifier in the subclass1 or by an array index (for example, system call number). The DCI name space cross reference number may be used to uniquely identify each metric in an MLI-based application (for example, for specifying a threshold variable). This number is a string of period-separated numeric characters representing class, subclass and position number in the provider's Data Pool2.
The presence or absence of particular segments or data items are indicated by attributes in UMA configuration subclasses.
| Contents | Next section | Index |