Thus, for example, on one node that functions as a measurement data server, we might wish to configure a measurement server instance that includes the method for writing to a historical archive of performance data, but not do so at another node that functions only as a business application entity, that is, an object that provides performance metrics about itself.
For example, some measurement applications and users might have authorisation to write to some specific database within a measurement data archive but not to others, or some users might have the authorisation to see performance data concerning some business application(s) but not others, etc.
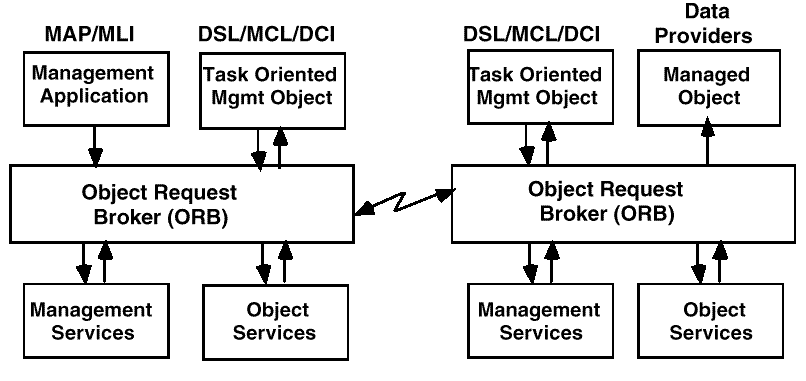
This implies, for instance, that a measurement application at one network location (a manager system) may request and receive data from a measurement server or managed system at another network location without having to directly establish contact with the remote provider. The measurement model formulates such access as a peer-to-peer communications between objects in the Data Services Layer.
For the measurement model these would be the Measurement Layer Interface (MLI) and the Data Capture Interface (DCI).
The Management Information Base (or MIB) is a virtual data store through which managed objects are accessed. Objects in the MIB are defined using Abstract Syntax Notation One (ASN.1) (which is how data objects are defined in the UMA DCI name space). Object types include integers, IP addresses and counters (non-negative integers).
Although the MIB has included some host level information, most of it is not of the fine granularity required for system performance management. The MIB focus has been primarily on network information, whereas the UMA Data Pool has focused extensively on the host with some network data included. In this sense, the MIB and the UMA Data Pool are mostly complementary.
SNMP as a protocol implies that the management station and the agent in a network element communicate via the network, thus data collection implies network load. In UMA, this is not necessarily true; one can have a local DCI or MLI consumer on a host that collects, analyzes and acts on data collected for that host, with no resulting network load. Furthermore, where data is to be exported from a host, UMA intrinsically provides mechanisms for data selection and threshold filtering, thus reducing network traffic to only the most essential.
Architecturally, UMA and SNMP can complement each other in the following two ways:
This is done in the most straightforward manner by registering the name space contents for MIB- provided data under an SNMP provider position in the DCI name space.
Depending on the complexity of the task, either a simple DCI consumer application or a MAP can play this agent role. Using a MAP built on the MLI, it is possible to produce either composite numerical information or SNMP traps based on data simultaneously acquired from a set of distributed platforms.
It is expected that a number of organisations will investigate and prototype implementations based on either or both of these approaches to the SNMP/UMA relationship.
On cursory examination, the DMI may appear to have similar function to the DCI component of UMA. Both have the goal of providing component instrumentation to management applications. Both are single system interfaces. Both provide for polled data acquisition as well as component events.
However, there are substantial differences. These arise from the DCI having been designed specifically for performance management. This has resulted in a richer name space and navigation mechanism (consider, for example, the unrestricted name space depth and the wildcarding capability supported by the DCI); the ability to obtain large amounts of data spanning different system components with relatively small queries and to do so at a high rate - the DMI instead mandates the formulation of requests into small units making the requesting of large amounts of data require the issuing of many requests. Furthermore, the UMA interfaces and name space can support the notion of trace by use of high-speed events, for which substantial volumes of data can be directed to a file at a very high rate.
As for events (sometimes called indications in the DMI specification), the DMI requires that each management application that may wish to be notified of even just a single event receive all events, which requires management applications to filter for those events they wish to examine. In server environments, there will be many events occurring (say, for example, process terminations) and it would be most inefficient to notify all management applications of each and every one. The UMA interfaces allow consumers to specify event sensitivity so that the DCI and the Data Services Layer will selectively notify their consumers of only those events that were selected.
Considering next the DMI MIF file that describes a component's manageable characteristics, this file must be loaded (or reloaded) in its entirety into the MIF database each time there is a change to the availability of a characteristic. This approach to registration is far more suited to relatively static data such as represented by system configuration and availability information than it is to rapidly changing metric availability. Performance management requires (and the DCI provides) more dynamic registration right down to the metric and instance levels as might, for instance, be represented by the appearance and termination of a process thread.
It is therefore expected that systems will support both DMI and UMA. UMA (through the
DCI) will provide access to the typically very dynamic and high volume performance data,
while DMI will make configuration and vital product data available (for example). Where
appropriate, DCI providers could make use of the DMI to obtain the configuration
information required to support the UMA Data Pool. This would ensure a single source
for this type of data.
| Contents | Next section | Index |