Previous section.
Systems Management: Common Information Model (CIM)
Copyright © 1998 The Open Group
Repository Perspective
Overview
This Chapter provides a basic description of a repository and a
complete picture of the potential exploitation of it. A repository
stores definitional and/or structural information, and includes the
capability to extract the definitions in a form that is useful to
application developers. Some repositories allow the definitions to be
imported into and exported from the repository in multiple forms. The
notions of importing and exporting definition can be refined so that
they distinguish between three types of mappings.
Using the mapping definitions in
Mapping Existing Models into CIM
,
the repository can be
organized into the four partitions (meta, technique, recast and
domain), as shown in
Repository Partitions
.
-
-
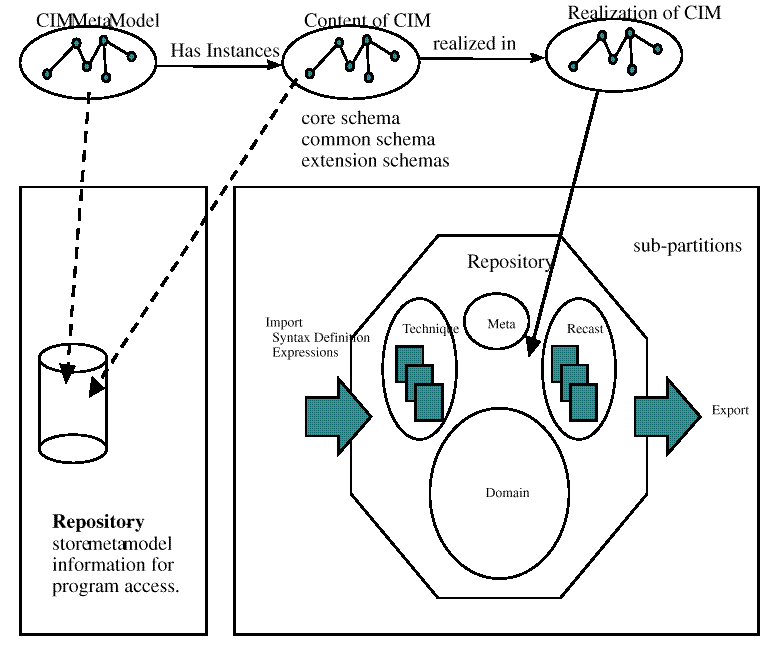
Figure: Repository Partitions
The repository partitions have the following characteristics:
-
Each partition is disjoint.
-
The Meta partition refers to the definitions of the CIM metamodel.
-
The Technique partition refers to definitions that are loaded using
technique mappings.
-
The Recast partition refers to definitions that are loaded
using recast mappings.
-
The Domain partition refers to the definitions that are
associated with the core, common, and Extension schemas.
-
The Technique and Recast partitions can be organized into
multiple sub-partitions
in order to capture each source uniquely. For example, there would be a
Technique sub-partition for each unique metalanguage encountered (that is, one
for MIF, GDMO, SMI, and so on). In the Recast partition there would be
a sub-partition for each metalanguage.
-
The act of importing the content of an existing source
can result in entries in the Recast or Domain partition.
DMTF MIF Mapping Strategies
Assume the metamodel definition and the baseline for the CIM schema
are complete. The next step is to map another source of management
information (such as standard groups) into the repository. The
primary objective is to do the work required to import one or more of
the standard group(s).
The possible import scenarios for a DMTF standard group are:
-
To Technique Partition:
Create a technique mapping for the MIF syntax. This
mapping would be the same for all standard groups and would only need to be
updated if the MIF syntax changed.
-
To Recast Partition:
Create a recast mapping from a particular standard group
into a sub-partition of the recast partition. This mapping would allow the entire
contents of the selected group to be loaded into a sub-partition of the recast
partition.
The same algorithm can be used to map additional standard groups into
that same sub-partition.
-
To Domain Partition:
Create a Domain Mapping for the content of a particular
standard group that overlaps with the content of the
CIM schema.
-
To Domain Partition:
Create a Domain Mapping for the content of a particular
standard group that does not overlap with CIM's schema into
an extension sub-schema.
-
To Domain Partition:
Propose extensions to the content of the CIM schema
and then perform Steps 3 and/or 4.
Any combination of these five scenarios can be initiated by a team that is responsible
for mapping an existing source into the CIM repository. There are many other details
that need to be addressed as the content of any of the sources changes and/or when
the core or common model changes.
Assuming numerous existing sources have been imported using all the import
scenarios, now look at the export side. Ignoring the technique partition,
the possible scenarios are:
-
From Recast Partition:
Create a recast mapping for a sub-partition in the recast
partition to a standard group (that is, inverse of import 2).
The desired method
would be to use the recast mapping to translate a standard group into a GDMO
definition.
-
From Recast Partition:
Create a Domain Mapping for one of the recast sub-partitions
to a known management model that was not the original source for the
content that overlaps.
-
From Domain Partition:
Create a recast mapping for the complete content of the
CIM to a selected technique (for MIF, this results in a non-standard group).
-
From Domain Partition:
Create a Domain Mapping for the content of the CIM schema
that overlaps with the content of an existing management model
-
From Domain Partition:
Create a Domain Mapping for the entire content of the CIM schema
to an existing management model with the necessary extensions.
Recording Mapping Decisions
In order to understand the role of the scratch pad (see
Mapping Scratch Pads
)
in the repository, it is necessary to look at the import and export
scenarios for the different partitions in the repository (technique,
recast and application). These mappings can be organized into two
categories:
-
Homogeneous
-
Heterogeneous
The homogeneous category
includes the mapping where the imported syntax and expressions are the
same as the exported (for example, software MIF in and software MIF
out). The heterogeneous category addresses the mappings where the
imported syntax and expressions are different from the exported (for
example, MIF in and GDMO out). For the homogenous category, the
information can be recorded by creating qualifiers during an import
operation so the content can be exported properly. For the
heterogeneous category, the qualifiers must be added after the content
is loaded into a partition of the repository.
Homogeneous and Heterogeneous Export
shows the X
schema imported into the Y schema, and then being homogeneously
exported into X or heterogeneously exported into Z. Each of the export
arrows works with a different scratch pad.
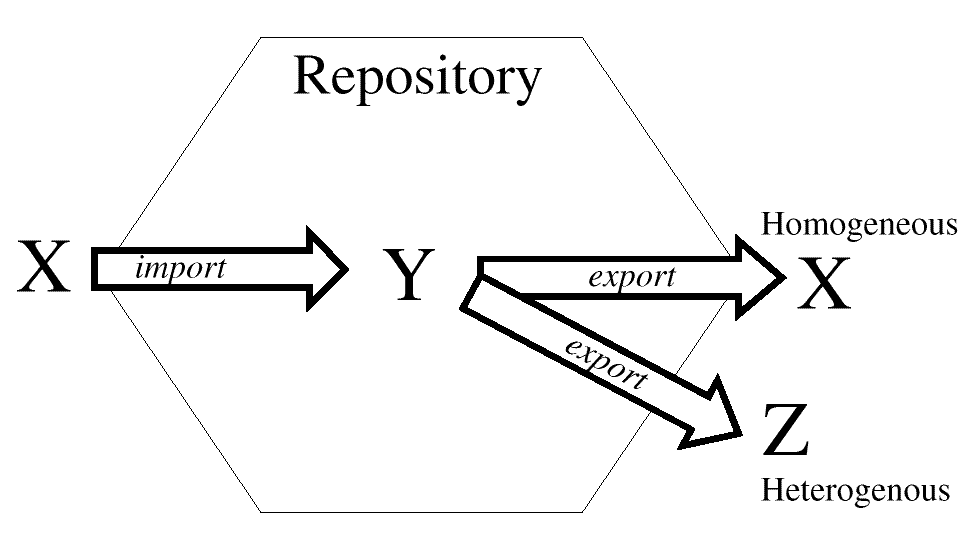
Figure: Homogeneous and Heterogeneous Export
The definition of the heterogeneous category is actually based on knowing how a
schema was loaded into the repository. A more general way of looking at this is to
think of the export process using one of multiple scratch pads. One of the scratch
pads was created when the schema was loaded and the others were added to handle
mappings to schema techniques other than the import source (see
Scratch Pads and Mapping
).
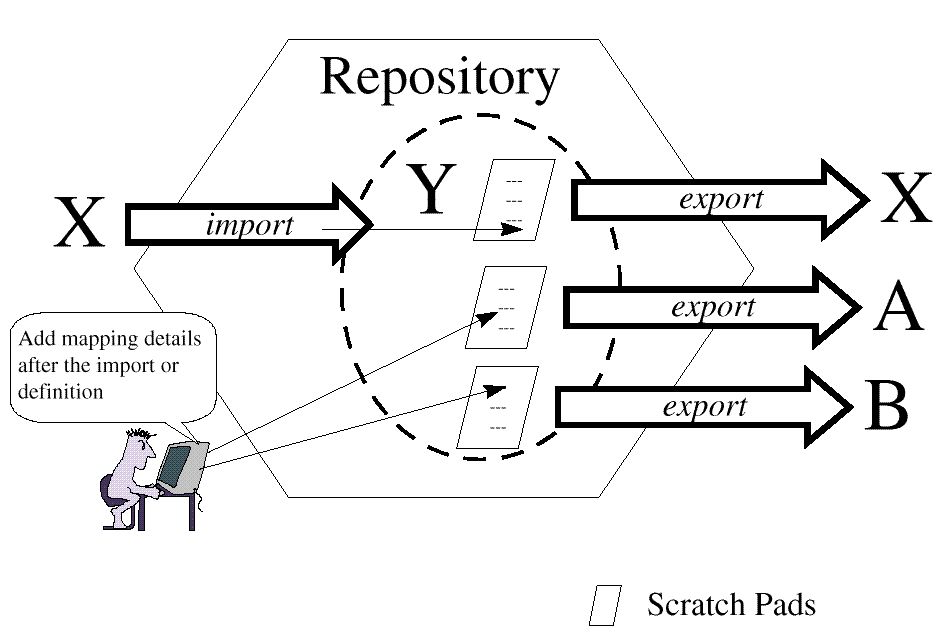
Figure: Scratch Pads and Mapping
Scratch Pads and Mapping
shows how the scratch
pads of qualifiers are used without factoring in the unique aspects of each of the
partitions (technique, recast, applications) within the CIM repository. The next step
is to put this discussion in the context of these partitions.
For the technique partition, there is no need for a scratch pad
since the CIM metamodel is used
to describe the constructs used in the source metaschema. Therefore,
by definition, the assumption is that there is one
homogeneous mapping for each
metaschema covered by the technique partition.
These mappings create CIM object
for the syntactical constructs of the schema and create associations for the ways they
can be combined (for example, MIF groups include attributes).
For the recast partition, there are multiple scratch pads for each of the sub-partitions,
since one is needed for each export targets (as shown in the previous figure) and
there can be multiple mapping algorithms for each target. The latter occurs because
part of creating recast mapping involves mapping the constructs of the source into
CIM metamodel constructs. Therefore, for the MIF syntax, a mapping needs
to be created
for component, group, attribute, etc. into appropriate CIM metamodel constructs like
object, association, property, etc. These mappings can be arbitrary. As a specific
example, one of the decisions that needs to be made is whether a group maps into an
object or a component maps into an object. It would be possible to have two different
recast mapping algorithms, one which mapped groups into objects with qualifiers that
preserved the component and one which mapped components into objects with
qualifiers that preserved the group name for the properties. Therefore, the scratch
pads in the recast partition are organized by target technique and employed
algorithm.
For the domain partitions, there are two types of mappings.
The first is similar to the recast partition in that some portion of the domain partition
is mapped into the syntax of another metaschema. These mappings can use the same
qualifier scratch pads and associated algorithms that are developed for the recast
partition. The second type of mapping facilitates documenting the content overlap
between the domain partition and some other model (for example,
software groups). These
mappings cannot be determined in a generic way at import time;
therefore it is best to consider
them in the context of exporting. The mapping uses filters to determine the overlaps and
then performs the necessary conversions. The filtering can be done using qualifiers
which indicate a particular set of domain partition constructs map into some
combination of constructs in the target/source model. The conversions would be
documented in the repository using a complex set of qualifiers which capture the notion
of how to write or insert the overlapped content into the target model. The
mapping qualifiers for the domain partition would be organized like the recasting
partition for the syntax conversions and there be scratch pads
for each of the models for documenting overlapping content.
In summary, pick the partition, develop a mapping, and identify the
qualifiers necessary to capture potentially lost information when
developing mapping details for a particular source. On the export
side, the mapping algorithm checks to see if the content to be
exported includes the necessary qualifiers for the logic to work.
Why not acquire a nicely bound hard copy?
Click here to return to the publication details or order a copy
of this publication.