
A number of areas are not covered in the 1387.2 Standard. A few things (such as physical media) are truly outside the scope of the Standard. However, some things are listed as either undefined or unspecified.
The requirements for all POSIX.2 utilities and all the file system features of POSIX.1 were significant issues in formulating this Standard. It was asserted that the underlying operating system need not be fully POSIX.1 or POSIX.2 conformant. With the requirement left as it is, implementation on such systems as DOS, OS/2, MVS, VMS, etc., is feasible.
Implementers of this Standard should provide some guidance to those who write scripts which will be packaged in distributions. It is actually those scripts that have significant dependencies on the features of the underlying operating system. Assured portability of scripts is not possible without assurance of an interpreter and utilities. By allowing other interpreters, some concession has been made to assist in managing existing software in the real world. The best portability assumption is that the checkinstall, preinstall, and postinstall scripts should not depend on features beyond those of POSIX.2 or POSIX.1. The configure scripts run only on the systems that actually use the software, and hence they need not be as portable as the preinstall and postinstall scripts.
This Standard specifies distributed operations without specifying the
mechanism for how it is to be achieved.
Work to specify interoperability for this Software Administration specification has been taken up by The Open Group, which has published a specification defining interoperability using the Distributed Computing Environment (DCE) remote procedure calls (RPC) - see reference XDSA-DCE. Specifications for other technologies to provide distributed XDSA working will be added as and when industry support for them becomes evident.
Distributed applications require actions to be performed in more than one place (system or directory). These distributed portions have often been referred to as client and server. Software administration tasks also are often initiated by different users at different times. Since the terms client and server have implementation implications beyond the scope of this Software Administration specification, the more neutral concept of role is introduced. This stems from a need to refer to things that occur logically, if not physically, on what might be thought of as a client or server. In the context of this Software Administration specification, roles are simply a convenient way of referring to where function is apparent, with no implication for how this is actually implemented.
It may be helpful to think of roles as separate processes, one per role, but that is only one possible implementation. Roles may operate on separate systems, or hosts, although all roles may operate on the same host. For example, the packager role creates an initial distribution. When copying this distribution, the source role provides read access to the distribution files, while the target role writes the new copy. This new copy may then be read by another source role for another install or copy.
For any implementation, a role consists of the entire set of tasks that may occur within the role. A task is a set of well-defined behaviors and state changes in the managed objects. Tasks are initiated by the system administrator using a specific command in the command line interface (CLI). Tasks are defined by this Software Administration specification in terms of the state changes on the software objects on target hosts.
As each task proceeds, different roles are involved. These roles may be realized on a single machine or could involve a different machine for each role.
This role is
outside the scope of
this Software Administration specification.
In
Manager control is understood as a more common need than target control, so at least that should be supported. For this reason, the manager role sets the options for a task, and each of the target hosts implements those options. So, any extension involves a set of ways to define selected control over particular policies. A design for this has not been pursued beyond recognizing the complexity of the problem.
The manager role provides the means of controlling the way software is created, transferred, and installed. In particular it provides an administrative interface to the other roles, enabling their activities to be controlled in a coordinated manner.
The packager role transforms a product from the format produced by the developer role to the format specified by this Software Administration specification for use by the next stage of the process, the source, and manager roles. The packager role defines the requirements for this transformation to be successful - the input (the product specification file, and the files it describes), the command line interface to initiate the transformation (.I swpackage ) utility, and the output of the packaging task (packaging layout).
Two distinct, but related, formats for packaged software are supported by this Software Administration specification - a structured format residing within a POSIX.1 hierarchical file system (such as disk, CD, etc.), and a bit stream representation residing on any serial device or file (such as tape, tar archive file, etc.).
Software exists in the source until it is removed by a task initiated by the manager.
The source role provides a repository where software may be stored, and provides access for those roles that require the software.
For example, when installing software, the target is where software is installed after having been delivered from a source. As another example, the target for a copy task command refers to the distribution where products are added. For management tasks like removing software, the target refers to either the installed_software objects or the distributions from which software is being removed.
Part of the distributed model involves the target role granting permission to the manager role to perform various software administration tasks. Authority for certain classes of tasks may be individually controllable, for example, modifying vs. listing installed products. While it is entirely conceivable that the target may want to restrict the way authorized tasks are performed, it is beyond the scope of this Software Administration specification.
Software is configured for use on the client.
An example is installing for an environment where many hosts share software from one system. Diskless systems are one example of systems that do such sharing. A manager role initiates the install task with the source role serving the software from the distribution and the target role installing the software on a fileserver. After the installation is complete, then a client role on each client sharing this software performs configuration for the shared software and the client host.
It is important to understand the difference between the target and
client roles.
The client role is where the software is actually used
and where configuration of the software takes place,
while the target role is where the software is installed.
Although in many cases these are the same machines, in some cases
they are different and the separation of configuration from installation
is important.
Each target from the
targets
operand of an
install or configure task may identify a target role (if installing but
not configuring), a client role (if just configuring), or both
(if installing and configuring).
Two examples of when these roles refer to different machines are:
This Software Administration specification defines a set of utilities that is such an administrative interface. These utilities provide basic facilities for controlling the individual tasks. Other management applications may be built that provide much more comprehensive software administration facilities. This Software Administration specification defines facilities that enable management applications to control software administration across any number of systems with conforming implementations.
One item of note among the general terms is the definition of symbolic link (see the Glossary). While not yet standardized (see referenced document B21), symbolic links are an entrenched part of existing practice. This Software Administration specification makes no attempt to independently define symbolic links. Rather, the functional characteristics of symbolic links are undefined.
The following tasks are identified in this Software Administration specification. The defined utilities provide a way of accomplishing these tasks except as noted.
In the case where the system on which the software is installed will also be using the software (that is, it is acting as both a target and client role), configuring the software can be combined with the install software task.
The new revision of software can be installed in the same location as the current revision. In this case, the software configure scripts executed by the configure task need to handle saving or updating the necessary configuration data.
The new revision of software can alternatively be installed in a location different than the current revision. In this case, the old revision may be unconfigured by the unconfigure script executed as part of the unconfigure task, and the new revision is configured by the configure scripts executed as part of the configure task.
The older revision of software can be installed in the same location as the current revision. In this case, the configuration process of the older version handles the necessary changes in configuration.
The older revision of software can alternatively be installed in a location different from that of the current revision. In this case, the new revision can be unconfigured via the unconfigure task, and the older revision can be configured either independently, or as part of install.
Updates and patches can be implemented through standard 1387.2 facilities and control scripts, although these control scripts can become quite complex. This Software Administration specification also proposes significant enhancements to the standard to facilitate these operations.
If the system where the software is installed was also using the software, unconfiguring the software can be combined with the remove software task.
Customer update requirements for software updates were perceived as follows:
Provider update requirements for software updates were perceived as follows:
Customer patch requirements were perceived as follows:
Patch provider and support organization requirements were:
Implementation conformance is intended to be based on implementation of the utilities defined in this Software Administration specification, and on the proper POSIX.1 and POSIX.2 support from the operating system.
There is scope for a new conformance class - Distribution Conformance - to allow suppliers of software to package their software in a conformant manner. Distributions have many of the characteristics of applications using POSIX.2, since the distributions contain executables (presumably shell scripts).
This would assure that every Conforming Implementation would be able to install any strictly conforming distribution properly, including the proper settings of file attributes. One might question this need if one is installing software particular to a system that is not POSIX.1 conformant. It is the pervasive ability to serve the software over a distributed file system that makes critical the need for all conforming implementations to understand at least one set of well specified operating system behavior. The one set of operating system behavior chosen is POSIX.1. The need for POSIX.2 is primarily driven by the presence of executable control files within distributions. At least one guaranteed mechanism is required to invoke those files, and the shell interpreter was chosen for that purpose. Further, developers of portable scripts need a guarantee of some basic set of utilities with which to work, and the POSIX.2 utilities were chosen for that purpose.
A conforming implementation need not include the POSIX.1 and POSIX.2 implementation itself, but it must document how such can be obtained for the systems that the implementation supports. It is reasonable to assume that a given implementation, conformant in the presence of proper POSIX.1 and POSIX.2 support from the operating system, may still operate correctly on some distributions even when the proper operating system support is not present in full or in part.
This class would also provide flexibility for distributions needing to conform to other constraints related to the support of POSIX.1 and POSIX.2. There was strong support among the user community in the 1387.2 development project for support for interpreters other than sh. Support for other interpreters also permits the use of such distributions on systems, such as DOS, which are not conformant with POSIX.1 or POSIX.2.

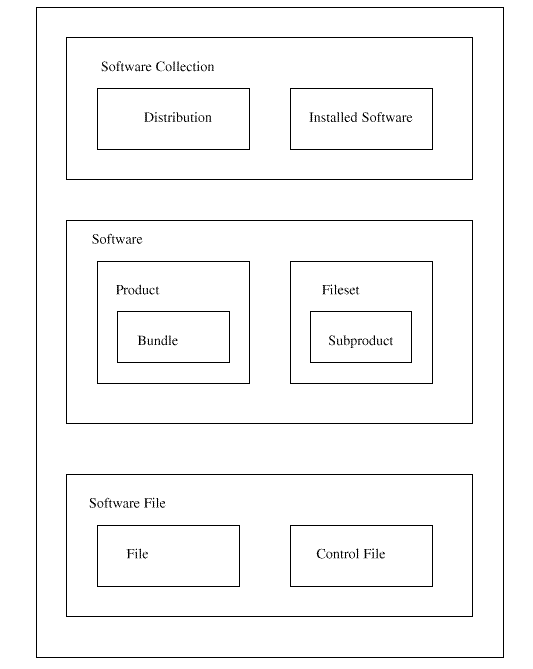
At the top of the hierarchy is a host, which is a system that conforms to this Software Administration specification. It is the starting point for finding all the software on that system that falls within this Software Administration specification. A host contains software_collections.
There are two distinct types of software_collections, as listed in the following, that may exist within a conformant system:
Software is organized into a hierarchy of objects, as described in the following, that are operated on by the utilities defined in this Software Administration specification:
The software_files define the files and control_files that are contained in the software objects that are operated on during a software administration utility. There are two classes of software_files as described in the following:
Most control scripts are run on the target, which may be a different architecture than the client on which the software operates. They should, therefore, use POSIX.2 utilities, except where they can determine that they are running on the client.
In addition to scripts, other control_files provide input to the control scripts, or to the utilities directly (for example, the response and space control_files).
The distributions and installed_software objects are the sources or targets of a software administration command. The software objects (products, filesets, bundles, and subproducts) are the objects that are being applied to those targets.
This Software Administration specification describes the structure and the attributes for software_collections, software objects, and software_files. It also describes the behaviors for the utilities that operate on these objects. However, these structure definitions are not managed object classes in the ISO sense because the behaviors are not described in terms of methods within object classes1.
The reference arrows designate objects that are included when this object is operated on. An object may be referred to by more than one object. Bundles need not refer to entire products, but can refer to individual filesets or subproducts. Fileset and subproduct objects can be referenced directly by bundles by also identifying the product of which the fileset or subproduct is a part.
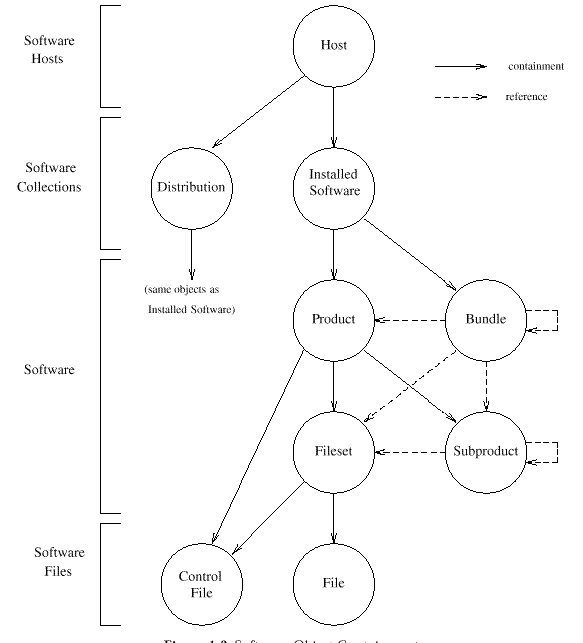
Interoperability between implementations of this Software Administration specification may be achieved through the definition of methods for the first two of these common classes, "software_collections" and software. The software_collections are the source and target objects for software administration, while the software objects are the objects that are operated on within the context of the software_collections. Operations on individual software_files independent of operations on software objects is undefined.
This Software Administration specification also does not define how remote file systems are managed. In the simplest case, each file system is "local" to a single host, and all installations may be directed to the file system through an agent process on that host. Thus, files on a file system are contained within one of the installed software collections contained below that host. On the other hand, an implementation may also choose to allow installation to a remote file system over a remote file system protocol. That is, the target process is running on a host that is different from the one that contains the file system. In this case, the files on that file system may be contained within the same software collection as before, or may be contained within a local software collection. In another implementation, all software collections may be stored within a global naming service instead of below any particular host.
An implementation may choose to define a software host object, or manage
software as part of a more general host object.
The attributes of a host object that are of interest to this Software Administration specification
are shown in
| Attribute | Length | Permitted Values | Default Value |
|---|---|---|---|
| host | Undefined | Portable character set | None |
| os_name | 32 | Portable character set | None |
| os_release | 32 | Portable character set | None |
| os_version | 32 | Portable character set | None |
| machine_type | 32 | Portable character set | None |
| distributions | Undefined | List of distribution directories | Empty list |
| installed_software | Undefined | List of installed_software directories and catalog identifiers | Empty list |
The following are the attributes of the hosts that contain software_collections managed by this Software Administration specification:
These describe the PATHNAME portion of a software_collection source or target.
Identification of a remote host system is dependent on the networking services implementation and thus the syntax and semantics of the host name is undefined within this Software Administration specification.
These describe the PATHNAME portion of a software_collection target.
It is the hardware type on which the system is running.
It is the name of this implementation of the operating system.
It is the release level of the operating system implementation.
It is the version level of this release of the operating system.
Multiple versions of products and bundles are possible when subsequent releases of a product or bundle have different revision numbers, and when products or bundles targeted for different machine types or other OS attributes define the architecture attribute differently.
The layout_version attribute is the version number of this Software Administration specification to which the distribution conforms. The name of this Software Administration specification (for example, P1387.2-19xx) was considered but there was concern that the delay between IEEE acceptance and ISO acceptance would make it hard to pick the year correctly. It is not clear when to change the number from 1.0 to 1.1 or even from 1.x to 2.0.
It is possible for an INDEX file describing a distribution to contain products with different values of layout_version. The software_collection layout_version refers only to the format of the distribution attributes and the product keyword. After the product keyword, the product layout_version defines the format of the definitions of all objects within that product.
The need for the media_sequence_number attribute is to number the tapes (or disks or whatever) if a distribution is on more than one of them. If there is only one, then its number is 1.
The following attributes at one point were listed as distribution attributes. However, it was determined that the only time it could be guaranteed that these attributes were accurate was for an initial distribution definition. As soon as a swcopy or swremove operation occurred on a distribution, the attributes could be invalid because it would be impossible to modify these attributes in any logical manner based on the operation. It is recognized that these attributes are valuable and many vendors may choose to put them in as vendor extensions.
Usually distributions will be created upon creation of the first product with swpackage or swcopy. Usually distributions will be removed as a part of removing the last product with swremove. An implementation may choose to provide more explicit control for creation and deletion of empty distributions. The swcopy and swremove utilities should be used for this purpose. The swmodify utility may also be used.
This standard has defined four related software objects:
See
The need to localize the following descriptive software and vendor attributes was recognized - title, description and copyright. However, since the existing practice for localization of software information files in portable media is immature, this has been deferred to a possible future revision of this Software Administration specification.
Until a future revision of this Software Administration specification addresses localization,
one recommended way to internationalize these attributes is to
create vendor-defined attributes with the format:
where keyword is "description.", "title", or "copyright",
and <LANG>
is the value of the
LANG
environment variable.
An implementation
should then recognize if
LANG
is set to a value other than its default and
search for a corresponding attribute.
If that attribute does
not exist, then the default one will be used.
For example:
Note that the
tag,
revision,
and other attributes that affect
the defined behavior of the implementation, shall not be
internationalized.
For this revision of this Software Administration specification, this
includes all defined attributes except
title,
description,
and
copyright.
The size for the software may be larger than that supported
by the POSIX.1
-
-
A1.003.01 < A.004.00 < B.000.00
A1_003_01 < A_004_00 < B_000_00
First < Second < Third
First < Fourth < Second
Historically, some implementations computed the value of instance_id sequentially, while other implementations have used an algorithm based on the product tag, vendor_tag, and the various machine type attributes. No implementation is specified, other than to guarantee that the tag and instance_id uniquely identify the product within the distribution or installed_software object. This is to make it easier to specify a particular product when there are other products sharing the same tag as would be the case when there are different product instances in a distribution for several machine types or multiple concurrent versions on a host.
The vendor_tag attribute is intended to be universally unique to distinguish product and bundle software objects that otherwise would be treated as the same object if the tag, revision, and architecture attributes were the same. Guaranteeing universal uniqueness is difficult at best, and no need was seen at present to cause the value of vendor_tag to be either some sort of machine-generated universally unique value or officially registered.
The
architecture
attribute should include information related to four
It is recommended that a set of guidelines be used for the architecture
attributes to maintain a consistent "syntax" for related architectures.
This increases the usability of this field for users selecting
software.
An example guideline is to order
any information contained in the value of the attribute
in a consistent way, separated by a consistent delimiter.
For example:
for a product with the attributes:
Another example is:
for a product with the attributes:
Product machine attributes describe the target
systems on which this product may be installed.
Each of these keywords
are related to a POSIX.1
If a uname attribute is undefined, the behavior is essentially the same as if it were defined to be * (meaning compatible with all systems).
The product directory for an application should be the directory that is
part of all paths in the product.
Thus, if an application has three
filesets that contain files below
/appl/console ,
/appl/agent ,
and
/appl/data
respectively, the
product.directory
attribute should be set
to
/appl .
If a user relocates the product with a command like:
then all three filesets have the same location attribute.
If the user relocates the product to three different locations:
then each fileset will have a different location attribute.
There will be three product instances containing the three filesets
(since products versions are distinguished by location), but the user
can still identify all three filesets as one with the specification:
Alternatively, the user could relate all these locations with the
same version qualifier, such as "q=current" as follows:
and subsequently identify all pieces with:
In general, a product with no preinstall or postinstall scripts is recoverable. However, if there are preinstall or postinstall scripts, then unpreinstall and unpostinstall scripts shall be provided if any steps need to be undone to support autorecovery.
There was an issue whether dependencies should be an attribute of a product. The following types of dependencies have been discussed:
The last three dependency types are not necessary if the first three types exist (which they do), since those dependencies can be specified in terms of the others. For example, if an entire product depends on a second product, then the second product can be defined as a dependency for all filesets in the first product.
The developers of this Software Administration specification recognized that numerous additional dependency requirements are possible, particularly for software updates. These may be handled via checkinstall scripts, and can be considered for future revisions of this Software Administration specification.
The intention behind the inclusion of the layout_version attribute within a product is that it be required if its value is different than that for its associated software_collection .
The bundle class does not have location or directory attributes. This is because software_specs within the bundles can refer to products with different default directory attributes or even products that have been relocated.
The vendor_tag attribute is intended to be universally unique to prevent naming clashes for similarly named products and bundles from different vendors. Guaranteeing universal uniqueness is difficult at best; it was deemed unnecessary at present to cause the value of vendor_tag to be either some sort of machine-generated universally unique value or officially registered.
The intention behind the inclusion of the layout_version attribute within a bundle is that it be required if its value is different than that for its associated software_collection .
The value of the
bundlecontents
attribute is not modified when a location is specified for a bundle,
allowing future resolutions of its contents to remain consistent.
For example, assume bundles "CAT" and "DOG",
and products "FOO" and "BAR",
all with directory attributes defined as "/":
When the bundle "CAT" is installed and relocated to
/cat, the following
objects are installed:
So, when resolving "CAT,l=/cat" in installed software, applying the proper locations to the software_specs in the contents will result in the same software_specs in the installed software.
Bundle definitions are only copied or installed when explicitly
specified since they are external to the product and not always
applicable to the use of the product installed.
The creator of a
product has no control over what bundles reference it.
For example, a
product may be a member of numerous bundles, and many of those bundles
will likely have nothing to do with the bundles and products chosen to
be installed.
Also, see
Bundles and subproducts have lists defining their contents that are always copied (.I contents is a static attribute). So, if a partial bundle or product is copied, the value of the contents attribute does not change. However, by comparing that attribute to what objects are actually installed, "completeness" of a bundle or subproduct can be determined.
At one point a fileset
class
attribute existed that could contain the value of recommended,
mandatory, or optional.
The attribute was removed because it was felt that this Software Administration specification could
not specify any behavior for the attribute.
Another way to handle recommended, mandatory, or optional filesets would be to create subproducts with tags of the appropriate names. Although this Software Administration specification does not specify any behavior based on the name of subproduct tag, a specific implementation could define behavior as an extension.
When there is a dependency on a software item that is the ancestor of a new software item, it is desirable for the standard to allow that new software item to meet that dependency. This is more complex than might initially be apparent, since dependencies and ancestor definitions involve ranges of revisions and other expressions. The working group felt a separate "supersedes" attribute might be a better solution, so explicit supersede control is separate from the ancestor/match_target functionality. Requiring supersedes to be fully qualified software specs only would help eliminate the "pattern-to-pattern" comparisons.
Patches do not have to supersede other patches in the same fileset. This allows "point" patching: separate patches that patch separate parts of the same fileset.
Patches that supersede all previous patches (cumulative patches) can be specified with a single software_spec if a patch strategy uses the same product and fileset tags, and an ascending revision numbering scheme.
-
-
supersedes product.fileset,r<revision
The compression_type attribute allows compressing and uncompressing of individual files during swcopy, and uncompressing during swinstall. The way in which an implementation uses this attribute is undefined, although the general thought was that this would normally be the name of a compression/uncompression routine with a simple interface.
An implementation should be flexible in locating routines specified by compression_type, utilizing any or all of the following:
No particular compression method is specified in the standard largely because the developers of this Software Administration specification saw no standard for file compression and did not want to specify all of the details of the compression methodology as part of this Software Administration specification. It was generally agreed that to achieve adequate interoperability, a single method of consensus should be supported by all implementations. It is likely that the format used by the gzip utility is appropriate for all implementations. Each implementation may support any number of other methods.
The interface to the compression routine was also left unspecified. It is recommended that input be taken from stdin and output be directed to stdout, that the routine operate with no option to imply compress, and that a -u option imply uncompress. However, specific compression routines may require more complex interfaces.
The group also considered archiving of compressed files, that is, concatenation or other combination into a single file. The main purpose of this would be to save cluster space on diskette distributions. It was finally decided that the risks for current standardization were too high - especially if an archive extended over more than one diskette - and the issue was left implementation dependent. In implementing this, there should be consideration of the following factors:
Finally, compression support for swpackage was considered, and deemed as unnecessary, since compression can be achieved by copying after packaging. But an implementation can easily add attributes to achieve this function.
Implementations running on operating systems that do not support a
POSIX.1 file system
can interpret the defined attributes in any appropriate way.
Any implementation can extend file attributes with additional attributes
appropriate to the file system in question.
To avoid confusion when defining new attributes for a particular file
system,
it might be best to prefix such attributes with a designator of the file
system.
An example, for a FAT file system, might be the attributes
FAT_Hidden
and
FAT_Readonly.
There was some debate whether the major and minor attributes are appropriate or not since there is no standard that specifies how these files are created. In addition, this Software Administration specification specifies that the serial distribution be in POSIX.1 cpio or tar format; however these attributes are biased towards tar format as opposed to cpio format.
Considered was a size file type (z ) that was removed in favor of the space control_file similar to SVR4. An implementation may choose to internally implement a size type or a separate size_file object to represent the data from this file.
The developers of this Software Administration specification considered an is_exclusive (directory) attribute that was removed due to objections that the utilities would remove files that they did not have recorded in their database. Also, this was not a common need, and can be implemented either as vendor extension or by having software fix script implement similar functionality.
There has been much discussion about compression being handled within the scope of this Software Administration specification. Currently there are ways that both implementations and individual software products can handle compression. Compression can be handled through cooperation of the source and target roles, if they are from the same implementation. Software vendors can choose to ship their files compressed and uncompress them as part of the postinstall script. They can add a space control_file to account for the extra space required.
A similar need would apply to other post processing, such as for ANDF files that are processed as part of postinstall or configuration.
Though it may be adequate for protecting against accidental damage, the existing POSIX.2 cksum is considered inadequate for virus protection. Implementations may wish to create additional vendor-defined attributes and utility behaviors for this purpose.
Each of the prerequisite or corequisite
dependency_specs
in the list is required to
resolve successfully in order for dependencies to be met.
Also, a
dependency_spec
can contain alternate
software_specs
separated by the
|
(vertical line) character
(see
There are files (particularly for OS software such as /etc/rc for SVR4 and autoexec.bat for DOS) that are modified between software update times. These may be termed modifiable files. Although OS modifiable files are slowly being replaced by mechanisms where applications can simply add their own requirements as separate read-only files in a particular directory, there currently would be some value in supporting features where modifiable files are compared with the original files to see what changes need to be applied during software updates. Actually implementing these changes is a more difficult problem since it requires knowledge of the formats of the files being updated. Similarly, reversing (during swremove) changes made to modifiable files (during swinstall and swconfig) is an exceedingly difficult problem. The existing practice for treating modifiable files is fairly ad-hoc. It was not feasible to address all of the possible needs for updating modifiable files. Instead, it does provide the attribute is_volatile for files that may be modified after installation, and leaves the rest of the treatment of modifiable files as either implementation defined, or handled in control scripts. This area may be considered for a future revision of this Software Administration specification.
Control files do not have mode, owner, group, uid, gid, and mtime attributes since they are not necessary for the execution of the control scripts or for the management of these files within the distribution or installed software catalog. However, an implementation shall ensure that they are executable.
The interpreter attribute has two uses. It is useful for those who choose not to use the POSIX.2 shell, that is, sh. It is also useful for systems that would not otherwise require POSIX.2. Those creating distributions and control files are encouraged to use the POSIX.2 shell for portability.
Related to the -s option, an implementation could define an additional source syntax to use well-known sources whose existence is available through some sort of directory service.
The -s option could be extended to supported multiple source specifications. There are several possible ways to interpret multiple sources, including searching sources sequentially, ignoring all specifications after the first one, using the last specification, or choosing the "best" source based on criteria such as performance or ability to reduce network load. It may even be desirable for multiple source specifications to be interpreted differently for different commands.
An implementation may implement the -p option (preview) by simply executing the command through the analysis phase. Alternatively, an implementation may emulate the execution phase, listing the operations that would occur, including listing control scripts that would be run, but not actually performing those operations. As preview is undefined, other alternatives are possible.
On the other hand, the two types of operands are the two key objects upon which the utilities operate. The syntax is valid according to the utility guidelines from POSIX.2 section 2.10 2. Distributed utilities extend the problem space that POSIX.2 has already addressed, thus the need for precedence might be less. Thus, it was decided that the @ was acceptable, and perhaps desirable over the alternatives.
One alternative was to move one or both operands to
options (such as
-S
for software and
-T
for targets).
But, it was felt that this was not necessary because
there are already
-f
and
-t
options for files containing lists of operands.
Another point was that listing target operands on the command line was
not critical in any case, as an administrator of many systems would
not use either the
@ targets
or
-T target
syntax.
Software Specification and Logic
Using a less formal grammar convention
that defines zero or one item by enclosing these items in
[]
(brackets) and zero or more repeated items in
{}
(braces),
the following shows a common subset of the
software_spec
syntax:
The keywords bundle, product, subproduct, and fileset refer to the tag attributes of those objects. The value of revision is usually a dot separated string compared to the value of the revision attribute of the first object. The values of architecture, vendor_tag, location, and qualifier are usually exact strings or patterns compared to the like-named attributes of the first object. These version attributes can validly be specified like revision is, but operators and multiple specifications do not make much sense.
Examples of
software_specs
are:
A software_spec shall begin with a bundle or product tag. A particular bundle or product object can be determined since they share the same name space (they also have different instance_id attributes).
The location attribute applied to the product means all filesets in that product in that location. This is the same set of filesets as if the location attribute was applied to the filesets.
Since the components of the version_qualifier of a bundle_software_spec refer to the attributes of bundle objects, there is no way to select one version of a product if more than one version is specified in the bundlecontents. Neither the inclusion of multiple versions of a product within a bundle, nor the specifying of partial bundles, is seen as the normal use model, so having this Software Administration specification limit the flexibility slightly in this area was deemed as acceptable.
This Software Administration specification permits the use of values other than those defined in
A possible syntax for these vendor extensions include, but are not limited to:
| ver_id | attribute | object |
|---|---|---|
| br | revision | bundle |
| ba | architecture | bundle |
| bv | vendor_tag | bundle |
| bl | location | bundle |
| pr | revision | product |
| pa | architecture | product |
| pv | vendor_tag | product |
| pl | location | product |
| fr | revision | fileset |
| fl | location | fileset |
The ver_id fr is seen as most useful since it can identify a particular fileset object within a product where the product may not have a revision, but the fileset does. Note however, that any object can still be identified with only the attributes defined in this Software Administration specification. For example, if a bundle includes two partial products with the same tag value but different revisions or locations, these partial products could be identified with the standard syntax by excluding the bundle portion of the software_spec. For example, bundle.product,pr=1.3 could also be identified by a software_spec of product,r=1.3.
In another example, the fileset that could be identified by its revision (product.fileset,fr=1.3) could also be identified by a software_spec (for example, product,r=revision), where revision refers to the product revision, including possibly the empty string.
Relocation occurs by replacing the
product.directory
part of each file path as it occurs in the distribution, with the
location
specified and using the resulting path for installation.
This is still relative to the installed_software directory described
below.
See
Using a sw_pattern in a software_spec is a way for the user to indicate that all software objects that match the software_spec are to be included. For example, applying the software_spec "*" to swcopy means to copy all software in the distribution. Applying the software_spec "Foo,*" to swremove means to remove all versions of Foo.
The behavior for swlist is different (by default including all software if none is specified) because this is the command that is used to find all versions of software, and because listing cannot negatively affect the state of the software_collection.
If using software pattern matching notation characters on the command line, they shall be escaped or enclosed in single quotes to avoid matching files in the current working directory.
This specification provides the means to select products and specify dependencies using a single syntax. The use of the shell-type pattern match specified in POSIX.2 section 3.13 allows for reasonable specification of sets of values that share such patterns. Thus, for example, a specification of "a=HP-UX*" may be used to select packages for any of a set of architectures. The specification using the relational operators provides support for testing the type of release/version specifications that are frequently used by vendors. In particular, it provides support for testing when a numeric test is needed (for example, comparing 2.9 to 2.10 as version levels of a product). Additional operators such as >> were considered. The specification of the >> operator allows the user to specify the selection of the most recent (highest version number) of a set of otherwise identical packages. This exposes to the interface the mechanism used by swinstall to select such a package.
The range of attributes that may be specified allows for selection of packages that may be needed to support code serving to alternate architectures, or other operating environments. In addition, it provides the needed support to specify installed software that may only be distinguished by the location of installation.
Examples of fully-qualified
software_specs
are:
It is possible for bundles to contain software_specs that are not fully-qualified. This is not recommended for bundle definitions provided by software vendors because the results of operations on this bundle may be undesirable for an administrator. However, there is some flexibility provided by ambiguous software specs that administrators may want to use.
For example, a bundle with contents "*.Man" could be used to manipulate all "Man" filesets or subproducts in all products.
If a vendor includes any wildcards in a software_spec in a bundle definition, then the vendor_tag attribute should be included and its value should have no wildcards, thus limiting the scope of the pattern matching.
The difference between "FOO,v=" and "FOO" is that the first will only match a product or bundle "FOO" where vendor is not defined, while the second will match a product or bundle "FOO" with any vendor definition.
-
-
software_collection_spec : [ host ] [ ':' ] [ path ]
Examples of distribution
software_collection_specs
are:
Examples of installed_software
software_collection_specs
are:
Target distributions in the serial format need not be supported for swverify, swremove, and swmodify as this requires the implementation to unload the entire distribution, merge in the changes, then reload it. The user can accomplish this (and an implementation can implement this) by first copying the distribution into a directory format, implementing the changes, then copying the distribution back to the serial media. This operation also could require significant temporary disk space.
A similar rationale applies to swcopy, and swpackage, which by default, overwrite the existing distribution instead of merging in the specified software.
The 1387.2 developers considered the difference between "system-level" defaults and "site-level" defaults.
The former is provided by the implementation of the utilities and the latter is constructed by the administrator. The intent here is for the implementation to respect any customizations to the system level defaults file, so it can be used for site policies. It is recommended that implementations "hard code" the defaults as opposed to relying on the system file containing all definitions, and provide a means to support new options in future releases without changing the site specific values in the system defaults file.
The swinstall utility, and other utilities that operate on installed_software, modify the catalog information based on the outcome of the utility. Information contained within the catalog is resolved in the context of each target.
Originally, it was thought that a catalog would be kept as a flat file in a directory that could be specified using this option. In the interest of generality, so that implementors might be allowed to use databases, the catalog attribute is now described as a key. This allows an implementor to either use a flat file or a database or some other form of persistent storage for the information, yet still be able to separate the address space as desired. The motivation for permitting the separate address space stems from the following two cases. First, it seems desirable to allow ordinary (non-root) users to be able to use swinstall to store software in their own private space. Likely the only real restriction is a potential lack of write authority to the central storage for the catalog, hence the ability to create a separate catalog. This also allows a user to manage personal software with utilities such as swremove or other utilities. Second, installations may wish to deploy stable versions of their software in the normal location, and a test version installed in a second location where access may be more tightly controlled. There may even be other versions installed that are under development. Since this software may have identical attributes, it is desirable to allow such separate space for management. Both of these examples show the need for separate domains of software management.
Two values of autoselect_dependencies (.I "autoselect_dependencies=true" and autoselect_dependencies=as_needed) support different possible policies by the user. Having autoselect_dependencies=true ensures that all targets are kept in sync, while having autoselect_dependencies=as_needed prevents the possibility of updating dependency software to a higher revision unnecessarily.
Autoselection of a dependency across products is possible if a compatible
product version with the highest revision that meets the dependency is
unique.
In other words, the same rules apply for dependency selection as
for normal selection as described in
For the ask option, the checkinstall and configure scripts are required to detect needed response files when they are necessary, and return with the appropriate warning or error.
For the installed_software_catalog option, the catalog and the directory together form a key to identify one installed_software object. For example, this would allow the files on the file system to be split up into different management domains. For example, OS software, networking software, and application software could be in three different logical installed_software objects, although they are all installed under the root file system.
%token FILENAME_CHARACTER_STRING /* as defined in 2.2.2.37 */
%token NEWLINE_STRING /* as defined in 2.2.2.61 */
%token PORTABLE_CHARACTER_STRING /* as defined in 2.2.2.68 */
%token SHELL_TOKEN_STRING /* as defined in 2.2.2.80 */
%token WHITE_SPACE_STRING /* as defined in 2.2.2.110 */
%start sysadmin_option
%%
Notes:
-
-
$ cc -O -g x.c
$ cc: warning 414: Debug and Optimization are mutually exclusive.
-g option ignored.
$ cc -g -O x.c
$ cc: warning 414: Debug and Optimization are mutually exclusive.
-O option ignored.
It might be convenient to have a mechanism to allow the system administrator to define a default in the system defaults file that cannot be overridden by a user. Such a function may be supplied by an implementation as an extension. This may also be considered as part of a future revision to this Software Administration specification.
If the catalog is stored in a file, then a corresponding ability to create an installed_software object (and thus, a catalog) is needed.
Access control includes such things as requiring particular authority to operate on particular software or software_collections. Concurrency control is the prevention of more than one writer at a time to the catalog or data areas. Restrictions to prevent multiple concurrent writers were originally part of the draft, but later determined to be excessively restrictive. It is conceivable that more than one writer could safely be active at a time if the work involves no common files. Failure to allow multiple concurrent readers of the catalog, or other data files, is strongly discouraged.
There are two aspects to access control as follows:
For access control to the files themselves, this Software Administration specification defaults to the file permissions defined by POSIX.1. File attributes are defined for the files, hence the implementation will set the POSIX.1 file permissions based on those values. Deviations from this model are permitted only for implementations running on file systems that are not POSIX.1 conformant, and then only as long as the implementation documents the resulting behavior.
Any additional access control to the software objects defined in this Software Administration specification (for example, permission to install specific software into specific software collections on specific hosts), is undefined. An implementation may choose to have no access control. For example, anyone may install any software to any system as long as the previous POSIX.1 file permissions are satisfied. An implementation may also choose to provide both authorization and authentication for access to all software objects and hosts, as well as a distributed interface for managing the access control lists.
Like the definition of the model to implement distributed aspects of this standard, access control beyond that required by the underlying operating system is undefined. It was determined that both of these rely on technologies that have not been formally standardized, and may better be addressed in other forums.
The restrictions placed on the option syntax are such that each of the
options can be easily parsed and hence set by a control script by
simply sourcing the file.
The term "sourcing" as used here implies the use of the "." command
in the POSIX.2 shell.
For example, the following are formats for
the SW_SESSION_OPTIONS file that can be sourced:
It is possible for the scripts to determine the loglevel for the command from the file pointed to by SW_SESSION_OPTIONS, and use that to affect the amount of stdout generated.
An implementation may have an implementation-defined user controllable behavior that invokes error handling procedures in the case of warnings returned from script execution.
The purpose of the environment variables is to pass vital information to the scripts so that they may operate appropriately under different circumstances. For example, they may want to take very different actions when SW_ROOT_DIRECTORY is some value other than /. It has also been discussed that there may need to be some way to pass other information to these scripts such as option values specified in the defaults and options file that control policy. This can be achieved with the SW_SESSION_OPTIONS variable, which points to a file containing all the options passed to the command, including options, selections, and targets.
The developers of this Software Administration specification also discussed, but did not include, the use of several of these variables for setting the value of specific utility options when the utilities are called from control scripts. These variables are as follows:
The scripts need to be aware of the environment under which they are operating. The environments that these scripts run under are as follows:
Each script shall be passed its script tag, the root directory to which installing, the product directory where the product is located, and the control directory where the script is being executed from, as the environment variables SW_CONTROL_TAG, SW_ROOT_DIRECTORY, SW_LOCATION, and SW_CONTROL_DIRECTORY, respectively.
The install and remove scripts are run when loading or removing the software, or when recovering from a failed install. These may be executed by swinstall or swremove running on a host with a different architecture from the software. So, only the set of POSIX.2 utilities are guaranteed to be available on the server. Since the architecture of the file server is not necessarily known, the path to these commands is passed to the scripts via the environment variable SW_PATH.
It is expected, but not assumed, that these scripts mostly
check the state of a system that will actually run the software.
For the install check (checkinstall)
script, again only a minimum set
of commands is guaranteed to be available.
This is because all check scripts are executed before any new software
is installed.
These scripts configure the system for the software. Therefore they can run architecture specific commands, including files that are part of the software that defines the scripts. They are only run within the context of the system that will actually use the software. The SW_ROOT_DIRECTORY will always be /.
This is the only script that may be interactive. This script may be run by swask, swinstall, or swconfig after selection, and before the "analysis" phase in order to request information from the administrator that will be needed for the configure script when that script is run later.
This script is executed on the manager role and it is the responsibility of the script to write all information into the response file in the directory where the script is being executed (the SW_CONTROL_DIRECTORY). The utilities will then copy this file to the SW_CONTROL_DIRECTORY on the target role where the configure and other scripts are executed from. This response file may be used by any other scripts, but particularly the configure script.
A recommended syntax for the
response
file is a set of attribute-value
pairs that can be easily sourced by the
configure
script.
For example, a
request
script might look like the following:
and the using
configure
script:
The response file is generated by the request script and located in the same directory as that and the other scripts. The format and content of the response file is vendor defined. For example, it may be a list of environment variable definitions so that the consumer script can just source this file.
This script is run by
swinstall
during the "analysis" phase in an attempt to ensure
that the installation (and configuration) succeeds.
This script is run by swinstall prior to loading the software files. For example, this script may remove obsolete files, or move an existing file aside during an update.
This script and the next script are part of the "load" phase
of the software installation process.
This script is run by swinstall after loading the software files. For example, this script may move a default file into place.
This script is run by swinstall before restoring the software files if the postinstall script has been run. It can be used to undo the actions of the postinstall script.
This script is only run by swinstall after restoring the software files if the preinstall script has been run. It can be used to undo the actions of the preinstall script.
This script is run by the swverify command any time after the software has been installed or configured. Like other scripts it is intended to verify anything that the commands do not verify by default. For example, this script may check that the software is configured properly and has a proper license to use it.
This script is run by the swverify command when the -F option is used. Its purpose is to correct any problems reported by the verify script.
The remove check script is run by swremove during the remove "analysis" phase to allow any vendor-defined checks before the software is permanently removed. For example, the script may check whether anyone is currently using the software.
This script is executed just before removing files. It may be destructive to the software being removed, as removal of files is the next step. It is the companion script to the install postload script (postinstall). For example, it may remove files that the install postload script created.
This script is executed just after removing files. It is the companion script to the the install preload script (preinstall). For example, if this was a patch fileset, then the install preload script may move the original file aside, and this remove postload script may move the original file back if the patch was removed.
This script is executed by swinstall after all software has been installed (including loading files and running postinstall scripts) if software is being installed at /. It is also may run by swconfig, even if the software has already been configured (allowing the administrator to reconfigure software).
This script is executed by swremove before any software is removed (including removing files and running preremove scripts), if removing from software installed at /. It is may also be run by swconfig.
The vendor may include other control scripts, such as a script that is sourced by the above scripts, or scripts not defined in this Software Administration specification. The location of the control scripts is passed to all scripts via an environment variable SW_CONTROL_DIRECTORY.
A implementation that supports additional behaviors may initiate those behaviors based on implementation-defined return values from control scripts.
The stdout, stderr, and logfile output should contain the severity of the event
as part of the output message.
For example:
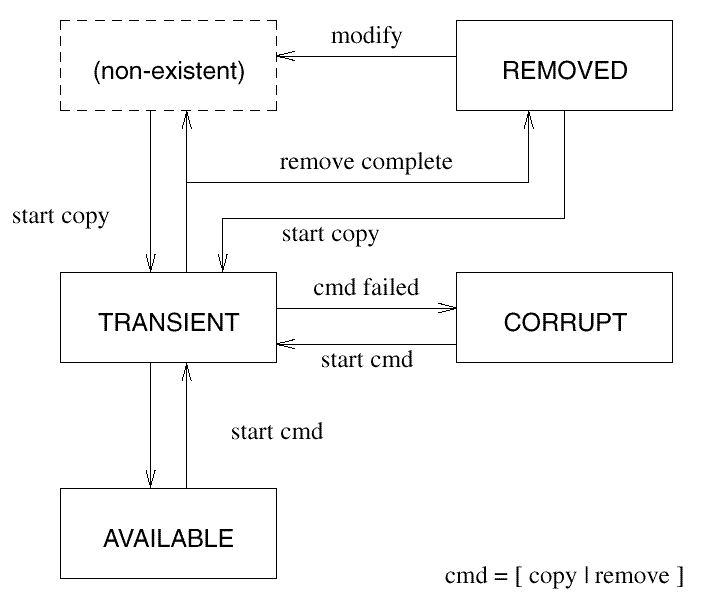
It is clear that some vendors may want additional states. But allowing other values would make it problematic for any implementation trying to make decisions on how to deal with filesets with unrecognized states. An implementation may create an additional fileset attribute that would further modify the meaning of the attribute. For example, they may create an attribute called state_info and this attribute may have the value of files_missing when the state attribute is set to corrupt. There could be several valid values of this new attribute to describe various possibilities of a corrupt state. Of course, since this would be an implementation-specific extension, other implementations would not need to recognize this attribute or its semantics.
The default for updating, downdating or removing a fileset is to remove the information from the catalog. However, implementations may instead set these filesets to have a state of removed.
The default behavior for filesets in the
removed
state is
the same as for filesets that are "non-existent". Implementations
that
support the
removed
state should define extensions to the POSIX
utilities providing operations on removed filesets.
For example:
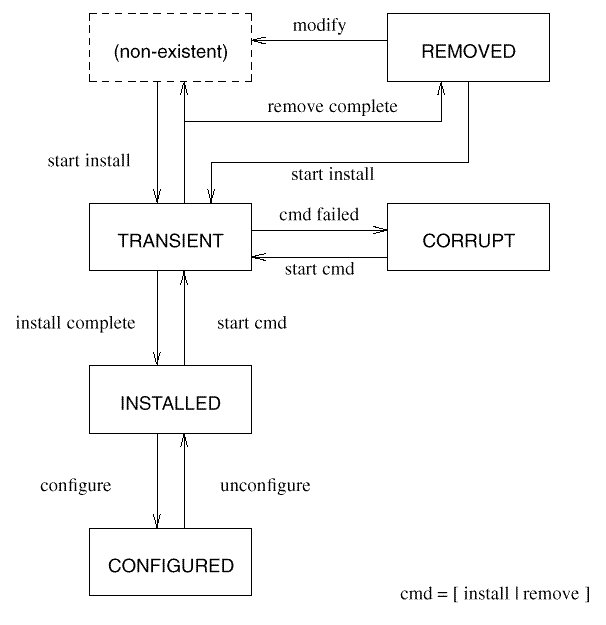
The reason for specifying a standard software packaging layout is to allow for interoperable media. In other words, any conforming distribution may be read by any conforming implementation.
This layout does not dictate how the software files are actually located in the file system. The layout provides a portable means to store and distribute files for any file organization. Installing could involve a transformation from a canonical form to one that conforms to the requirements of the architecture of the machine on which the software is to run.
The software catalog refers to the information (metadata) that describes software objects in a particular distribution or installed software object. Each catalog describes exactly one software_collection (installed_software object or distribution).
The information in the software catalog may be created, altered, and removed using the utilities defined in this Software Administration specification. A system administrator may use swlist, for example, to obtain a list of installed software products, the shell scripts used for installing a product, or the files contained within a product.
Each system has a default catalog for installed_software. This catalog provides information on the products installed for use on that system. Permission to modify the catalog may be restricted to the system administrator. Since there are times when users without special privileges may wish to use software administration tools to install and maintain software in their parts of the file store, additional installed_software objects, in separate software catalogs, may be created and acted upon by any user having appropriate authority.
The way that installed_software catalog information is stored (whether kept in text files or databases, whether distributed or centralized), is undefined within this Software Administration specification.
An example of product control directory name follows. If a product with the tag attribute value of SDU is added to a distribution, and no other objects with the same value of tag exist, the product_control_directory for storing the product object is SDU/. If another product object with the tag SDU is added to the distribution, the product_control_directory for that product object is SDU.2/. The first SDU product was assigned the value of 1 for its productinstance_id.
In the PSF, attributes may be undefined or set explicitly unless their default value is none. Most attributes have a default value. Default values are logically required for attributes that may be optionally specified in the PSF.
Most Boolean attributes default to false, such as is_reboot, is_kernel, and is_locatable. Instead of defaulting all Boolean attributes to false through clever wording of the attribute tag, some default to true, such as is_locatable.
In the PSF, the < (less than) is a token for unambiguous parsing, but it does not imply that the file contents should be included (that is, file re-direction). The alternative is to take the file from that path on the development system and store it as a control_file (for example,for example, a copyright control_file containing that attribute).
The extended file definition syntaxes provide a flexible interface to individual software vendor development and build systems. These build systems may contain files to be packaged existing anywhere from intermingled with source files to a target build tree containing the files in the locations they would be in after installation.
The following examples illustrate the use of the directory and file keywords:
-
-
directory /build/s /opt/sw
file *
-
-
directory /build/s /opt/sw
file bin/swinstall
file -t h bin/swinstall bin/swcopy
file -t d lib/nls
file nls/swinstall.cat lib/nls/swinstall.cat
file data/swinstall.defaults newconfig/defaults/swinstall
file data/swinstall.defaults /var/adm/sw/defaults/swinstall
-
-
file /build/s/bin/swinstall /opt/sw/bin/swinstall
file -t h /opt/sw/bin/swinstall /opt/sw/bin/swcopy
file -t d /opt/sw/lib/nls/
file /build/s/nls/swinstall.cat /opt/sw/lib/swinstall.cat
-
-
directory /build/s /opt/sw
file *
file bin/swinstall
file -t h bin/swinstall bin/swcopy
file data/swinstall.defaults newconfig/defaults/swinstall
file data/swinstall.defaults /var/adm/sw/defaults/swinstall
The following examples illustrate the use of the file_permissions keyword:
-
-
file_permissions -m 444
-
-
file_permissions -u 222
-
-
file_permissions -u 222 -o bin -g bin
-
-
file_permissions -u 222 -o 2 -g 2
-
-
file_permissions -u 022 -o 2 -g 2
If the user defines no
file_permissions,
swpackage
uses the default value:
for destination file objects based on existing source files. This means that the mode, owner/uid, and group/gid are set based on the source file, unless specific overrides are specified for a destination file.
The default value:
is used by swpackage for destination file objects being created (not based on existing source files).
If neither the path nor any attributes is specified,
then the suggested default values of the attributes are:
These are only suggestions, since the default values in this case are implementation defined.
The
space
file is used to account for disk space used (positive size) or
freed (negative size) by control script execution.
Negative sizes may be used by a more sophisticated disk space analysis
that accounts for transient as well as final disk space.
For example, if a fileset has a
configure
script that creates a 200 KB file
/usr/foo/data/file,
it can include a
space
file with the entry:
This will tell the implementation to add 200 KB to the disk space
requirements.
If the
configure
script moves a 35 KB file from
/etc/file
to
/sbin/bin,
it could include the entries:
An implementation may choose to ignore the negative entry, producing a
"worst case" disk space requirement.
Alternatively, the implementation may choose to
list the "worst case" requirement (ignoring the negative entry,
reflecting the transient disk space required), and then the final disk
space (accounting for the negative entry).
Finally, if a
configure
script created a temporary 5 MB file under
/tmp,
it could add the entries:
The following are examples for "update packaging":
-
-
file -t x /oldfile
This adds a remove file to the fileset definition. It gives the software packager explicit control over which files to remove (useful if any of the files from previous revisions were user configurable).
-
-
product
tag NEWPROD
fileset
tag NEWFILESET
ancestor OLDPROD.OLDFILESET,r=10.0
This designates NEWPROD.NEWFILESET to be included in the list of filesets generated by the match_target option to swinstall if OLDPROD.OLDFILESET has been installed.
-
-
product
tag NEWPROD
fileset
tag NEWFILESET
supersedes OLDPROD.OLDFILESET,r=10.0
This designates that installing NEWPROD.NEWFILESET will result in removing the catalog information for OLDPROD.OLDFILESET.
A unique product revision must be specified for a patch fileset if that patch has the same product tag and fileset tag as the fileset it is patching.
If this is the first patch of any particular patch stream, then it does not need a supersedes attribute. This is true for all original point patches. If this patch replaces one or more other patches, then it must specify the appropriate supersedes attribute.
All patch software objects with the is_patch attribute automatically have the built-in patch category included in the list of category_tags.
A fileset that has the is_patch attribute will not update a fileset with the same tag as is done with normal filesets. In the case of filesets with is_patch set to true, the "revision" is now a version distinguishing attribute at the fileset level.
The category_tag and is_patch attributes at all other levels of software objects besides fileset are for display and selection purposes only. These attributes are not version distinguishing attributes.
The 1387.2 developers discussed whether patch verification capabilities could be defined that might help the quality of patches, but concluded that this would be outside the scope of their task.
-
-
file -t a -a /usr/lib/foolib.a /build/newfile.o \
/usr/lib/newfile.o
file
type a
archive_path /usr/lib/foolib.a
source /build/newfile.o
path /usr/lib/newfile.o
Separate archives on each medium allows the swinstall utility to only request the needed medium (via the media_sequence_number), without having to scan each one sequentially. The rule concerning a fileset being in one archive is needed so the swinstall utility knows whether to request the next medium when it reaches the end of the current archive.
Additional files besides just those for the distribution may be needed on distributions. For example, a software vendor may want to include a copy of the swinstall utility on the media.
| Contents | Next section | Index |