Ecosystems Architecture
New Thinking for Practitioners in the Age of AI
by Philip Tetlow, Neal Fishman, Paul Homan, and Rahul
Copyright © 2023, The Open Group
All rights reserved.
No part of this publication may be reproduced, stored in a retrieval system, or transmitted, in any form or by any means, electronic, mechanical, photocopying, recording, or otherwise, without the prior permission of the copyright owners.
The top right image in Figure 6 is sourced from https://commons.wikimedia.org/wiki/File:7_bridges.svg, and is licensed under the Creative Commons Attribution-Share Alike 3.0 Unported license. For details of the license, see https://creativecommons.org/licenses/by-sa/3.0/deed.en.
{kind=link}
The Open Group Press
Ecosystems Architecture
Document Number: G23B
Published by The Open Group, October 2023.
Comments relating to the material contained in this document may be submitted to:
The Open Group, Apex Plaza, Forbury Road, Reading, Berkshire, RG1 1AX, United Kingdom
or by electronic mail to:
ogspecs@opengroup.org
Built with asciidoctor, version 2.0.18. Backend: html5 Build date: 2023-10-27 07:06:30 +0100
Preface
The Open Group Press
The Open Group Press is an imprint of The Open Group for advancing knowledge of information technology by publishing works from individual authors within The Open Group membership that are relevant to advancing The Open Group mission of Boundaryless Information Flow™. The key focus of The Open Group Press is to publish high-quality monographs, as well as introductory technology books intended for the general public, and act as a complement to The Open Group standards, guides, and white papers. The views and opinions expressed in this book are those of the authors, and do not necessarily reflect the consensus position of The Open Group members or staff.
The Open Group
The Open Group is a global consortium that enables the achievement of business objectives through technology standards. Our diverse membership of more than 900 organizations includes customers, systems and solutions suppliers, tools vendors, integrators, academics, and consultants across multiple industries.
The mission of The Open Group is to drive the creation of Boundaryless Information Flow™ achieved by:
-
Working with customers to capture, understand, and address current and emerging requirements, establish policies, and share best practices
-
Working with suppliers, consortia, and standards bodies to develop consensus and facilitate interoperability, to evolve and integrate specifications and open source technologies
-
Offering a comprehensive set of services to enhance the operational efficiency of consortia
-
Developing and operating the industry’s premier certification service and encouraging procurement of certified products
Further information on The Open Group is available at www.opengroup.org.
The Open Group publishes a wide range of technical documentation, most of which is focused on development of standards and guides, but which also includes white papers, technical studies, certification and testing documentation, and business titles. Full details and a catalog are available at www.opengroup.org/library.
About the Authors
Philip Tetlow, PhD, C.Eng, FIET, is CTO for Data Ecosystems at IBM (UK & Ireland) and a Distinguished IT Architect in The Open Group Open Professions program. He is a one-time Vice President of IBM’s Academy of Technology, a W3C member, a Visiting Professor of Practice at Newcastle University and an Adjunct Professor at Southampton University.
Neal Fishman, BSc, is an IBM (US) Distinguished Engineer and a Distinguished IT Architect in The Open Group Open Professions program. He is a former distance learning instructor at the University of Washington. He has written several published works, including Enterprise Architecture Using the Zachman Framework, Viral Data in SOA: An Enterprise Pandemic, and Smarter Data Science: Succeeding with Enterprise-Grade Data and AI Projects.
Paul Homan, MSc, CITP, FBCS, is the CTO for the Industrial Sector in IBM Services (UK & Ireland). He is an IBM Distinguished Engineer and Distinguished IT Architect in The Open Group Open Professions program. With over 30 years’ experience in IT, he is highly passionate about and practically experienced in Architecture & Strategy; in particular, as applied to the Industrial sector. He is well known for applying an Architected Approach to delivering strategic business transformation, and has been a long time contributor to The Open Group, significantly in relation to the TOGAF Standard.
Rahul, MCA, BSc, is a Senior Research Engineer for the Emerging Technology Lab at Honda R&D Europe UK. He primarily focuses on deep tech strategy, data privacy, and decentralized architecture research for next-generation systems and services.
Contributors
The authors gratefully acknowledge the following contributors:
Steve Nicholls, BSc, is the Account Technical Lead Manager at DXC Technology (UK). He is skilled in Digital Strategy, IT Strategy, Data Center Management, and Project Portfolio Management.
Mark Dickson, BA, is the Architecture Forum Director at The Open Group. He is an experienced Chief Architect, Enterprise Architect, and expert in Agile delivery.
Christopher Hinds, MEng, CEng (Mech), is Head of Enterprise Architect for Applications at Rolls-Royce PLC. He has been with the company since 2006 and worked across Engineering, Manufacturing, and IT. Chris sits in Group IT and works in an ecosystem of more than 20 Enterprise Architects and more than 30 third parties influencing architectural direction.
Stuart Weller, BSc, is an Enterprise Architect at Rolls-Royce PLC. He is TOGAF® 9 Certified and is responsible for Enterprise Architecture standards.
Trademarks
ArchiMate, FACE, FACE logo, Future Airborne Capability Environment, Making Standards Work, Open O logo, Open O and Check certification logo, OSDU, Platform 3.0, The Open Group, TOGAF, UNIX, UNIXWARE, and X logo are registered trademarks and Boundaryless Information Flow, Build with Integrity Buy with Confidence, Commercial Aviation Reference Architecture, Dependability Through Assuredness, Digital Practitioner Body of Knowledge, DPBoK, EMMM, FHIM Profile Builder, FHIM logo, FPB, IT4IT, IT4IT logo, O-AA, O-DEF, O-HERA, O-PAS, O-TTPS, Open Agile Architecture, Open FAIR, Open Footprint, Open Process Automation, Open Subsurface Data Universe, Open Trusted Technology Provider, Sensor Integration Simplified, SOSA, and SOSA logo are trademarks of The Open Group.
Betamax is a trademark of Sony Corporation.
Box is a registered trademark of Box, Inc.
Facebook is a registered trademark of Facebook, Inc.
Forrester is a registered trademark of Forrester Research, Inc.
Gartner is a registered trademark of Gartner, Inc.
Google is a registered trademark of Google LLC.
IBM is a registered trademark of International Business Machines Corporation.
JavaScript is a trademark of Oracle Corporation.
McKinsey is a trademark of McKinsey Holdings, Inc.
MDA, Model Driven Architecture, and UML are registered trademarks and Unified Modeling Language is a trademark of Object Management Group, Inc.
Mural is a registered trademark of Tactivos, Inc.
Python is a registered trademark of the Python Software Foundation.
Twitter is a trademark of Twitter, Inc.
VHS is a trademark of the Victor Company of Japan (JVC).
W3C and XML are registered trademarks of the World Wide Web Consortium (W3C®).
WhatsApp is a trademark of WhatsApp LLC.
YouTube is a registered trademark of Google LLC.
Zachman Framework is a trademark of John A. Zachman and Zachman International.
All other brands, company, and product names are used for identification purposes only and may be trademarks that are the sole property of their respective owners.
Acknowledgements
The foundations for this book were laid down by a project under the auspices of the IBM Academy of Technology. Accordingly, the founding members of that project must be credited, with a specific mention going to John H Bosma, William Chamberlin, Scott Gerard, Carl Anderson, and Richard Hopkins. Their kind input significantly helped incubate the ideas in this book.
Next, we must thank Mark Dickson, who worked tirelessly to steer our team within The Open Group as we captured and composed our thoughts while writing.
We are also indebted to James Hope, who helped implement and test some of our ideas on homology in Chapter 3.
Finally, we must thank the late Ian Charters, Grady Booch, and Professor Barrie Thompson for their inspiration, support, and encouragement over the years. They are the ones who set the compass.
Foreword
Simply stated; it is time!
In other words, we are at a point where both business and Information Technology (IT) communities must establish practices designed to embrace the various ecosystems upon which their enterprises depend.
A pragmatic place to start is with architecture; specifically, IT architecture aimed at the ecosystems level — at the hyper-enterprise level, as it were, and with an ambition to augment informal practice already in place in and around Enterprise Architecture. This comes from domains like Electronic Data Interchange (EDI), Information Retrieval (IR), Generative Artificial Intelligence (GenAI), and Blockchain, and covers ideas not yet consolidated or formalized — as is the case with Enterprise and/or Systems Architecture.
So, let us start with a caveat. Ecosystems Architecture, as presented here, is an additive discipline to that of Enterprise Architecture, meaning that Ecosystems Architecture is not intended to replace or compete with that discipline. On the contrary, the work of an Enterprise Architect is seen as a necessary pathway, or even a prerequisite, toward becoming an Ecosystem Architect, by drawing upon skills already mastered.
The business side of the enterprise has eternally relied on the broader support of its surrounding ecosystems. To that end, ecosystems and ecosystems thinking are nothing new. What is new, however, is the recognition that IT architecture can play an instrumental role in how ecosystems and the enterprise interact. Hundreds of universities around the world already offer courses containing an ecosystems element. For instance, majors can be obtained in Supply Chain Management, Logistics, and so on. Yet, while optimization is often covered in these programs, the role of IT architecture in that optimization is not. IT architects, therefore, have invariably played a passive role when organizations think in terms of the world around them.
That needs to change.
Why? Simply because today’s enterprises swim in the sea that is the global digital ether, and without the support of the dynamic electronic connections around them, they would drown. As a case in point, the supply chain crisis brought about by COVID mortally wounded many organizations who were blasé about their extended digital dependence. It thereby quashed any fallacy of ecosystems being extraneous to mission-critical business concerns. So, if “being digitally extended” is considered to be important, then Ecosystems Architecture and the role of Ecosystems Architects must also be seen as imperative. In saying that, and as an aside, it is important to note that although global data exchange protocols, like TCP/IP, EDI X.400, and NIEM, have been successfully used for years, and although they may indeed be part of any Ecosystems Architect’s kitbag, Ecosystems Architecture should not be considered synonymous for any or all of them. Its scope is far greater, with a broad affinity to Enterprise Architecture — while being distinctively different.
All of this means that Ecosystem Architects must sit alongside their business counterparts as their organizations build out in their surrounding ecosystems. This, of course, requires an eye to the technologies involved, and the support of unbiased, systematized, and standardized practice.
As an example of bias, naïve organizations often make the mistake of believing that they live at the epicenter of their customer and supplier networks. This is rarely, if ever, the case as Ecosystems Architecture is keen to point out. Not only does centrality skew an organization’s worldview, but it can serve to restrict its opportunities. This is important because, as the grander context of business scales and becomes more complex, retaining objectivity will become ever more important. Aspiring to create a discipline that can transcend the reach of personal and organizational viewpoints was, therefore, the primary motivation behind the push for Ecosystems Architecture as a distinct and discrete discipline.
Neal Fishman
Distinguished Engineer, IBM
Prologue
History and Background
“Problems cannot be solved at the same level of awareness that created them.” — Albert Einstein
We are still amid a technological epoch. Not since the harnessing of steam power have we seen such a change. During the Industrial Revolution, innovation moved from small-scale artisan endeavor to widespread industrialization, which started the upward spiral of globalization and eventually spat out an ever-expanding network of effective electronic communications. In short, rapid technological advances began to catapult human potential beyond its natural limits as the 20th century dawned.
As the world’s communication networks expanded, and our brightest minds connected, the take-up of applied know-how became transformative. So much so, that by the end of the 20th century, technology in general had irrefutably changed the course of history. As a key indicator, and even taking into account deaths due to war and conflict — rounding off at around 123[1] million [1] — our planet’s population grew three times faster than at any other time in history, from 1.5 to 6.1 billion souls in just 100 years [2].
But amid all that progress, one episode stands out.
As the demands of World War II pushed the world’s innovators into overdrive, a torrent of advance ensued. Where once crude equipment had proved sufficient to support mechanization, sophisticated electronic circuits would soon take over as the challenges of war work became clear — challenges so great that they would force the arrival of the digital age.
Whereas previous conflicts had majored in the manual interception and processing of military intelligence, by the outbreak of war in 1939, electronic communications had become dominant. Not only were valuable enemy insights being sent over the wire, but, with the earlier arrival of radio, long-distance human-to-human communications were literally in the air. World War II was, therefore, the first conflict to be truly fought within the newly formed battlegrounds of global electronic communication.
Warring factions quickly developed the wherewithal to capture and interpret electronic intelligence at scale. That advantage was coveted throughout the war and long after. That and the ability to harness science’s newest and most profound discoveries. Both provided the impetus for unparalleled advance, as security paranoia gripped the world’s political elite. On the upside came the rise of digital electronics and the whirlwind of information technology that would follow, but in parallel, we developed weapons of mass destruction like the atomic and hydrogen bombs.
At the heart of it all was information and kinship, in our voracious appetite for knowledge and the unassailable desire to find, share, and protect that which we hold true. Nowhere in human history will you find better evidence that we are a social species; all our surrounding computers and networks do today is underline that fact. Grasping that will be key to understanding the text to follow. For instance, as a race, we have often advanced by connecting to maximize our strengths and protect our weaknesses; whether that be how we hunt mammoth, build pyramids, or create our latest AI models. This is the tribe-intelligence that has bolstered our success and welcomed us in the onward march of technology to augment our strengths and protect our weaknesses. It speaks to the fact that evolution cannot be turned back and, likewise, neither can the advance of any technology that catalyzes or assists its progress. Information technology will always move forward apace, while the sprawling threads of the world’s networks can only ever extend to increase their reach.
These things we know, even though we might poorly distill and communicate the essence of the connected insight they bring. What is certainly lesser known, though, is what ongoing impact such expansion and advance will have on professional practice, especially since future technological advances may soon surpass the upper limits of God-given talents.
As technologists, we wear many hats. As inventors, we regularly push the envelope. But as architects, engineers, and inquisitors, we are expected to deliver on the promise of our ideas: to make real the things that we imagine and realize tangible benefit. In doing so, we demand rigor and aspire to professional excellence, which is only right and proper. But in that aspiration lies a challenge that increasingly holds us back: generally, good practice comes out of the tried and tested, and, indeed, the more tried and tested the better.
But tried and tested implies playing it safe and only doing the things that we know will work. Yet how can such practice succeed in the face of rapid advance and expansion? How can we know with certainty that old methods will work when pushing out into the truly unknown, and at increasing speed?
There can only ever be one answer, in that forward-facing practice must be squarely based on established first principles — the underlying tenets of all technological advances and the very philosophical cornerstones of advancement itself, regardless of any rights or wrongs in current best practice.
So, do any such cornerstones exist? Emphatically yes, and surprisingly they are relatively simple and few.
Scale and Complexity
As we become more proficient with a tool or technology, we largely learn how to build bigger and better things with it. Be they bridges, skyscrapers, or Information Technology (IT) solutions, their outcomes largely become business as usual once realized. What really matters though, is that the tools and techniques used for problem-solving evolve in kind as demand moves onward and upward. For that reason, when a change in demand comes along, it is normally accompanied by an equivalent advance in practice, followed by some name change in recognition. For instance, IT architects talk of “components”, whereas Enterprise Architects talk of “systems”. Both are comparable in terms of architectural practice but differ in terms of the scale and abstraction levels they address. In that way, IT architecture focuses on delivering IT at the systems level, whereas Enterprise Architecture is all about systems of systems.
Interestingly, the increases in scale and complexity that brought us Enterprise Architecture were themselves a consequence of advances in communications technology as new network protocols catalyzed progress and expanded the potential for connectivity — so that a disparate IT system could comfortably talk to another disparate IT system. Nevertheless, boil the essence of this progress down and only two characteristics remain: the scale at which we choose to solve problems, and the levels of complexity necessary to successfully deliver appropriate solutions.
That is it. In a nutshell, if we can work from a base of managing scale and complexity, then the selection of tools and techniques we use becomes less important.
Considering the lesser of these two evils first, in recent times, we have become increasingly adept at tackling complexity head-on. For instance, we now understand that the antidote to complexity is the ability to abstract. As more and more complexity is introduced into the solutions we build, as professionals we simply step back further in order to squeeze in the overall perspectives we need. We therefore work using units of a “headful”, as the architect Maurice Perks [3] once said — any solution containing more than a headful of complexity [4] needs multiple professionals in attendance. As we step back, detail is obviously lost as the headful squeezing happens, even though we admirably try to apply various coping techniques, like dissecting out individual concerns and structuring them into hierarchies, ontologies, or whatever. But today, that is mostly fine as we have learned to employ computers to slurp up the fallout. This is the essence of Computer Aided Design (CAD) and the reason why tools like Integrated Development Environments (IDEs) have proved so successful. Complexity, therefore, is not a significant challenge. We mostly have it licked. Scale, on the other hand, is much more of a challenge.
In simple terms, the difficulty with asking the question “How big?” is that there is theoretically no upper limit. This happens to be a mind-bending challenge, especially given that the disciplines of architecture and engineering are built on the very idea of limits. So, before we can build anything, at least in a very practical sense, we must know where and when to stop. In other words, we must be able to contain the problems we want to solve — to put them in a mental box of some kind and be able to close the lid. That is the way it works, right?
Well, actually … no, not necessarily. If we were to stick to the confines of common-or-garden IT architecture and/or engineering then perhaps, but let us not forget that both are founded on the principles of science and, more deeply, the disciplines of mathematics and philosophy in some very real sense. So, if we dared to dive deep and go back to first principles, it is surely relevant to ask if any branch of science or mathematics has managed to contain the idea of the uncontainable? Are either mathematics or philosophy comfortable with the idea of infinity or, more precisely, the idea of non-closable problem spaces — intellectual boxes with no sides, ceilings, or floors?
Not surprisingly, the answer is “yes” and yes to the point of almost embarrassing crossover.
Philosophy, Physics, and Technology at the Birth of the Digital Age
For appropriate context, it is important that we take a historical perspective. This is important stuff, as hopefully will become clear when ideas on new architectural approaches are introduced later, so please bear with the narrative for now. This diversion ultimately comes down to not being able to understand the future without having a strong perspective on the past.
As Alan Turing, the father of modern-day computer science, passed through the gates of Bletchley Park for the last time at the end of World War II, he was destined to eventually go to Manchester, to take up a position at the university there. Contrary to popular belief, he had not developed the world’s first digital computer at Bletchley, but the team around him had got close, and Turing was keen to keep up the good work. Also contrary to popular belief, Turing had not spent the war entirely at Bletchley, or undertaken his earlier ground-breaking work on logic entirely in the UK. Instead, he had found himself in the US, first as a doctoral student before the war, then as a military advisor towards its end. His task was to share all he knew about message decryption with US Intelligence, once America had joined with the Allied forces in Europe.
On both his visits, he mixed with rarefied company. As a student at Princeton University, for instance, he would no doubt have seen Albert Einstein walking the campus’s various pathways, and his studies would have demanded the attention of the elite gathered there. So rarefied was that company, in fact, that many of Turing’s contemporaries were drafted in to help with the atomic bomb’s Manhattan Project, as the urgency of war work wound up in the US. Most notably on that list was the mathematician and all-round polymath John von Neumann, who had not only previously formulated a more flexible version of logic than the Boolean formulation [5] central to Turing’s ground-breaking work, but had captured the mathematical essence of quantum mechanics more purposefully than anyone else in his generation. That did not mark him out solely as a mathematician or a physicist though. No, he was more than that. By the 1940s, von Neumann had been swayed by the insight of Turing and others, and had become convinced of the potential of electronic computing devices. As a result, he took Turing’s ideas and transformed them into a set of valuable engineering blueprints. This was ground-breaking, fundamental stuff, as, for instance, his sequential access architecture is still the predominant pattern used for digital processor design today.
As for his ongoing relationship with Turing, fate would entangle their destinies, and in the years following World War II, von Neumann and Turing’s careers would overlap significantly. Both worked hard to incubate the first truly programmable electronic computers, and both became caught up in the brushfire of interest in nuclear energy. Von Neumann’s clear brilliance, for instance, unavoidably sucked him into the upper workings of the US government, where he advised on multiple committees, several of which were nuclear-related, while Turing’s team nursed its prototype computer, the “Baby”,[2] on funds reserved for the establishment of a British nuclear program. Both, therefore, survived on a diet of computing and nuclear research in tandem, but what resulted was not, strictly speaking, pure and perfect.
For sure, Turing and von Neumann understood the base principles of their founding work better than anyone else, but both were acutely aware of the engineering limits of the day and the political challenges associated with their funding. So, to harden their ideas as quickly and efficiently as they could, both knew they had to compromise. As the fragile post-war economy licked its wounds and the frigid air of the Cold War swept in, both understood they had to be pragmatic to push through their ideas; it was not the time for idealism or precision. Technical progress, and fast technical progress at that, was the order of the day, especially in the face of a growing threat of a changing geopolitical world.
For Turing, that was easier than for von Neumann. His model of computing was based on the Boolean extremes of absolute and complete logical truth or falsehood: any proposition under test must be either completely right or wrong. In engineering terms, that mapped nicely onto the idea of bi-pole electrical switching, as an electronic switch was either on or off, with no middle ground. Building up from there was relatively easy, especially given the increasingly cheap and available supply of electronic bi-pole switches and relays in the form of valves. So, many other engineering problems aside, the route to success for Turing’s followers was relatively clear.
The same was not true for those ascribed to von Neumann’s vision, however. In his mind, von Neumann had understood that switches can have many settings, not just those of the simplest true/false, on/off model. Instead, he saw switching to be like the volume knob on a perfect guitar amplifier; a knob that could control an infinite range of noise. This was a continuous version of switching, a version only bounded by the lower limit of impossibility and the upper limit of certainty. The important point though, was that infinite levels of precision could be allowed in between both bounds. In von Neumann’s logic, a proposition can therefore be asserted as being partly true or, likewise, partly false. In essence then, von Neumann viewed logic as a continuous and infinite spectrum of gray, whereas Turing’s preference was for polarized truth, as in black or white.
In the round, Turing’s model turned out to be much more practical to build, whereas von Neumann’s model was more accommodating of the abstract theoretical models underlying computer science. In that way, Turing showed the way to build broadly applicable, working digital computers, whereas von Neumann captured the very essence of computational logic at its root. He, rather than Turing, had struck computing’s base substrate and understood that the essential act of computing does not necessarily need the discreet extremes at the core of Boolean logic.
Computing, von Neumann had realized, could manifest itself in many ways. But more than that, by establishing a continuous spectrum of logic, his thinking mapped perfectly onto another domain. In what was either a gargantuan victory for serendipity or, more likely, a beguiling display of genius, von Neumann had established that the world of quantum mechanics and the abstract notion of computing could be described using the same mathematical frameworks. He had, therefore, heralded what the physicist Richard Feynman would proclaim several decades later:
“Nature isn’t classical, dammit, and if you want to make a simulation of nature, you’d better make it quantum mechanical…” [6]
Relevance to IT Architecture and Architectural Thinking
This, perhaps perplexing, outburst would turn out to be the clarion that heralded the rise of quantum computing, and although it may have taken some time to realize, we now know that the quantum paradigm does indeed map onto the most foundational of all possible computational models. It is literally where the buck stops for computing and is the most accommodating variant available. All other models, including those aligned with Turing’s thinking, are merely derivatives. There is no further truth beyond that, full stop, end of sentence, game over.
But why this historic preamble, and specifically why the segue into the world of quantum?
If you look broadly across the IT industry today, you will see that it is significantly biased toward previous successes. And for good reason — success builds upon success. For instance, we still use von Neumann’s interpretation of Turing’s ideas to design the central processing units in most of the world’s digital computers, even though we have known for decades that his more advanced vision of computing is far broader and more inclusive. Granted, state-of-the-art quantum computing is still not quite general purpose yet, or ready for mainstream, but the physical constraints dominant at the atomic level mean that the sweet spot for quantum will always be more focused than widespread. But regardless, that should not limit our thinking and practice. Only the properties carried forward from computation’s absolute ground truths should do that, and not any advantage that has been accrued above them through the necessities of application.
And that is a significant problem with IT architecture today. Like most applied disciplines, it is built from a base of incremental application success, rather than a clear understanding of what is possible and what is not. In other words, the mainstream design of IT solutions at both systems and enterprise levels has been distracted by decades of successful and safe practice. To say that another way, we rely heavily on hands-on tradition.
Engineers and architects of all kinds may well be applauding at this point. “If in doubt, make it stout and use the things you know about” is their mantra, and that is indeed laudable to a certain point. Nevertheless, as we seek to push out to design and build IT systems above enterprise scale, out into the era of hyper-Enterprise Architecture as it were, the limits of tried-and-tested are being pushed. In such a world, we may plausibly need to model billions of actors and events, all changing over time and each with a myriad of characteristics. And that takes us out into an absolute headache of headfuls worth of complexity.
Where, in the past, the scale and complexity of the IT systems we aspired to design and build could be comfortably supported by the same hands-on pragmatic style favored by Turing, as he steered toward the nascent computers of a post-war world, we are no longer afforded such luxury. The demands of today’s IT systems world now lie above the levels of such pragmatism and out of the reach of any one individual or easily managed team. No, the game has changed. Now, we are being forced to move beyond the security afforded by reductionist[3] approaches [7], in the hope that they might yield single-headful victories. This is therefore a time to open up and become more accommodating of the full spectrum of theory available to us. It is the time to appreciate the kick-start given by Turing and move on to embrace the teachings of von Neumann. This is the age where accommodation will win out over hands-on pragmatism. It is a time to think brave thoughts. Professional practice has reached a turning point, whether we like it or not.
Even our most respected experts agree [8]. Take Grady Booch [9] for instance, one of the inventors of the Unified Modeling Language™ (UML®) and one of the first to acknowledge the value of objects [10] [11] in software engineering. He openly talks in terms of three golden ages of architectural thinking.[4] The first, he suggests, was focused on algorithmic decomposition, invested in the translation of functional specifics into hand-written program code. In other words, the manual translation of rule systems into machine-readable forms dominated. Then, as Paul Homan [12] suggests, came the realization that ideas could be encapsulated and modeled independently of any underlying rules systems or data structures. While fed on the broadening out of use cases [13], that provided the essence of the second age, which saw the rise of object and class decomposition and in which, it might be argued, abstraction and representation broke free — so that architectural thinking need not focus exclusively on code generation. It also forked work on methodologies into two schools. The first embraced the natural formality of algorithms and therefore sought precision of specification over mass appeal. Today, we recognize this branch as Formal Methods [14], and its roots still run deep into mathematical tradition. For the design of safety-critical IT systems, like life support in healthcare or air traffic control, formal methods still play a vital role.
Alongside, however, came something much freer, more intuitive, and much more mainstream.
Feeding on the innate human preference for visual communication, and with a nod to the, then fashionable, use of flowcharts in structured thinking, a style of methodological tooling emerged that linked various drawn shapes together using simple lines. This gave birth to the world of Semi-Formal Methods, which still dominates IT architecture and software engineering practice today, and within which can be found familiar tooling favorites, like the UML modeling language and the TOGAF® Enterprise Architecture framework [15] — which have both served IT professionals well for decades.
The third age, however, as Grady advocates, is somewhat different from what has gone before, wherein we now do not always explicitly program our machines, but rather teach them [8]. This step-change comes from the advent of new technologies, like Generative Artificial Intelligence (GenAI) [16], Large Language Models (LLMs) [17], and significantly-sized neural networks [18], and sees human experts partially replaced by machine-based counterparts. In saying that, however, it is important to remember that the “A” in AI does not necessarily always stand for “artificial”. It can also stand for “augmented”, in that synthetic assistants do not so much replace human function, but rather enhance it. The third age is therefore about both the replacement and enhancement of professional (human) practice, especially in the IT space. AI therefore allows us to abstract above the level of everyday work to focus on the augmentation of practice itself. In that way, we can now feed superhuman-like capabilities directly into human-constrained workflows. The hope is that these new superpowers might, in some cases at least, outstrip the limits of natural human skill to help make the once intractable tractable and the once unreachable reachable. So, in summary, this next-gen momentum is as much about providing antidotes to complexity and scale in IT systems as it is about advancing the fields of IT architecture and software engineering. In the age-old way, as with all technologies and professional practices, as they mature they become optimized to the point where complexity and unpredictability are effectively negated.
All that said, there is no need to feel a sense of impending doom, as much progress has already been made. For instance, well-established areas of practice now exist, not too distant at all from the traditional grounds of IT architecture, and which have already successfully ventured out far beyond the limits of the headful. These, and their various accompanying ideas, will all be introduced as the threads of this book come together. As a note to those set on reading this text, it should hopefully be fascinating to understand that these ideas are both old and established. They are the stuff of the conversations that held IT’s early pioneers together, only to be resurfaced anew today.
Even though the rats’ nest of connected technology around us today might not feel very quantum or von Neumann-like at surface inspection, stand back and quite the opposite should become clear. En masse, the overpowering complexity and scale of it all buzzes and hums above us, not at all unlike the apparent randomness inherent to every single atom involved. To capture that essence and bottle it is the key to future progress. That, and an acute appreciation of just how different the buzzing is in comparison to the familiar melodies of systems and Enterprise Architecture.
Widening the Lens — The Road to Ecosystems Architecture
As the digital age dawned, associated benefits were small and localized at first. In the world of commerce, for instance, it was soon realized that business accounts could be processed far faster by replacing human computers with electronic counterparts. Likewise, customers and suppliers could be herded with a simple phone call. It was all a matter of optimizing what was familiar and within the confines of well-established commercial practice. Beyond that, it was perhaps, just perhaps, about pushing norms to experiment with the new electronic trickery. Out of that came new business, and eventually whole new industries were spawned; the reach of the planet’s networks kept expanding, slowly finding their way into every nook and cranny of big business.
What came next was a forgone conclusion. Soon, it became clear that individuals, families, and communities could connect from far-flung places. That is what we do as a social species. It is in our nature. And so, too, this skill ascended to business level. Economics and the sheer intoxication of international opportunity took over, and the race to adopt and adapt began.
By the 1980s, desperate to keep up, many business leaders began to breach the boundaries of their traditional businesses and start to wrestle with the ultra-high-scale, complexly connected communications networks emerging around them. Some might have seen this as innovation in the wild, but, to others, it was nothing more than an emergence born out of the Internet’s arrival. Whichever way, the resulting mass-extension of commercial reach shifted the balance of business as the new century arrived. The slithering beast of the Internet Age was out of its shell, writhing and hissing as the walls of enterprise fell around it. Business emphasis had shifted. No longer was there a need for enterprise-centricity. It was about hyper-enterprise now. Where once systems of business dominated, now it was about ecosystems.
From an IT architecture perspective, this prompted talk of systems of systems theories and even sociotechnical networks, and all without so much as a nod from the professional standards community. Regardless, grass-roots interest flourished and the term Ecosystems Architecture first appeared in positioning papers [19] [20] [21] somewhere between 2014 and 2019, although the concepts involved had likely been in circulation long before that.
Looking back, it is possible to remember the rise in interest just before objects and Object-Oriented Design (OOD) were formalized in the 1980s. At that time, many professionals were thinking along similar lines and one or two were applying their ideas under other names, but, in the final analysis, the breakthrough came down to a single act of clarity and courage, when the key concepts were summarized and labeled acceptably. The same was true with Enterprise Architecture. By the time the discipline had its name, its core ideas were already in circulation, but practice was not truly established until the name itself had been used in anger. Thus, in many ways, naming was the key breakthrough and not any major change in ideas or substance. And so it is today. As we see the ideas of Enterprise Architecture blend into the new, the name Ecosystems Architecture will become increasingly important going forward, as will the idea of hyper-enterprise systems and third-age IT architecture.
This should come as no surprise. Enterprise Architects have been familiar with the idea of ecosystems for some time and the pressing need to describe dynamic networks of extended systems working toward shared goals. Such matters are not up for debate. What is still up for discussion, though, is how we establish credibility in this new era of hyper-enterprise connectivity.
1. From Enterprise to Ecosystem
“To infinity and beyond!” — Buzz Lightyear (Disney, Toy Story)
Look up the term (enterprise) ecosystem in any dictionary and you will likely find something like this[5]:
ec·o·sys·tem / eko-oh-sis-tuhm
Noun
Origin: 1935
1. A community of organisms together with their physical environment and interdependent relationships
2. A complex network or interconnected system
An ecosystem is a complex web of interdependent enterprises and relationships aimed at creating and allocating business value.
Ecosystems are broad by nature, potentially spanning multiple geographies and industries, including public and private institutions and consumers [22].
Frustratingly, such multifaceted descriptions make it hard to pin down a concise definition. Furthermore, the online dictionary Dictionary.com does not help, by also revealing that the word “enterprise” can have multiple meanings. It nevertheless settles to broadly summarize its account as:
“a company organized for commercial purposes [23].”
The definition at Merriam-Webster.com does somewhat better, however, by helpfully prompting suggestions as shown here:
enterprise / en-tə-ˌprīz
Noun
1. A project or undertaking that is especially difficult, complicated, or risky
2. a: A unit of economic organization or activity, especially a business organization
b: A systematic, purposeful activity, as in: “agriculture is the main economic enterprise among these people”
In essence, the idea of “enterprise” also presents as a synonym for “business organization”, and so, as Information Technology (IT) architects, we invariably apply the term “enterprise” to mean all the business units, or identifiable high-level functions, within an organization. Each business unit, therefore, provides a specialization within the construct of an enterprise.
By implication then, an enterprise ecosystem totals as an extended network of enterprises (or individuals) who exchange products or services within an environment governed by the laws of supply and demand [24], and where each enterprise contributes some form of specialization. This becomes a scalable element and provides a core repeatable pattern that is common across both Enterprise and Ecosystems Architectures alike. Also, by implication, the idea of business organization does not restrict how, when, where, or what commerce takes place; ecosystems in an enterprise context can be broad by nature, potentially spanning multiple geographies and industries, including public and private institutions and consumers. This means that ecosystems share many of the characteristics found in markets, so that participants [24]:
-
Provide a specialized function, or play out a specific role
-
Can extend activities or interactions through their environment
-
Present a set of capabilities of inherent value to their environment
-
Are subject to implicit and explicit rules governing conduct within their environment
-
Facilitate links across the environment connecting resources like data, knowledge, money, and product
-
Regulate the speed and scale at which content or value is exchanged within the environment
-
Jointly allow the admittance and expulsion of other participants into the environment
This leads to systems of mutual cooperation and orchestrations, as self-interest averages out into a network of self-support based on communal survival; participants relinquish any desire for dominance by understanding that more value can be gained through external coordination and collaboration. In short, team spirit wins. This leads to mutuality in the formal or informal sharing of ideas, standards, values, and goals, and synchronization, in that enterprises formally or informally engage in coordinated communication and the sharing of resources.
Concrete examples of such ecosystems are becoming increasingly easy to find, especially with the rapid rise of the service economy [25] [26] [27] [28] [29]. For instance, healthcare providers in the US now regularly orchestrate health insurance, hospitals, and physicians to provide integrated support for their customers, with one particular enterprise now connecting over nine million healthcare members with physicians, doctors, and medical centers. Likewise, a major retailer in Sweden now coordinates store operations, supply chain, real estate development, and financial services across 1,300 stores throughout the country [24].
This evolution in business models is being driven by a need to match or exceed customer expectations — as emerging technologies grow more distributed, powerful, and intelligent — and the global mindset shifts rapidly. This should hopefully be self-evident. As where, in 1969, the first moon landing was achieved with less computing power than a pocket calculator, today the average cell phone user has privileged access to cloud-based resources that would have made even the world’s most successful organizations jealous just a few short years ago. What is more, as advances in technologies like Artificial Intelligence (AI) accelerate, they serve to mask the complexity of the IT systems behind them. This lowers the barriers to entry and welcomes those hitherto excluded. It incrementally empowers consumers (sometimes to enterprise-like status) and draws them away from enterprises that cannot keep up. What results is increased competition and a race to the bottom for organizations unwilling or unable to embrace the reality of an increasingly connected world. This has been supported by reports as far back as 2015, which predicted that “53% of executives plan to reduce the complexities for consumers even as technological sophistication increases” [30].
Advancing technology also serves to blur the boundaries between what is physically real and what is virtual, as the digital-physical mashup [31] of products and services helps to increase value and catalyze seamless customer experiences. Indeed, many enterprises are already working hard to remove organizational boundaries between their digital and physical channels, with 71% of executives believing that ecosystem disruption is already a dominant factor in consumers demanding more complete experiences going forward [32]. Likewise, 63% of executives believe that new business models will profoundly impact their industries [32]. Many organizations are therefore being nudged to expand beyond their core competencies, and are forming deeply collaborative partnerships. These can be more extreme and dependent than any traditional customer-supplier relationship, specifically because of the need for mutual commercial survival.
All of this is further heightened by changing attitudes among regulators and legislators. Long gone are the days of “set and forget” IT strategy. Take the European Union (EU) General Data Protection Regulations (GDPR) [33], for example, which mandates that individuals must have access and control over their personal data; a key proposition which is taken further by the EU Data Act [34] [35], and which demands fair access and use of data generated through services, smart objects, machines, and devices. This not only points to opportunities for multi-party data sharing, but also creates ongoing pressure for both IT strategy and IT architecture to keep eroding barriers to technology access — to prevent things from mashing up further, as it were.
1.1. Scale, Structure, and Human-Centric Purpose
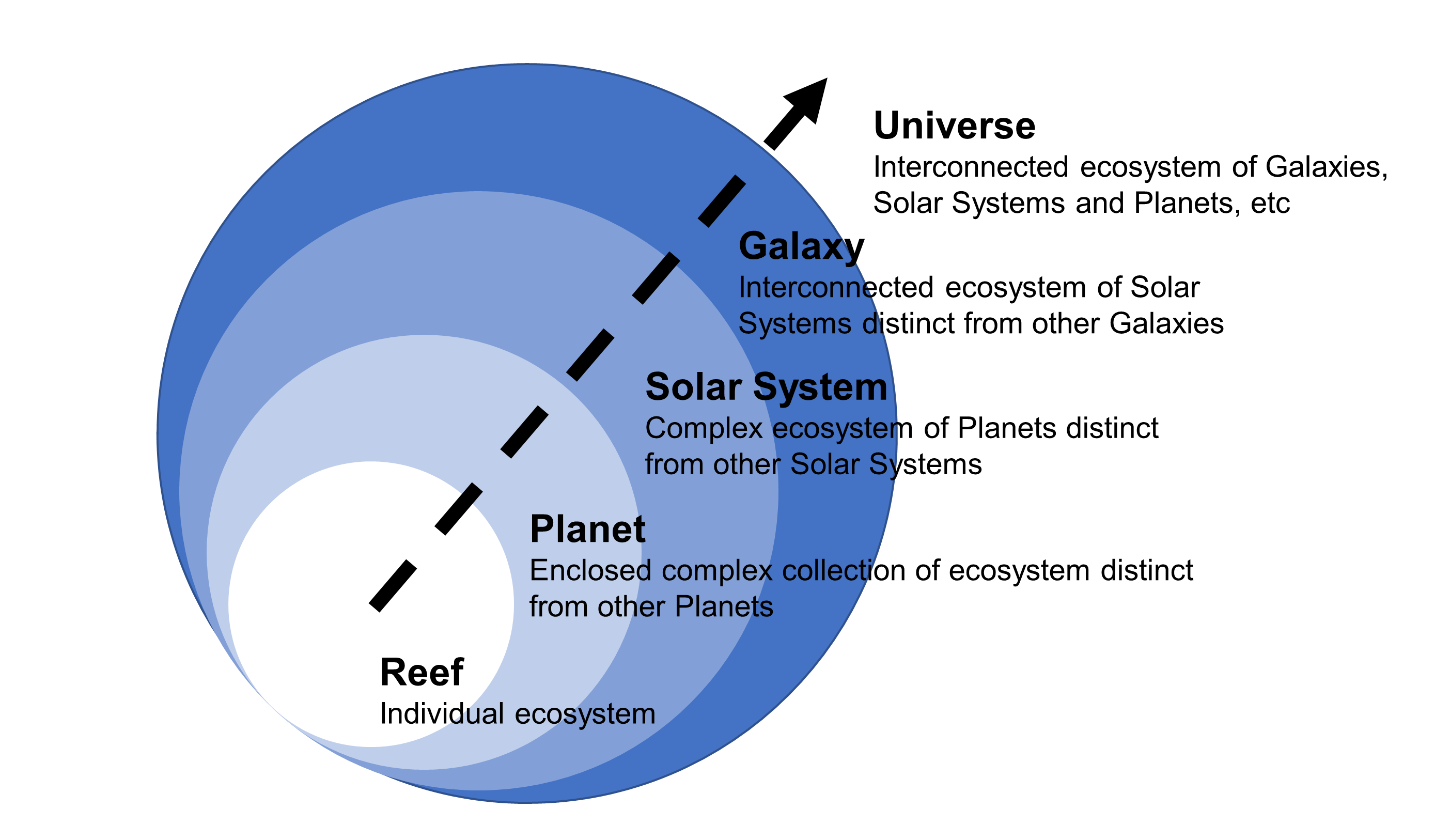
Ecosystems can also be recursive in their structure and reach, so it is often hard to understand where one ends and the other begins. As such, it is perfectly valid to speak in terms of ecosystems of ecosystems, where one or several may be embedded into others. Consequently, participants can be part of one or many ecosystems while playing out multiple evolving roles. Likewise, the purpose of any single ecosystem may well be directed toward a single purpose, whereas others might legitimately focus on multiple agendas. Nevertheless, purpose will always be targeted in support of some underlying human-centric[6] need, with examples of broad categories including:
-
Sustenance (Air, Food, Water, etc.)
-
Shelter, Dwelling, Home, and Town (including supporting civil infrastructure)
-
Energy, Resources, and Sustainability
-
Safety, Security, and Protection
-
Health, Wellbeing, and Fitness
-
Mobility and Transport
-
Rest and Recovery, Comfort
-
Community, Relationships, Family and Friends
-
Entertainment and Leisure
-
Education and Learning
-
Novelty and Innovation
-
Learning, Development, and Education
-
Equality, Justice, and Peace
-
Information Exchange and Communication
-
Trade and Finance (including Make and Supply)
-
Personal Fulfillment
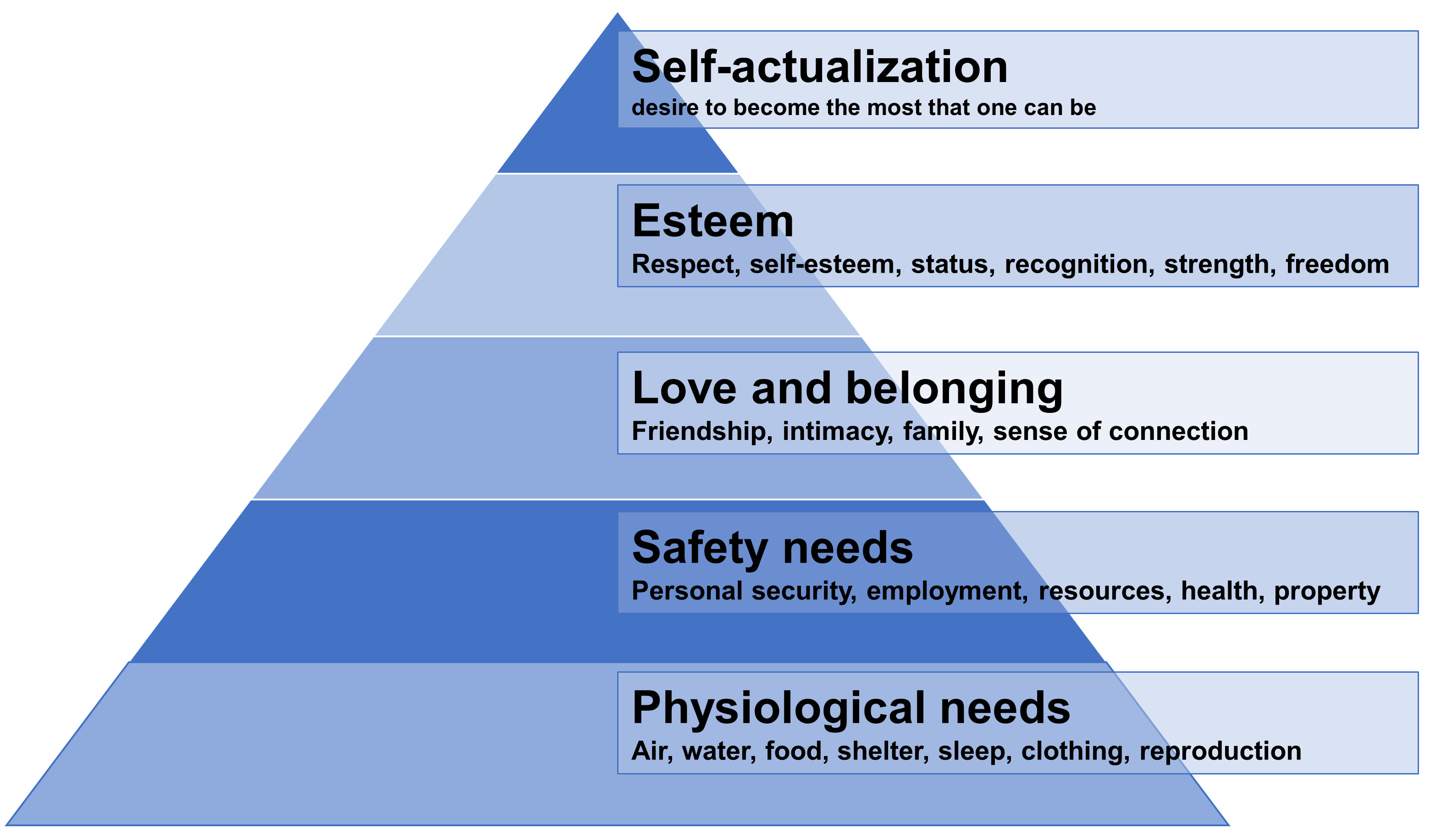
Such categories fall in line with many recognized models of psychological and social behavior and are also strongly influenced by the 2015 United Nations (UN) Sustainable Development Goals [36]. Relevant models include Abraham Maslow’s Hierarchy of Needs [37], which provides a hierarchy of motivational drivers associated with the human condition, covering everything from basic survival instinct up to personal enlightenment, belief systems, and beyond.
1.2. Sociotechnical Systems
Models like Maslow’s Hierarchy of Needs nicely highlight the symbiotic relationship between human and machine in an enterprise ecosystem world. As such, they act as a cornerstone in a broad field of study focused on how people and technology merge to form Sociotechnical Systems (STS) in the modern world. The ideas behind Sociotechnical Science [38] [39] can therefore be directly overlaid to help frame the notion of enterprise ecosystems in terms of IT architecture. This is because they succinctly sum up how the various actors, elements, and constraints involved can meld into one singular whole. An enterprise ecosystem can further be seen as:
“The emergent summation of a self-organizing network, or networks, composed of human-centric participants, be they individuals, groups, enterprises, or organizations, the technologies they use, the information at their disposal, and the environment in which they all co-exist. In such arrangements, connections between constituent parts (artifacts) can therefore be explicit, through either direct communication or integration, or implicit, as in being more osmosis-like, where connections are transient, implied, inferred, or informal.”
Participants and/or constituents (artifacts) in a sociotechnical ecosystem, therefore, make use of technologies, information, and resources provided to and from other participants and/or constituents and their environment, and provide and receive reciprocating feedback as a natural response. Together, both participants and/or constituents and their environment create a system of dynamically evolving parts and properties that often display episodes of convergence, diversification, and extinction in much the same way as experienced in diversely natural ecosystems.
Enterprise ecosystems, therefore:
-
Are networked-based
-
Often have poorly defined, nondescript, or permeable boundaries, both at local and global levels
-
Dynamically change over time for reasons of singular or mutual benefit
-
Scale in ways that can create extremely large and complex communication structures, without compromising local and/or global integrity
-
May behave differently within local regions
-
Are often self-organizing and do not require explicit coordination across local command-control structures
1.3. Within a Hairsbreadth of Enterprise?
Although the idea of working with IT above enterprise-level might feel daunting at first, the parallels between Enterprise and Ecosystems Architecture can be quite striking, especially when it is considered that the delineation between the two may often be just about how we formalize the boundaries involved. For instance, it could plausibly be proposed that what we perceive as an enterprise is, actually in practice, nothing more than a small, self-contained ecosystem, and that the principal differences between Enterprise and Ecosystems Architecture are simply about scope, complexity, and scale. In other words, where we establish any boundaries of discourse or closure.
Enterprise Architecture, therefore, simply corresponds to a hypo-enterprise[7] mindset, whereas Ecosystems Architecture is predominantly hyper-enterprise[8] aligned.
On the surface then, the idea of an enterprise, as a legal entity at least, generates a singularity that just makes sense — even when considering that such entities emerge out of a collective of business or mutually beneficial functions. Cumulatively these amass solidity around corporate identity and higher-level purpose, and so exhibit external alignment, continuity, and a general lack of internal friction — while under the covers, individual functions may well be jostling for position or even partaking in all-out war. You may, of course, disagree, exclaiming that the enterprises you have worked with are nothing like that in practice. But hopefully, you get the point. As a model and as a generalized architectural pattern, enterprise implies a oneness inherited by the use of a term that is singular in nature and which masks the plurality of its form as a series of lesser business units, in its connected internal areas of specialization or function. As such, we might conclude that because an enterprise is composed of such units, it is actually an ecosystem in its own right; an ecosystem manifesting from a networked clustering of specializations. Thus, any enterprise must impose the boundary for its internal ecosystem, based on the footprint of its legal identity. Likewise, any enterprise ecosystem can be considered as a similarly closed, connected, and whole continuum, only this time accommodating higher levels of abstraction than at the enterprise-level. As a result, Ecosystems Architecture encompasses group types like domains, regions, communities, or colonies of enterprises (or lower abstraction constituents), and above that whole ecosystems, worlds, or universes as types for singular compound entities at or above the notion of the individual enterprise. In that way, Ecosystems Architecture simply extends the recursive hierarchy of abstraction, categorization, and containment formed when Enterprise Architecture positioned itself above the level of systems architecture.
With that in mind, ask yourself how many times you have heard the sentiment that all IT-based features or functions should be aligned with the business? Perhaps you yourself have even presented such an argument? That is because the very nature of architectural practice in IT is to work toward a definition of enterprise that appears, both internally and externally, to be seamlessly in line with commercial and legal intent, rather than just a patchwork of specialized functions, stovepipes, or silos, all individually contributing piecemeal. This is, of course, interesting from an ecosystems perspective, simply because the removal of any demarcation between silos should be aligned with how an enterprise, or more specifically its business and legal intent, is actually composed, rather than how it is perceived to be set up or directed. As such, any intent to align IT with the enterprise, or its surrounding ecosystem(s) should be handled carefully, as it could first be construed as rhetoric prone to misaligned thinking, and second, it could serve to create unnecessary friction between IT and the purpose it seeks to serve.
1.4. Attributes and Components, then up through Systems and Enterprises, Followed by Nodes
Whereas IT architects perceive the world in terms of functions, attributes, and so on contained within components, Enterprise Architects do the same in terms of components within systems. So that begs the question: what should Ecosystems Architects trade in?
Because of the breadth and scale of the ideas requiring representation at the ecosystems level, categorization and containment must be handled in a very generic way — granted there is the issue of scale and the fact that ecosystems can have a recursive nature, it is, therefore, counterproductive to use competing sets of definitions at differing levels of abstraction. Instead, Ecosystem Architects will likely need to talk in terms that are agnostic of scale, abstraction, and complexity. This leads to the cover-all idea of representation via nodes; with a node simply providing a generic way to describe either a single idea or thing worthy of mention, or, likewise, a collection of either or both, and regardless of level of scale, abstraction, or complexity involved.
An Ecosystem Architect will, therefore, take these nodes and correlate them to clusters, domains, regions, communities, colonies, enterprises, systems, components, aspects, attributes, or whatever and at suitable abstraction levels, as needed. In that way, nodes can be typed according to whatever features require representation, and then connected to produce whatever coherent representation is required in the form of a generic graph — an ontological[9] schematic showing how nodes are related.
This is much the same as is done at both systems and enterprise levels, in that all architectural schematics can be considered as specialized forms of graphs. The only difference being that ecosystems-centric schematics are not so precious about the levels of abstraction and graphical nomenclature used to classify and describe node instances. Instead, associated typing is expected to be explicitly side-lined from the graphical symbology in play and documented as a node attribute in accompanying documentation. This increases the semantic expression available by making graph representation both flexible and extensible.
In general terms, then, nodes are represented at the ecosystem level using a flattened nomenclature of either boxes, or more commonly circles, connected by lines or arrows. There are no constraints on whether lines should be straight or not. The use of arrows normally indicates some form of directional flow, but again, typing can be moved out into accompanying documentation. This includes typing associated with composition, association, implication, and so on. For more details, please see Chapter 3.
1.5. Emergent Structure, Taoist Thinking, and Abstract Workspaces
The transition from graphical typing to documented attribution might, at first, feel misplaced and foolhardy, especially to those steeped in more traditional IT architecture practice. Nevertheless, the move is deliberate at the ecosystem level.
Of old, we, as IT architects, might have been asked to write down what we knew of a problem space, then analyze that text to help identify its various entities, actions, and properties of interest. In that way, prominent nouns typically translated into architectural entities, verbs their actions, and adjectives their properties or aspects. From there, composition flowed from decomposition, and architectural structure arose from the design and engineering processes being followed.
With Ecosystems Architecture, however, the complexities and scale of the problem spaces involved might well mask any system’s structure up front, so all we can do is state what is known and include whatever assembly is obvious as we go. This is analogous to throwing all our thoughts, ideas, and discoveries at a wall and allowing an architecture to emerge of its own accord — much like the singular idea of an enterprise spontaneously emerging from the cumulative contribution of its individual business functions. That is, rather than deliberately forcing out structure through a sequence of reductionist and/or compositional design tasks.
This change, therefore, demands increased diligence in documenting our thoughts across the board and at all times. In that, the analogy of an imaginary wall, or architectural workspace, becomes very real, and an abstract mathematical framework replaces the architect’s favored pen and paper to record progress. This specifically allows all the aspects of an architecture to be pinned down precisely, and in a very Taoist[10] way — almost like a highly expressive mind map with little concern for scale or complexity. That introduces its own rigor and a unique set of advantages, by way of the mathematical formalisms introduced. But more of that in Chapter 3. All that really changes is the order in which we recognize architectural elements, and the moments at which revelations become apparent. In the end, the same aim is reached, in a coherent understanding of how a system is, or should, be configured, even though the route to achieve that might not be totally clear at the outset and may also need the help of some advanced tooling[11] along the way.
Relying less on sequential progress to squeeze out structure means that understanding integration and interoperability must rise in prominence, especially during the early stages of architectural thinking. In short, the notion of connectivity needs to always be at the forefront in an architect’s mind, especially when it is understood that typing moves from being graphically explicit to an act of assigning property via additional documentation across all architectural elements. This stance is transferable to Enterprise Architecture as well, but the potential inability to perceive the enterprise as an ecosystem can serve to increase the dysfunctionality within that enterprise — through misalignment, discontinuity, and friction created by the deployed systems already in place.
1.6. Natural Successors
Enterprise Architects are well positioned to become Ecosystem Architects, by the virtue that it is only the boundary of discourse that changes when moving up from one abstraction to the other. First, however, there must be a significant shift in the appreciation of how an enterprise is meaningfully constructed. So much so that the value of isolated specialization is worth reiterating.
To nail this home, simply think of any organizational chart. What do you see? A box for Sales, a box for Marketing, a box for Engineering, and so forth, all followed by the other boxes for essential areas of business specialization. In other words, and in less flavorsome terms perhaps, a silo for Sales, a silo for Marketing, a silo for Engineering, and so on.
In an ecosystems approach then, each silo simply becomes a node, that, in turn, might act as a container for further nodes at increasing levels of detail. These nodes, as repositories for contributing functionality, data, and so on, are then fundamental and necessary. In fact, they become, in part at least, a best practice essential, in that the nature of the node affords delineation, specialization, flexibility, performance, and efficiency in an ecosystems view. Nodes, therefore, act as the basic means of aggregation at the ecosystem level.
In part, this realization comes down to appreciating that each silo establishes a set of motivations and behavioral patterns that directly support its existence and separation from other silos. There will, of course, always be some overarching motivations that transcend the individual unit, but these are more akin to accepted social behavior within some higher means of decomposition, and might actually act as connections between nodes when that level is considered formally. Therein, and in business terms, each silo may be associated with a primary sponsor, as in a Vice President or Director perhaps. This leader may or may not then get along with other Silo Leads, and so competition can take hold and distort reality as seen by IT. This not only plays out around extra-silo composition, but also intra-silo composition, with Silo Leads perhaps being prone to subdivide their own domains into lesser areas of speciality. This obviously creates more silos and more opportunity for isolating motivations and behaviors. As a result, sub-speciality silos can often present as badly formed nodes. This is a never-ending story. As no doubt most experienced IT architects will realize, internal organizational conflicts of one form or another can permeate and simmer into perpetuity. This creates one of the eternal challenges facing all IT architects.
In summary then, modern enterprise is a blend of both dependent and independent business units that co-exist within and across a complex ecosystem. Invariably, that ecosystem can transcend corporate boundaries, bringing further into question where the idea of an enterprise ends and the reality of open-ended ecosystems thinking begins. A starting point for aspiring Ecosystem Architects is therefore to learn how their own enterprise functions and behaves. Alignment needs to be toward supporting the organizational silo view and not disarming it or causing further friction. The bane of IT is the silo, and yet it is also its savior, as the enterprise is, at its simplest level, nothing more than a conglomeration of silos — or, as the Ecosystem Architect will come to call them, nodes. Some nodes interoperate better than others, some compete, and some, at times, are stubbornly dysfunctional. It is not the job of IT to fix the enterprise per se, and it is not a job of the business to change the enterprise to conform to IT’s perception. Nevertheless, it is the role of IT to support the enterprise in any manner that the enterprise itself wishes to exist. And to do that, IT must take to heart its mantra: “We want to align ourselves with the business”. This, therefore, is the starting point for the Enterprise Architect to transition up to hyper-enterprise ecosystems thinking levels.
2. What is all the Fuss About?
"The journey not the arrival matters.” — T.S. Eliot
“All pioneering engineering is very much like poker; there are some things that you know for certain, some things that you think you know, and some things that you don’t know and know that you can’t know.” — Sir Christopher Hinton
“It is paradoxical, yet true, to say, that the more we know, the more ignorant we become in the absolute sense, for it is only through enlightenment that we become conscious of our limitations. Precisely one of the most gratifying results of intellectual evolution is the continuous opening up of new and greater prospects.” — Nikola Tesla
Historically, organizational leaders only needed to worry about getting the best from their piece of the value chain. Today, however, as change becomes the only real constant in business, those leaders are being forced to reevaluate; specifically to embrace their broader context and explore the hitherto untapped adjacent opportunities around them. That brings greater uncertainty, and with it a need to embrace ever more comprehensive approaches to viable systems thinking. Unavoidably, both are now a necessity if organizations are to achieve parity with the successes of yesteryear.
This is indeed a frightening prospect. Still today, most organizations pay scant attention to the idea of constant change, especially when that involves large-scale, open-ended, complex adjustment. In such circumstances, it is not uncommon for leaders to run for cover. But that is only natural. At its core, the problem is about how we perceive risk and manage it successfully. Even so, in a world of ecosystems, clarity rarely comes in black or white, and the idea of understanding precisely where one challenge ends and another begins can be somewhat of a luxury.
Overall then, the world around us evolves constantly, like it or not, and just because it might be impossible for any individual to directly understand all the fineries involved, does not alter that fact one bit. In the modern, networked world, business evolves rapidly and often in complex ways at scale. That is our everyday de facto.
2.1. Evolution Over Change in IT Systems (Universal Darwinism)
To be blunt, change is not about evolution, but evolution is very much about change. In that regard, the former simply focuses on alteration and occurs without consideration for any grander plan. Evolution, on the other hand, points to change targeted toward the global betterment of those involved. Change can therefore be a negative thing, whereas evolution feeds on change to drive out negativity and promote advancement. Organizations can change, whereas, in the long term at least, ecosystems can only ever evolve if they are to remain viable. What is more, today we understand that evolution is a phenomenon not just limited to the natural world.
Scientists like Charles Darwin might well have taught us that evolution is tightly bound to skin and sinew, but more recent updates suggest that the idea is much more encompassing. For instance, in 1976 the eminent biologist and writer, Richard Dawkins, presented an information-based view in which he outlined the idea of selfishness in genes; thereby promoting the notion that they act only for themselves and similarly only replicate for their own good [40]. Dawkins also introduced the important distinction between replicators and their vehicles. It is the information held within the genes that is the real replicator, and the gene’s physical structure simply its carrier. A replicator can therefore be anything that can be copied, and that includes completely virtual capital like ideas, concepts, and Intellectual Property (IP) of significant commercial value. A vehicle is therefore only an entity that interacts with its environment to undertake or assist the copying process [40]. As a result, in modern business, any concept or idea embodied in the digital ether can be considered as a replicator, and human beings, alongside any hardware and software used in the form of IT, as its vehicle. This ties us, our musings, and our advancements together, as it always has, into the perpetually changing environment of commotion we awkwardly refer to as “progress”.
What results is the outcome of what Dawkins saw as a fundamental principle at work. In that, he suggested that wherever it arises, anywhere in the universe, be that real or virtual, “all life evolves by the differential survival of replicating entities”. This is the foundation for the idea of Universal Darwinism, which encompasses the application of Darwinian thinking beyond the confines of biological evolution, and which prompted Dawkins to ask an obvious, yet provocative, question: Are there any other replicators on our planet? The answer, he argued, was emphatically “yes”. Staring us in the face, although still drifting clumsily about in its primeval soup of evolutionary modernity, is another replicator — a unit of imitation [41] that is the very essence of sociotechnical progress itself. This is the fuel that truly powers the modern digital age, and it represents an important leap in understanding. By raising evolution above any level needing biological representation, it makes the digital ether an eminently suitable place for universal evolution. This is how the ongoing progress of the digital world maintains its momentum. Humans and the tools we build are inextricably bound together in an onward march. In realizing that, Dawkins found a name for his self-replicating ethereal unit of cultural exchange or imitation, taken from a suitable Greek root, and calling it a “meme”, inspirationally chosen for its likeness to the very word “gene” itself.
As examples of memes, Dawkins proposed “tunes, catch-phrases, clothes fashions, ways of making pots or building arches”. He mentioned specific ideas that catch on and propagate around the world by jumping from brain to brain or system to system. He talked about fashions in dress or diet, and about ceremonies, customs, and technologies — all of which are spread by one person copying another [41]. In truth, and although he could not have realized it at the time, Dawkins had captured the very essence of the post-Internet world, in a virtual memetic framework that would evolve just as all natural life had done before it. In a short space, Dawkins had laid down the foundations for understanding the evolution of memes. He discussed their propagation by jumping from mind to mind, and likened memes to parasites infecting a host in much the same way that the modern Web can be considered. He treated them as physically realized living structures and showed that mutually assisting memes will gang together in groups just as genes do. Most importantly, he treated the meme as a replicator in its own right and thereby for the first time presented to the world an idea that would profoundly influence global society [40] and business progress in one.
2.2. Things We Know About Complexity and Scale in Sociotechnical Ecosystems
With specific regard to the emergence of sociotechnical ecosystems in the modern age, there are certain things we know, and which should not be underestimated. For instance, as with all ecosystems, be they naturally real-world, synthetically virtual, or an amalgam of both, their arrangement self-organizes and regulates in ways that generally benefit the whole and not necessarily individual parts. We also know that the self-regulation involved nearly always pushes to reduce waste and effort. To the untrained eye, this can appear unruly and chaotic, but closer inspection will show both order and disorder vying for position. Ecosystems, therefore, show well-defined regularities but can also fluctuate erratically [39]. They are complex systems in the sense that they exhibit neither complete order nor complete disorder. Rather, there is no fixed position at any scale to point to as an absolute definition. Instead, complexity relates to a broad spectrum of characteristics. At one end lies slight irregularity, while at the other complete randomness, without meaning or purpose. Both are extremes of the same thing. When slight variation is exhibited it is highly likely that the overall pattern of the whole can be accurately predicted just by examining one tiny part, but when complete randomness is encountered that would be pointless and impossible. In the middle lies some exciting ground; a sweet spot of complexity perched on the edge of chaos. Here, the pattern is neither random nor completely ordered. Regions of differing sizes can all be found exhibiting similar features, leading to the perception of some underlying theme at many different scales. This is where truly natural complexity lives and where the bullseye for Ecosystems Architecture can be found. It cannot be described in terms of simple extrapolations around a few basic regularities, as is the case with Enterprise Architecture. Instead, it displays nontrivial correlations and associations that are not necessarily reducible to smaller or more fundamental units [42]. In a nutshell, such complexity cannot be boiled out and served as if cooked from a list of simple ingredients. Only a deep understanding of all the participants, connections, and properties involved can ever lead to a true appreciation of the whole, regardless of any surface presentation. In that way, complexity behaves like a façade, an interface almost, standing guard over the wherewithal behind. Recognizing this guard and paying due respect is the first step on the road to Ecosystems Architecture. It also ushers in a need for Taoist-like practices. In simple terms, that implies a constant and equal appreciation of all architectural properties in play and at all times; the continual abandonment of preconceived ideas around both local and global patterns (unless blatantly obvious across multiple viewpoints), and a willingness to accept that architectural structure may just emerge without any traceable justification.
In the open then, what is fascinating about complexity’s sweet spot is that it is not only supported by, but promoted as a result of new technology. When looking at economic history, as opposed to economic theory, technology is not really like a commodity at all. It is much more like an evolving ecosystem itself. In particular, innovations rarely happen in a vacuum. They are usually made possible by other innovations already in place. For instance, a laser printer is basically just a photocopier with a laser and a little computer circuitry added to tell the laser where to etch on the copying drum for printing. So, a laser printer is possible with computer technology, laser technology, and photo-reproducing technology together. One technology simply builds upon the inherent capabilities of others [43].
In short, technologies quite literally form a richly connected matrix or web of ingenuity. Furthermore, most technological matrixes are highly dynamic. They can grow in a fashion that is essentially organic, as when laser printers give rise to desktop publishing software, and desktop publishing opens up a new niche for sophisticated graphics programs. There is literally a catalytic reaction taking place [43]. What is more, technology networks can undergo bursts of spontaneous evolutionary creativity and massive extinction events, just like biological ecosystems. For example, when the automobile became affordable it replaced the horse as the primary mode of low-cost travel. Along with the popularity of the horse goes the primary need for blacksmiths, the pony express, the watering trough, the stables, and so on. Whole substrates of dependent technologies and support systems collapse in what the economist Joseph Schumpeter called “a gale of destruction”. But along with the automobile comes a new generation of change: paved roads, gas stations, drive-by fast food chains, motels, traffic police, and traffic lights. A whole new network of goods, services, and associated technologies begins to grow, spawning cascades of evolutionary sequences elsewhere, each one filling a niche opened by the redundant goods, services, and technologies that came before. The process of technological change is not just a mimic of natural eco-processes; it is like the origin of life itself [43].
2.3. Commerce and Ecosystems
Neoclassical economic theory assumes that systems like the economy are entirely dominated by negative feedback — the tendency for small effects to die away and have no lasting impact on the wider environment. This propensity has traditionally been implicit in the economic doctrine of diminished returns [44]. But, as has been realized in more recent times, there is also positive feedback, or increasing returns present as well — influences that bubble up and build upon each other leading to higher plateaus of stability. These not only help promote significant change such as trends, but also help to explain the lively, rich, and spontaneous nature of many real-world systems.
All this presents a strong case in favor of the obvious; in that, modern companies are now intrinsically embedded into multiples ecosystems, in a number of ways and at a number of levels. Traditionally this has not been seen as the case, especially amongst large-scale enterprise organizations. Many still steadfastly believe that they are outside influencers, or even worse, creators of some end effect they perceive as relevant in their target markets. Real occurrences of this are becoming increasingly rare, however, and are at odds with the ecosystem model which sees growth stimulated from the inside out. In this model, the world is much less responsive to external brute force and deeply relies on new capabilities augmenting the value proposition of others.
2.4. Minimum Effort in Organization and Structure
The notion of brute force also becomes counterintuitive in an ecosystem world, by breaking the rule of minimized wasted effort wherever possible. For such reasons, ecosystems naturally organize in ways that scale easily. Around the complexity sweet spot, they often choose to be self-similar and self-referential; for instance, forming clusters of capability that naturally compliment and coordinate across their constituent parts. This pattern then repeats at higher levels so that clusters can come together into super-clusters and so on, all reflecting the challenge-focused structure that is echoed in many successful communities and organizations today. Look at how social media works, for instance, or the innards of the Internet. Examine how motorways are mapped or how the various veins and arteries of every living creature are organized. In all, you will see the same metapatterns in use. Instead of employing ridged hierarchies of command and control, many such organizations nimbly flex to dynamically allocate resources as need demands. This not only increases agility and local relevance but removes any preconceived obligation to align with particular definitions of need, market or customer. Such organizations are equally at home providing products or services directly to the lone consumer, the business unit, division, or enterprise. This is further backed by recent observations from major analysts like Gartner® [45] [46], Forrester® [47] [48] [49] [50], and McKinsey™ [51]. Overall, flexibility of organization and an openness to repeating structural pattern(s), at varying levels of scale and abstraction, are key, both to understanding the essence of ecosystems and to the design of the Technical Architectures needed in support of success at the hyper-enterprise level.
Likewise, such communities, groups, organizations, and arrangements are continually open to collaboration internally and externally. This not only covers relationships with contemporaries, but also with surrounding environment/market occupants at whatever level, be they suppliers or consumers. It is this ability to spontaneously empathize with, seize, and augment opportunity that adds to their stand-out credibility. In business, for example, by necessity, successful units never focus on one commercial play for too long, instead concentrating on how to develop models and platform plays that can quickly build on grounded success within their surrounding ecosystem networks. This is what gives these units and their parent organizations their defining operational advantage, and ultimately longevity in the face of accelerating change. Their center of gravity is therefore much lower and more dispersed. Within these organizations, high-level direction still filters down from the top, but the power that drives innovation and continual business growth comes not from within, but rather from the networks of support structures flowing out beyond the immediate control of their leadership teams.
2.5. How and Why Ecosystems Form
Ecosystems form and thrive, therefore, out of an ability to seize latent advantage. In a word, the key is “serendipity” — the aptitude of an individual or group unit to recognize an adjacent or alternatively possible state and adapt to fulfill its potential in mutually beneficial ways. This adjacency not only ensures that appropriate skills, resources, and demand are close, but minimizes the cost and effort involved in innovation. In truth, however, innovation is too strong a word for it, as it suggests elements of independent expertise. Although this can be true, the trick to progress in an ecosystem is deep dependence, especially at the local network level. For that reason, ecosystems form from the adaptation or augmentation of whatever is already in place. They rely more on novelty, inspiration, and appreciation of latent need than any abstract ability to invent.
This is what experts like Stuart Kauffman [52] refer to as “Darwinian preadaptation”. In his work on evolution, Charles Darwin noted that an organ, say the heart, could have causal features that were not the function of the organ and had no selective significance in their normal immediate environment. But in a different environment, one of these features might indeed come to be significant [53].
This type of incidental latent ability to adapt is abundant in biological evolution, with the classic example being the swim bladder in fish. These organs are partially filled with air, partially with water, and allow fish to adjust their buoyancy. Paleontologists have traced their evolution back to early fish with lungs living in oxygen-poor water. Such lungs grew as outpouchings from the gut, allowing air bubbles to be absorbed and the fish to better survive. However, this led to both water and air mixing in the same organ and in such a way these early lungs were preadapted to evolve into a new function — the swim bladder [53].
It is important to understand that preadaptation is not exclusive to biology, however. To provide an example, the following story is said to be true: A group of engineers were trying to invent the tractor at the start of the 20th century and, given the heavy work it would need to do, they knew they would need a massive engine. So, they obtained a huge engine block and mounted it on a chassis, which promptly collapsed under the weight. They then went on to try successively larger chassis, all of which also broke. All seemed lost until one of the engineers noted that the engine block was so rigid that it could be used to replace the chassis they were struggling with. And indeed, that is how tractors are made. The rigidity of the engine block is applied as a Darwinian preadaptation in the economic sphere [53].
As a further similar example, latent dependency in an economy can drive demand for one product because of change in another. In this way, if the amount of meat in circulation rises, the price of meat falls. Hamburgers might likely experience a rise in demand and therefore restaurants and outlets demand more bread buns. This leads to increased profit across local bakery outlets. In this way the equality of the ecosystem levels out, as one incumbent benefits as a result of another’s loss.
2.6. Business Response and Beyond
Various names, phrases, and classifications have been invented, reintroduced, or dusted down to help business accommodate the rise of ecosystems thinking. Most, however, are just signposts toward the overall swell of cultural and technological change needed to face off against the reality of the modern connected world. Gurus will talk of “digital initiatives” and “consumerization”, but no single term or phrase really does it justice. The overall change needed must be all-encompassing, coming both from the top and from grassroots levels. This must not only affect the way that organizations structure, but yield a fundamental change in the allocation of responsibility. The easiest way to understand this is to again think in biological terms. Living systems need to adapt constantly to their environment, which has led to the evolution of multiple sensory systems in living organisms. These provide continual feedback, and when external change is experienced, they react both consciously and subconsciously — not only sending signals back to the brain, but also inducing local reaction without the need for support. Without the ability for a reflex reaction to extreme heat, for instance, many animals would suffer far worse scalds or burns when waiting for a sensory signal to be sent to the brain and a muscle response to be triggered.
Such reactions provide a critical lesson for any business. If it is to remain responsive in a world where external stimuli are becoming more prevalent, rapid, and important. Not only are standard long-chain response systems needed, but responsibility must partially devolve to points of contact closest to surrounding influence networks. If done correctly, this will not only mirror the efficiencies of any self-referential problem-solving organizational structure but promote operational autonomy and catalyze change in harmony with the external environment. These lessons should be clear. Billions of years of biological and ecological evolution tell us so. Mother Nature is rarely wrong. What we need to do now is grasp the essences of her blueprints and learn how to infuse them at levels within the reach of direct architectural practice. Not just in the realm of IT architecture, but covering everything from organization structure, through business process design, out into cultural realignment, and so on.
2.7. Revelation Not Revolution, and on to Emergent Intelligence
Cumulatively, we are doing this already, but sometimes in nonobvious ways. When the early Internet pioneers set about designing their network, for instance, they were under military direction and keen to ensure the reliability of end-to-end connectivity while under sustained infrastructure attack. The rerouting of data packets across the Internet’s rats’ nest of wire-ways is therefore integral to its construction even today. Reframe that need, however, and the primary design objective becomes one of basic survival. As such, the Internet’s architecture is deeply primordial and completely in line with the most fundamental tenet of evolution; in that, the survival of the whole will always take priority over that of the individual, thereby assuring continuity of opportunity and advance regardless of local setbacks.
This same architecture was passed down from the world’s telecommunications networks and likewise passed on to the World Wide Web. As a result, the continuity of business-to-business and human-to-human communication will remain highly resilient in the face of global disaster.
Beyond that, the implications are more subtle and far-reaching. For instance, above the level of the World Wide Web, experts now openly talk of social machines [54] [167] [168] [169] [170] [171] [172]. These see the planet’s networks bond whole communities (be they social or commercial) together into emergent amalgams able to act with unified, almost algorithmic, purpose. This is intelligence at the societal level [55] [56], and must lead us to question the very idea of intelligence itself.
Our natural inclination might well be, therefore, to consider intelligence, true intelligence that is, as a solely cerebral quality trapped within the confines of a single biological brain. But it is not. There are many different types of intelligence. Take, for example, the mind of the humble herring. Could such a creature outsmart the intelligence of any individual in their right mind? How about an ant, a bee, or a starling? Same question: how do you fancy their chances? Easy, it might be thought, but what if the rules are changed slightly? How about a shoal of herring, a swarm of bees, a murmuration of starlings, or a colony of ants? Could any individual construct their own skyscraper capable of housing several thousand of their brethren out of nothing more than dirt, for instance? That is exactly what a colony of ants can do, and to them it is one of the easiest things in the world. Furthermore, they are far from unique. It goes without saying that bees can produce great honeycombed hive complexes, and even the humble herring can organize itself with ease into a moving current of consensus, sometimes up to seventeen miles long. Regardless, would you ever consider a bee to be the brightest of creatures? It is not, and that is just the point. There are certain types of intelligence that emerge as if from nowhere. They are created by the summation of tiny snippets of capability — capability that is inconsequential on its own and nondifferential, but capability nonetheless. This works at lower levels in the main, but has just enough quirks, lumps, and bumps to fit precisely into a much greater, purposeful jigsaw of intellect — a jigsaw with no keystone, no ruler, or single manager. No mastermind, then, in such collective puzzles, but still puzzles that reveal a clear and concise picture once whole. A puzzle that is the norm in the realms of distributed intelligence.
“Where is the spirit of the hive, where does it reside?” asked an author as early as 1901 [55]. “What is it that governs her, that issues orders, foresees the future …?” We are certain today that it is not the queen bee. When a swarm of bees decides to migrate to another location, the queen bee can only follow. The queen’s offspring manage the election of where and when the swarm should settle. A handful of anonymous drone workers scout ahead to check possible hive locations in hollow trees or wall cavities. They report back to the resting swarm by dancing on its contracting surface. During the report, the more vigorously a scout dances, the better the site it is championing. Other bees then check out the competing sites according to the intensity of the dances before them and will concur with the scout by joining in its jig. That encourages more followers to check out the lead prospects and join the commotion when they return by leaping into the dance troop of their choice [55]. It is uncommon to see a bee, except for the scouts that is, which has inspected more than one site. The bees see the message “Go there, it is a nice place.” They go and return to dance, saying “Yeah, it is really nice.” By compounding emphasis, the favorite sites get more visitors, thus increasing further visitors. As per the law of increasing returns, those with more votes get more votes, and those with less votes lose. Gradually, one overwhelming multitude of agreement is reached, and the hive moves as a whole [55]. The biggest crowd wins, end of story.
2.8. Pseudo Ecosystems and the Restricted Use of Collaboration Tools
History is littered with examples of technical movements, projects, and initiatives that claim to be ecosystems, but are not. For instance, many organizations work with collaboration tools like Box® and Mural®. Such workspaces allow for ideas to be shared across communities of interested parties, and can work well to both stimulate and advance progress. As such, they carry distinct value in certain situations, but do not always count as ecosystem catalysts. This is for several reasons. First, their placement often restricts their audience, which thereby limits their inputs, outputs, and subsequent opportunities for feedback, serendipity, and preadaptation — think of platforms like Facebook®, WhatsApp™, or Twitter™ by comparison. Second, they are often offered within the broader cultural constraints of external command-control structures, like those found in large commercial organizations. These can impede the entrepreneurial spirit and unnecessarily influence evolutionary direction. They are also restricted by the mere fact that the skill needed to contribute precludes a significant number of those who might genuinely want to collaborate. What is more, individual participants can often be constrained by surrounding culture and various external rules or regulations, imposed because of physical location, surrounding politics, and so on. In total, therefore, the restricted application of collaborative tooling is more likely to encourage the development of closed communities, rather than genuinely evolving ecosystems per se.
All that said, such communities can sometimes qualify as ecosystems incubators, especially in climates of rapid and volatile disruption. This is due to reasons of diversity and reach.
There is strong evidence that diversity can improve community stability by influencing the response to disturbance and/or environmental fluctuations. For instance, more diverse assemblages are more likely to display a range of functional traits, increasing the probability that it is possible to compensate for negative responses to disturbance or environmental change [57]. A related phenomenon is the portfolio effect; that is, if the abundance of differing participants within a community fluctuates independently, or at least out of phase with one another, then these fluctuations can average each other out, leading to less variation over time in the diverse assemblage involved [58]. The net of this is that diversity helps protect against false bias and promotes a genuinely broad opportunity for evolutionary processes to take hold.
All of this points to the benefits and challenges associated with openness, decreased centralized control, increased self-regulation, and individual freedom within traditional organizations. To wrestle with these ideas, several models have already been suggested. For instance, the Platform as a Service (PaaS) model has been widely promoted [166] in recent years. This presents the idea of a stage or theatre of operation — an area where “a range of unique capabilities can be deployed and where organizations can seek to establish control over a range of value-creating activities”. At the surface, such models appear to support the type of problem-focused, self-referential patterns common to ecosystems, but when examined alongside established thinking on sociotechnical ecosystems [43] [39] [44] [41] [59] [60], the evidence suggests that they will prove restrictive.
Here, the key challenge is that such platforms demand hierarchical structure and promote demarcation, thereby limiting evolving conversation flows at multiple levels. In essence, they seek to impose predefined views of the world based on historically successful business models. These just limit free thinking, stifle spontaneous serendipity, and restrict preadaptation in situations hopefully primed for disruption — even though value stream-orientated teams working on such platforms might be autonomous to build and run solutions to meet specific business value outcomes. This counterintuitively fights the primary purpose of any ecosystem, in the need to break free, expand, and find new ground. They further break the rules of minimal effort and devolved responsibility, distracting effort away from evolutionary problem-solving processes, toward the construction of unnecessary ancillary frameworks and management controls.
2.9. Autocatalism and the Extremes of Complex Systems
As an outcome of work on complex systems at scale [61] [62] [63], we have now come to realize that if the conditions in complex networks are right — in any given primordially connected soup, as it were — then there is no need to wait for random reactions to occur at all. The constituent parts, or participants, involved should simply gravitate to form a coherent, self-reinforcing web of interactions and reactions. Furthermore, each constituent in the web should catalyze the formation of other constituents, if appropriately left to its own devices — so that all the constituent parts steadily grow more abundant relative to parts that are not involved. Taken as a whole, in short, the network should catalyze its own formation and in doing so be categorized as an autocatalytic set [64] [65].
Experts, like Kauffman, recognized this as free order created by complex emergent behavior. This was natural order arising through basic rules rather than by any organizational imposition [66].
But was this the real essence of evolutionary success? No. An autocatalytic set has no internal blueprint from which to build itself, no DNA to speak of, no genetic code, no cell membrane — no architecture! In fact, it has no real independent existence except as a haze of constituents floating around in some particular space. Its fundamental nature is not to be found in any individual member of the set, but in the dynamic of the whole; in its collective behavior.
Even so, Kauffman believed that in some deeper sense, an autocatalytic set could be considered to be alive. Certainly, such systems can exhibit some remarkable lifelike properties. They can spontaneously grow, for example, and there is no reason in principle why an autocatalytic set should not be open-ended, producing more and more constituents as time goes on — and constituents that are more and more complex. Furthermore, autocatalytic sets can possess a kind of metabolism. Constituents can take in a steady supply of nourishment in the form of other constituents circulating around them, and catalytically glue themselves together to form more and more complex compounds [66].
Autocatalytic sets can even exhibit a kind of primitive reproduction. If a set from one space happens to spread out into a neighboring space — in a flood say, to use a suitable analogy from the natural world — then the displaced set can immediately start growing in its new environment, if the conditions are right. Of course, if another, different autocatalytic set were already in habitation, the two would intermingle in a competition for resources. And that, Kauffman realized, would immediately open the door for natural selection to purge and refine the sets. It is easy enough to imagine such a process selecting those sets that possessed the most appropriate fitness for the space — the landscape as it were. Eventually, in fact, it is easy to envisage the competitive process giving rise to a kind of DNA and all the other attributes we naturally associate with life. The real key is to find a set that can survive and reproduce. After that, evolutionary processes would kick in and could do their work in comparatively short order [44].
This may appear like speculation, but not to Kauffman and his colleagues. The autocatalytic set story was far and away the most plausible explanation for the origin of life that they had ever heard. If it is true, it means that the origin of life did not have to wait for a highly improbable event to produce a set of enormously complex molecules. It means that life could certainly have emerged from very simple ingredients indeed. Furthermore, it means that it had not been just a random accident but was part of nature’s incessant compulsion to resist entropy, its incessant compulsion to self-organize [66].
When Kauffman tackled the underlying mathematics of his ideas, the reality became obvious; that is, the number of reactions goes up faster than the number of polymers — connections and types of resources in the case of connected networks like the World Wide Web or the Internet. So, if there is a fixed probability that a polymer will catalyze a reaction, there is also some complexity at which that reaction becomes mutually autocatalytic. So, if any primordial soup passes a certain threshold of complexity, then it will undergo a peculiar phase transition. The autocatalytic set will indeed be almost inevitable [44]. And by such principles, if the conditions are right, the ever increasingly connected society in which we live, as well as the symbiosis of technologies that support it, is destined to live, too [66]. In that model, the reality of evermore complex and encompassing sociotechnical ecosystems becomes certain and certainly demands serious consideration; from a scientific perspective at least, if not from an engineering or architectural standpoint.
There is no trickery intended here. When looking at the ideas behind autocatalytic sets, it soon becomes apparent that they have the potential to be ubiquitous across all complex systems, not just those restricted to biology. Autocatalytic sets can be viewed as webs of transformation amongst components in precisely the same way that the economy is a web of transformation amongst goods and services, or the World Wide Web is a network of transformation across data and knowledge. In a very real sense, then, the World Wide Web and the global economy are both autocatalytic sets — as archetypal types of systems that consume resources (in goods, materials, and information) and convert them into something else, something much more powerful and useful too, as in profit and freely available insight [66].[12]
2.10. Back Down to Earth
After all the intensity of the text thus far, it is now time to pause before moving on to consider architectural practice.
A lot has been discussed in a very short space. We have gone from the history of IT, through ideas on ecosystems, added some hard-core theory along the way, and ended up making biological comparisons involving the idea of life itself. So, what on earth has this got to do with the future of IT architecture?
Well, the answer is actually remarkably simple. Rack up the evidence and the verdict will likely be that we are heading toward a much more complex world — a bottomless snake pit in which technology will play a far more critical role. Furthermore, the chances are that the complexity and scale of the problems we will face as IT architects will fall upwards of any human’s natural gifts. Add to that the increasingly dynamic and uncontrollable contexts in which these systems will live and an apparently impossible situation becomes clear. This is the world that the author, Kevin Kelly refers to as being “out of control” — the dawn of a “new era in which the machines and systems that drive our economy are so complex and autonomous as to be indistinguishable from living things” [55].
But wait. Let us not get too despondent just yet. Increased scale and complexity may well be a fait accompli in our IT systems, but within that can be found much to work with — elements that will indeed not only require, but demand, explicit architectural understanding and control. These live in and around the solidity found at complexity’s sweet spot, a solidity openly acknowledged by experts like Kauffman and others — the areas of essential stability, needed to uphold the chaotic spiral of ongoing progress around them. This is where the IT architects of the future will live. And in maintaining the vitality of such solidity, the overall importance of IT architecture will surely rise severalfold.
That means at least two things. First, that there is a clear responsibility on IT architecture to deliver systems that can tolerate (to some degree) both uncertainty and rapid change — no longer will concrete certainty in functional outcomes or operational performance suffice. Second, IT architects will need to deeply understand the mechanics at play in the world around them. In short, they will have to know as much, if not more, about the environment(s) of their solutions, as the solutions themselves. That will mean a broadening out of skills to include, at the very least, an understanding of complexity, basic physical and biological concepts, psychology, and sociology. So, IT architects will need to be increasingly polymathic going forward.
Beyond that is the real challenge. Bringing all these things together into some sort of framework that is readily consumable and eminently practical will be hard. Very hard. It is not something that should be underestimated under any circumstances. Where the base principles of IT architecture may have taken several years to settle, it may take decades for the same to happen with Ecosystems Architecture. Furthermore, whatever demarcations exist between IT architecture and other disciplines, they will surely be both added to and blurred beyond recognition. In that, IT architecture will likely become a blur itself, combining engineering rigor, advanced mathematics, applied science, and exquisite creativity. As such, what you will read here is only the first step on that journey. There is no intention to be definitive, complete, or even immediately relevant. Instead, what you have is more of an introduction to the introduction. A preface to what might come, as it were.
Over the coming pages, the intention is first to disassemble and distill the essence of several well-established architectural tools and approaches. These will then be built back up by extending the ideas at their very foundation. After that, we will look at the erosive challenges imposed by time and rapid change, before finally closing with a handful of conclusions.
So, consider this somewhat a voyage of discovery. Explorers and experimenters have long pushed the boundaries of what we know. They have, for instance, stretched the limits of what is humanly possible, journeyed to far-off places, and even reached out into the darkness of space. For those who have reported back, their stories have enthralled and educated us. We have also learnt from those who have not been so lucky. Take, for instance, the story of John Franklin’s ill-fated Arctic expedition in 1845 [67], as he went in search of the fabled North-West passage. Although not a happy story, his expedition was made possible because of the innovation we now know as canned food. Sadly though, for Franklin and his crew, and although the idea behind food canning was sound, the poor sealing of the cans he took ultimately led to his death and that of his crew through lead poisoning. If only they had waited until 1904 when the Max Ams Machine Company of New York patented the double-seam [68] canning process, which is still in use today.
After the event, we learned of Franklin’s demise and, in retrospect, it is not so much his attempt to expand our worldview that has held our attention. Rather, it is about lessons learnt; how to push out safely and come back with something new and useful.
Notwithstanding the perils of poorly canned food, that is what to expect as you read on here. You will hopefully find snippets of wisdom, some new insight, and perhaps even the faintest whiff of adventure. Nevertheless, nowhere will you find any deliberate direction or intention to land at a fixed destination. You may also uncover some wrong turns and dead ends along the way, but that is all part of the business of exploration. No, this text is more about direction and discovery, pointers and potentials. It is not about doctrines, promised lands, revolutions, or replacements. No doubt it will be a challenging journey for some, but not all. For those intrigued, we wish you well and ask you to persevere. For those who persevere and succeed, we ask you to join us as the quest continues.
Welcome to Ecosystems Architecture …
3. Tooling From First Principles — None of This is New
“There is nothing new except what has been forgotten.” — Marie Antoinette
As IT architects, we work hard to make sure that our ideas are easy to understand and, therefore, learned many years ago that visual representation can be much more powerful than the written word. As a result, much of what we do is visual, and when we first document our ideas, we metaphorically apply broad brush strokes to outline the essential technical elements necessary. This is how and why the likes of Context Diagrams and Architectural Overviews come about, both of which comprise little more than a collection of drawn boxes, connected using a series of lines. That is why some experts talk of IT architects only needing two weapons — the shield and the spear.
Here, the shield is analogous to box notation and, likewise, the spear represents the various types of connection used in architectural schematics. All that matters in such diagrams is that the things or ideas needing representation are communicated through the drawing of boxes or similar shapes. Likewise, the connections between these things are shown through the drafting of connecting lines. Both boxes and lines can then be labeled and/or annotated to bring their contribution to any overarching narrative to life. In that way, structure is added to the processes involved in architectural thinking, so that large problems (of less than a headful) can be broken down into smaller and much easier units to handle; see Figure 4.
In any given architectural diagram then, whether logical or physical, boxes of various sorts are invariably related to other boxes through a single, or multiple, lines. For instance, when a line is used to depict the movement or exchange of data between two processes, in the form of boxes, any implementation details associated with that transfer might be separated out and described via a further schematic or some form of additional narrative. This helps to simplify the diagram, so that specific points can be made, abstractions upheld, and a clear separation of concerns maintained.
Once the general composition of boxes and lines has been worked through, things do not change all that much, regardless of whatever viewpoint needs representing. So, different shapes and lines can be swapped in and out as necessary to get across what is important. Whichever way, the loose idea (nomenclature) of boxes and lines always lies beneath. For instance, when using conventions embodied in the Unified Modeling Language™ (UML®) standard, boxes and lines of various kinds can be composed to form a range of diagrams, two examples of which are shown in Figure 5.[13]
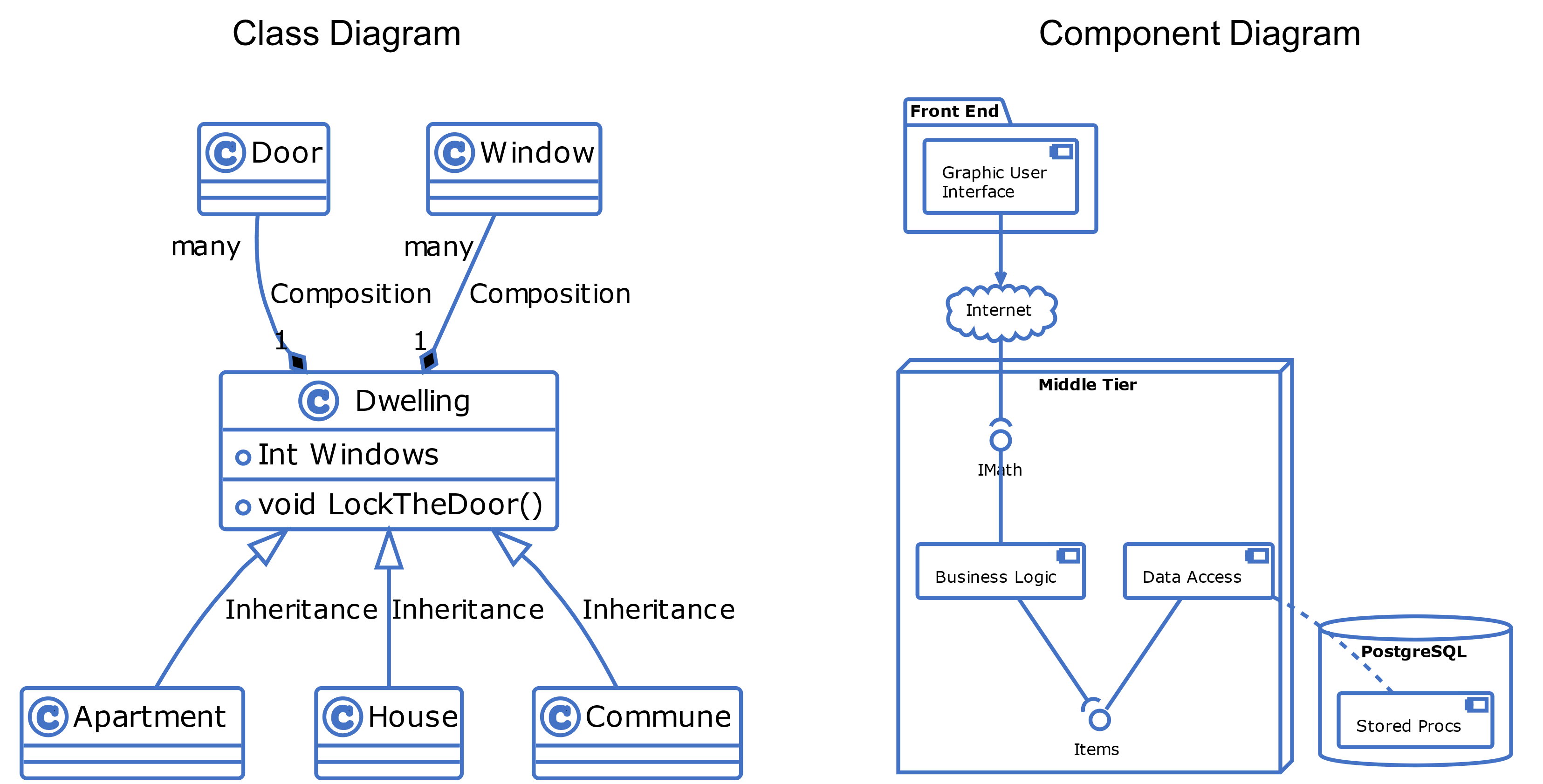
The point to note is that whatever framework is used, its diagrammatic expression is singularly limited by the range of shapes and lines listed within the vocabularies of its various standards.
More formally, the shapes and lines involved in any design standard function as a finite set of abstract types, aimed at supporting the communication of architectural intent; that is, they only cover the things that need to be said. They do not, however, have anything foundational to say about how such things might be brought together to create wholesome descriptions of that intent. That guidance is provided through architectural practice, often referred to as “methodology”, embodied elsewhere within the framework. In that way, various shapes and lines can be plugged together to give us the useful tools and methods we know and love as IT architects.
Once complete, the diagrams produced hopefully model all the salient characteristics of some architectural aspect, important to the problem space being considered, and, for that reason, they themselves become known as Models. Out of that comes the discipline we now know as Model Driven Architecture® (MDA®).
3.1. Model Driven Architecture
MDA is a software and systems development approach which emphasizes the importance of models in the development process. It therefore defines a set of guidelines for creating models that describe different aspects of an IT system, such as its functionality, structure, and behavior. These models can then be used to generate code, documentation, and other artifacts.
The key components of MDA can be seen as:
-
Platform Independent Models (PIM)
These provide abstract representations of the system under consideration that are independent of any particular implementation technology or platform. PIMs, therefore, represent an IT system’s functionality and behavior in a way that can be understood by both technical and non-technical stakeholders. -
Platform Specific Models (PSM)
These model-specific details of how a PIM will be implemented on a particular platform. PSMs, therefore, define the specific technologies, languages, and tools to be used when building and deploying build an IT system. -
Model Transformations
These define the process used to automatically generate code, documentation, and other artifacts from PIMs and PSMs. Model transformation, therefore, is facilitated by tools that can analyze these models and generate appropriate codified outputs.
Consequently, MDA specifically promotes the separation of concerns between the different aspects of a software system, thereby allowing developers to focus on each aspect independently. This separation also enables IT systems to be developed using different technologies and platforms, making them more adaptable and future-proof. This leads to a key benefit, in that MDA has the ability to improve the efficiency and consistency of development and deployment processes. By using models to describe an IT system, developers can quickly and accurately communicate the system’s requirements and design to stakeholders. Additionally, the use of model transformations can significantly reduce the amount of manual coding required, which, in turn, can potentially reduce errors and lead to productivity gains.
3.2. Toward an Ecosystems Framework
Approaches like MDA are not a panacea for the effective design and delivery of all IT systems though. They have drawbacks, and these unfortunately become clear when working at hyper-enterprise scales. Indeed, many of MDA’s strengths work to its detriment as the scale of the tasks it is being asked to address increase.
The first weakness unfortunately comes from MDAs defining strength, in that it was designed from the ground up to appeal to human users. That is why it is inherently graphical and intentionally reductionist in nature.
As a race, we evolved from the plains of Africa primarily on the strength of our flight or fight response. As such, our senses subconsciously prioritize inputs while our brains automatically filter out unnecessary signals. That leaves room for little more than the essentials of higher-level cognition. In a nutshell, that makes us sense-making survival machines, primed for life in a cave dweller’s world. As a result, and no matter how much we shout about it, the fineries of humanity’s historic achievements amount to little more than icing on that cake. For all that MDA works admirably as a coping mechanism to help when constructing modern-day IT systems, its value pales into insignificance when compared to the hardwired coping systems we have evolved over the millennia. That is why MDA is so effective; simply because it can help boil complex problems down into simple and static graphics which naturally appeal to our biological bias for visual stimuli. No more, no less.
But here is the thing. The world is not simple, and the more grandiose things get, generally the more simplicity is squeezed out. Detail abounds and important detail at that. It abounds, collects, and changes in a mix of evolving dependence and independence; a mix that often the human brain just cannot cope with, and which bounces off any attempt to reduce and simplify in human terms. Modern computers, however, now that is a whole other story. They simply thrive on detail. Where the human brain will prioritize, filter out, and overflow, today’s computer systems, with their multipronged AI, will just lap things up. Increasingly they do not even need to reduce or separate out the complex concerns that would have once floored their weaker ancestors. Complexity and scale, to them at least, amount to little more than an incremental list of work to do. It is about completing additional cycles and hardware configuration, that is all. The bigger the problem, the larger the infrastructure manifest needed and the longer we humans need to stand by the coffee machine awaiting our answers.
It is similar to the field of mathematics, where shapes and lines work well when we humans use them to help solve small and simple problems. The need to continually add more graphics to any workspace just overpowers as scale and complexity rise. Mathematics, on the other hand, fairly welcomes in scale and complexity. If you want to ramp things up or juggle more balls at the same time, that is a relatively easy thing for mathematics to do. Within, it embodies various types of containers[14] that do not care about how much data they are given. Indeed, their design is based on overcoming such obstacles. For them, managing size and complexity are mere arbitrary challenges only rattled by unruly concepts like infinity.
So, where does this leave us?
For IT architects to work effectively within this complex mix of detail and change at hyper-enterprise scale, at least two things need to be achieved. First is the broad acceptance that hyper-Enterprise Architectural challenges are indeed real and are materially different from all that has gone before. Beyond that, a framework, or frameworks, of extension to existing practice and a handful of new ideas are needed to help lay the ground for pragmatic progress. In truth though, few new ideas are really needed. All that is really required is a dust down of one or two foundational concepts and their reintroduction alongside modern-day architectural practice.
3.3. Graph Theory and Graphs
But how might these things be achieved? How might we distill and capture such extensions?
Hopefully, the answer should be clear. Hopefully, we are heading for a place where graphical representation and mathematical formality are both equally at home. Hopefully, that sweet spot can also accommodate change and chance at scale, so that we might model large, complex systems over many, many headfuls. And perhaps, just perhaps, that sweet spot will further align with the principles of existing architectural approaches like MDA?
Clearly the answer is “yes”.
In saying that, it is perhaps worth remembering that the relative informalities of approaches like MDA are themselves founded on some very formal mathematical thinking. Just connecting two shapes together via some form of line, for instance, rather handily provides a metaphor for the notion of set intersection [69] in set theory [70] — in that both shapes connect through some shared interest or trait. In that regard then, most of that which we consider as being informal in approaches like MDA, and more specifically in methodologies like UML perhaps, merely act as a façade over some altogether more formal thinking. Our methodologies then, no matter how formal or informal, provide gateways between that which is deeply philosophical and that which feels deeply familiar. They provide the wrapping that hides mathematics from everyday working practice, and so mathematics is, and always has been at home in the world of IT architecture. Likewise, the plug-and-play graphical nature of MDA is itself based on an independent and underlying mathematical model. That seeks to understand how ideas, things, events, and places, and so on might be connected into networks, and comes out of a group of mathematical ideas collectively known as graph theory [71] [72]. In that way, any schematic, representation or description that explicitly connects two or more things together in an abstract sense can be understood as a graph.
The basic idea of graphs was first introduced in the 18th century by the Swiss mathematician Leonhard Euler and is normally associated with his efforts to solve the famous Königsberg Bridge problem [73], as shown in Figure 6.[15]
Previously known as Königsberg, but now known as Kaliningrad in Russia, the city sits on the south eastern corner of the Baltic Sea and was then made up of four land masses connected by a total of seven bridges. The question, therefore, troubling Euler was whether it might be possible to walk through the town by crossing each bridge just once?
In finding his answer, Euler astutely recognized that most of the city’s detail was superfluous to his challenge, so he set about focusing solely on the sites he needed to reach and the bridges he needed to cross to get between them. In doing that, he abstracted away from the immediate scenery and formed a simple map in his mind. When all but the essential detail was gone, what remained amounted to a collection of dots representing his essential locations, and seven lines representing the very bare minimum journey needed between them. In essence, he had created an abstract topology of the city consisting of mere dots and connecting lines. Each could be documented, of course, to name it as a specific place or route on his journey across the city, but in its most basic form, Euler had found a way of distilling out a problem’s all but necessary parts and glueing them together to give a coherent overall picture of a desired outcome. This abstract arrangement of dots and lines is what mathematicians today know today as an Undirected Graph (UG). By adding arrowheads to the lines involved, any such graph provides instruction to the reader, asking them to read it in a specific order, thereby making it a Directed Graph (DG) — of which Euler’s solution to the Königsberg Bridge problem provides an example. Beyond that, there is just one further type of graph worth mentioning for now, in a Directed Acyclic Graph (DAG). This is the same as a directed graph, but where the path of its connections never returns to previously visited ground. Figure 7 shows examples of the various types of graph.
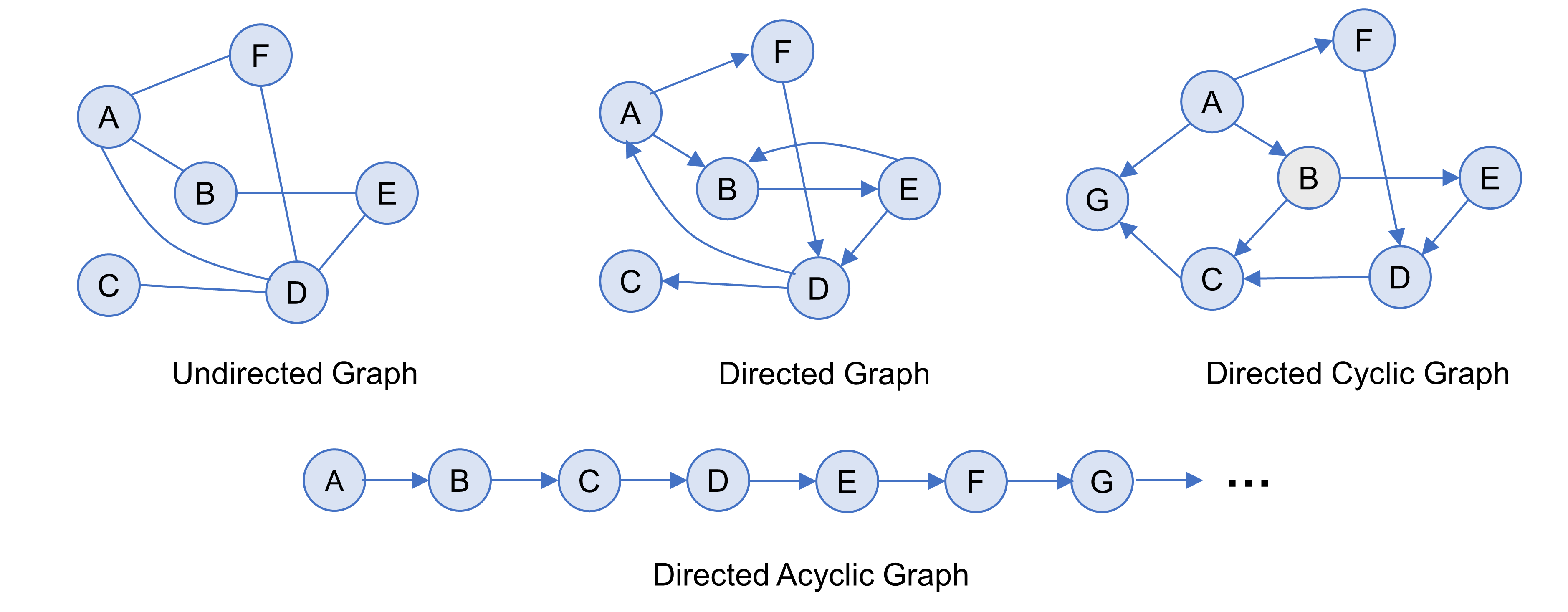
Graphs are therefore mathematical structures that model pairwise relations between points of interest (more formally known as nodes), as in the labeled circles shown in Figure 7. These nodes are then connected by lines (more formally known as arcs or edges) when a relationship is present. Nodes can also have relations with themselves, otherwise known as a self-loop [75].
3.4. Graphs, Architectural Schematics, and Semantic Extensibility
For hopefully now obvious reasons, graphs are especially useful in the field of IT architecture, simply because all the schematics that we, as IT architects, create (regardless of how formal or informal they might be), share, and trade, no matter what size, complexity, denomination, or related value, can be redrawn in pure graph form. That is all of them, regardless of whether they relate to structure or behavior, be that logical or physical. It really does not matter. That is because all such schematics possess graph structure under the hood. Graph theory, therefore, provides the common denominator across all architectural needs to describe and communicate[16] intent. Understanding graph theory consequently unlocks the logic that our world was built on.
Pick a Component Model, for instance. To redraw it as a pure graph, comprising of just dots and lines, is easy, in that the task simply becomes the same as drawing with the usual specialized shapes, but instead replacing them with generic nodes and arcs. All that is needed in addition is the overlaying of annotation, so that the schematic’s constituent elements can be identified uniquely and associated with the required specialized types, attributes, and so on. In that way, graph nodes can arbitrarily be listed as being of type component, chicken, waffle, or whatever. It is also the same with connecting arcs, so much so that mathematics even lists a specific type of graph, often referred to as a labeled or sometimes a weighted graph, that explicitly requires the adding of arc annotation for a graph to make complete sense.
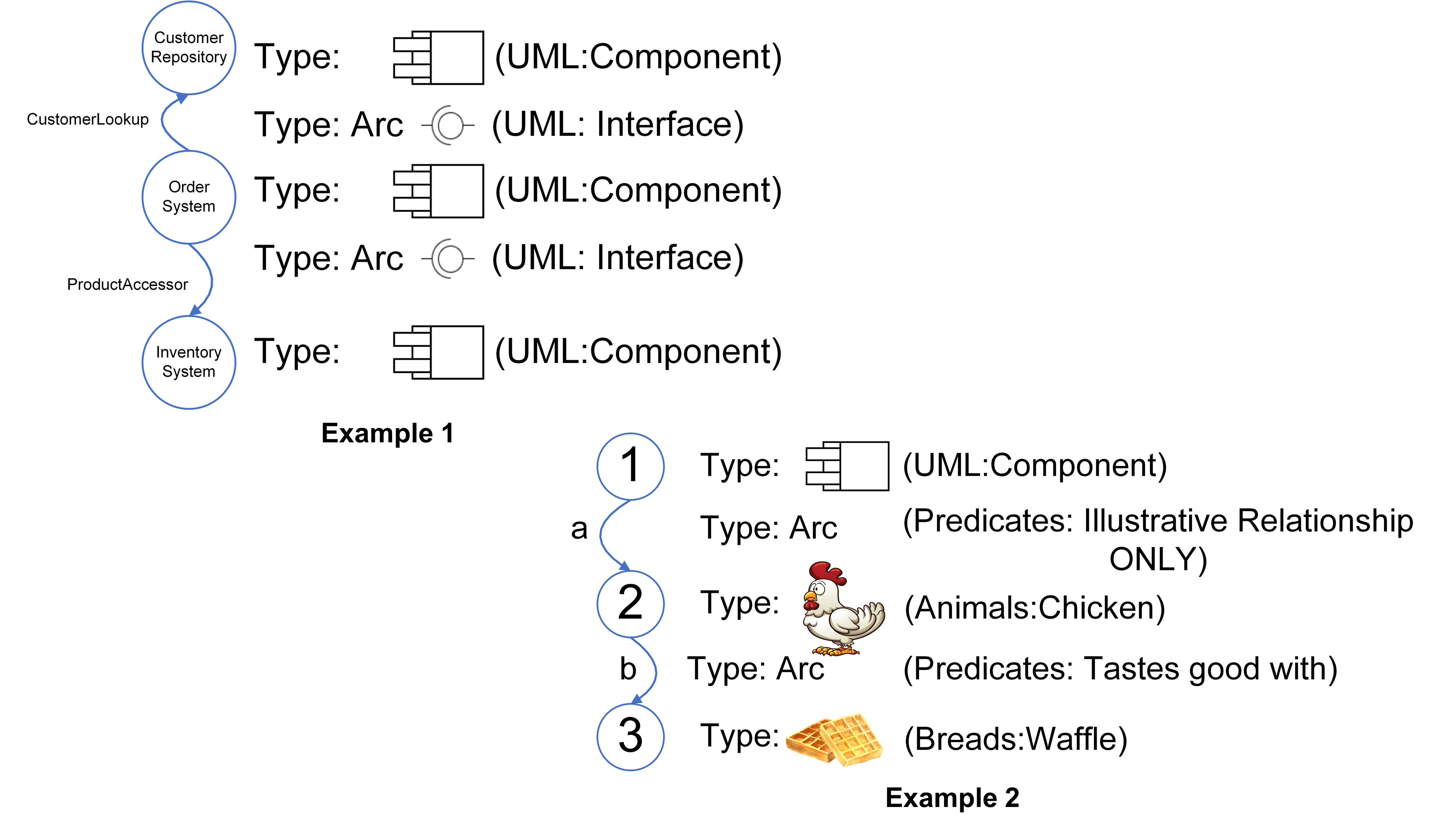
Figure 8 illustrates a couple of trivial graph examples, with the schematic on the left (Example 1) showing how a simple UML component model might be redrawn as a directed graph, and the diagram on the right (Example 2) illustrating that graphs are quite at home mixing up concepts from different frames of reference, methodologies, or whatever you will. As you will likely have already guessed, the “:” nomenclature used is for separating out the frame of reference (more formally known as vocabulary) used to contain each type and the named instance of that type. In that way, a graph node of overlaid type instance UML:Component calls out the use of a UML component type, and that it therefore complies with all the constraints and characteristics outlined within the UML standard for components. Likewise, the use of Animals:Chicken tells us that we are talking about a type of animal commonly known as “Chicken”. In both cases, the graph nodes are specifically referring to a single instance of both types. That is one UML:Component component and one Animals:Chicken chicken. Note also, that as where UML:Component relates to a very specific description of how to perceive and use the idea of a component, there is no such precise definition for Animals:Chicken implied here. For all that we might instinctively make the association with that type and our clucking feathered friends in the natural world, there is no absolute association at this point. Therefore, without a concrete definition of a vocabulary and its terms in place (as is the case with UML), the meaning (more formally known as semantics) associated with any given element within a graph cannot be precisely ascertained. That precision must be documented externally to the graph itself and referenced existentially before the actual intent behind a graph’s composition can be properly understood.
3.5. Applying Measurement Systems to Graph Context
There is, however, another way to draw the previous graphs.[17]
Let us take the Component-Chicken-Waffle example and this time frame it a bit better; that is, let us imagine that the ideas involved live in an imaginary space in our mind. This is the place where we bring together all the UML Types, Animals, and Breads that we know — sort of a smashed together list of all the things relevant across all three areas, if you like. In doing that, we can mark out that space evenly, so that it resembles a map of sorts, in much the same way that we often flatten out a physical landscape into a pictorial representation. After that, we can start to plot the various elements needed within our problem space, as shown in Figure 9.
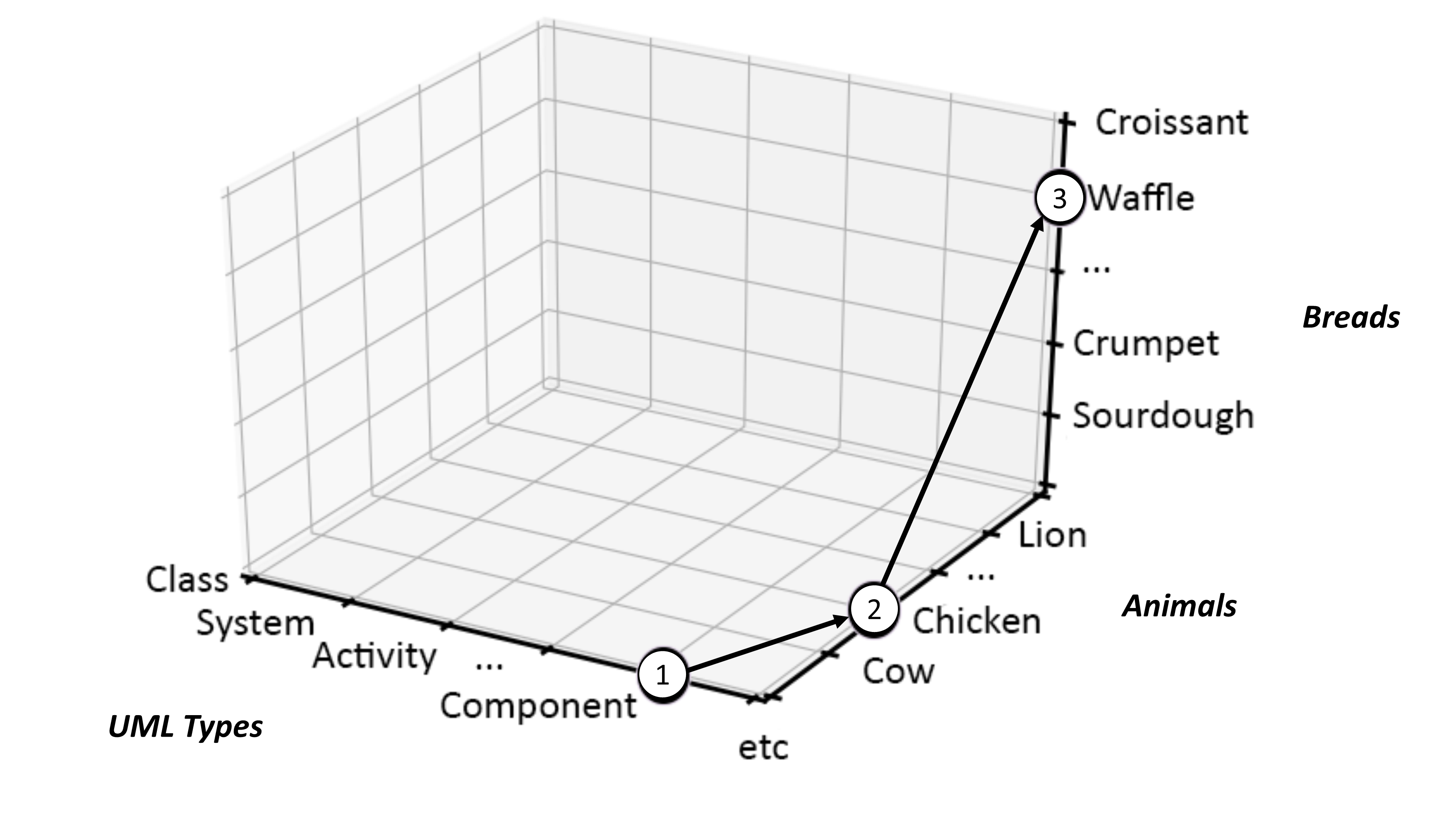
This “framing” actually brings two types of graph together; the first being the graph formalism described in Figure 8, which contains nothing more than nodes connected by arcs. The second, however, might feel more familiar to you, as it is the one taught in schools to draw out bar charts, histograms, line graphs, and the like. This type of graph is what mathematicians like to refer to as a Cartesian Graph or more properly a Cartesian Coordinate space or system [76]. In school, you were likely taught this by drawing two-dimensional X,Y graphs, in which two values can be plotted together to show some shared property in a two-dimensional space. But in Figure 9 we are using three dimensions to map onto the three ideas needing representation in our example.
With all that in mind, it becomes possible to make sense of Figure 9. In basic terms, it says that we are firstly dealing with a single thing or idea that is all about UML Components and not at all about Animals or Breads. Likewise, we are also dealing with a single thing or idea that is concerned with Animals and not at all about UML Types or Breads. Lastly, we are dealing with a thing or idea that is all about Breads and not at all about either UML Types or Animals. This then places our Component-Chicken-Waffle graph inside a Cartesian coordinate space, which in turn provides a measurement system allowing us to compare and contrast anything we place within it.
This is a very powerful idea, not only because it allows us to precisely pin down what we need to talk about, but it also allows us to blur the lines between the things needing representation. In that way, it is perfectly legitimate to talk about a concept requiring various degrees of chicken and waffle together, perhaps like a delicious breakfast, as shown in Figure 10.
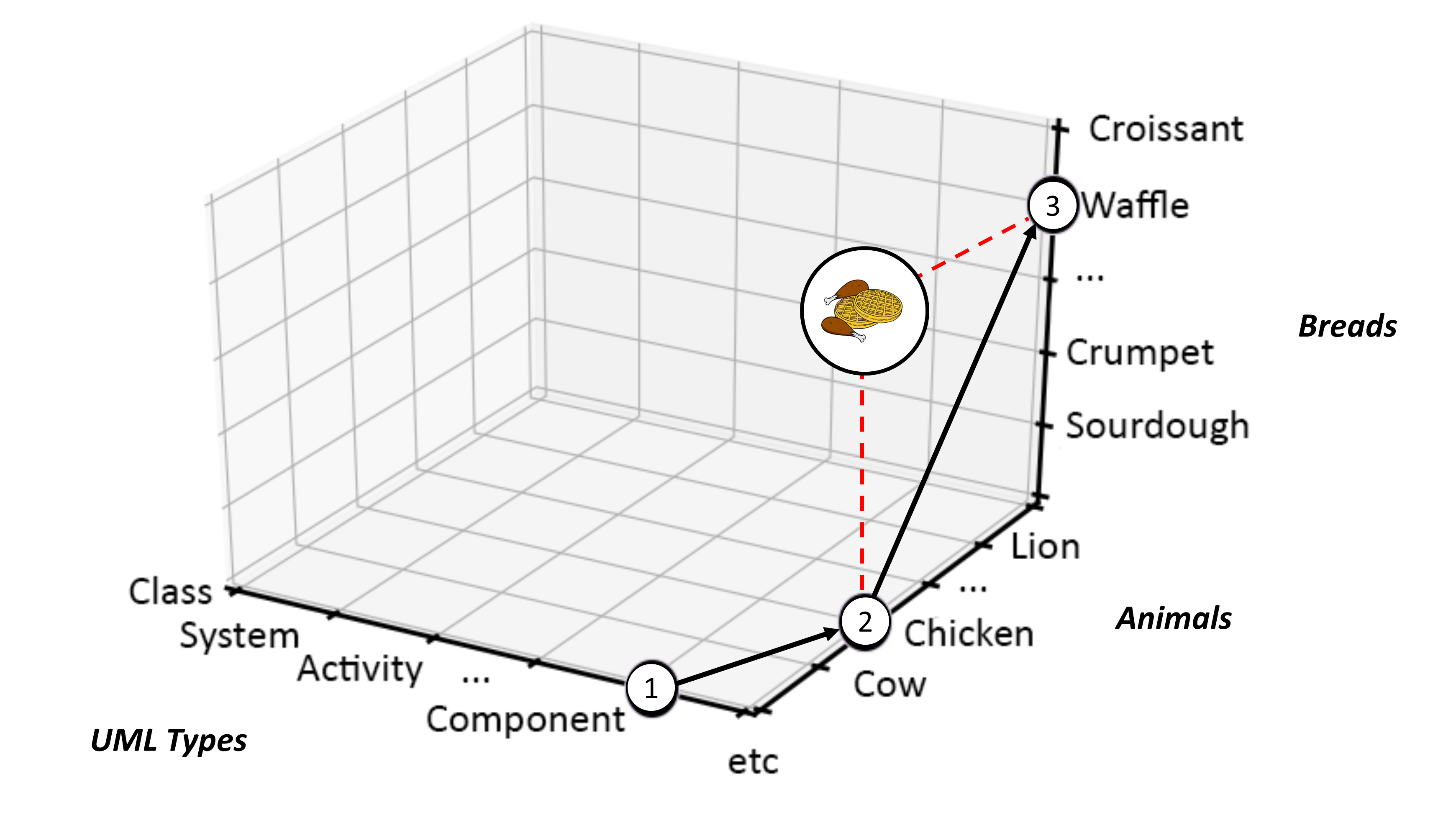
Notice here that the newly added breakfast node (linked using red dashed lines) contains no element of type UML:Component, no doubt that is because UML Components are not very tasty or are not on the breakfast menu! That is not a joke. It is a matter of precise and formal semantic denotation.[18] Nevertheless, speaking of taste, why don’t we consider not only assigning a specific type to each of our graph nodes, but further think about type as just one of any number of potentially assignable attributes, Succulence and maybe Deliciousness being others. If that were indeed so, then succulence and deliciousness would lie on a sliding, or continuous, scale, whereas, with type, we would normally consider things as being discretely of type, or not — as in an all or nothing classification.
In truth, however, both scales turn out to be continuous, as discrete measurement turns out to simply be a special form of continuous assessment, using especially course units between relevant points of measurement.
3.6. Continuous Cartesian Spaces
With measurement scales in place for all the features we need to denote — this specific example being Succulence and Deliciousness ascribed to individual Animal:Chicken instances — we can start to think of placing graph structures in a continuously gauged Cartesian space, as shown in Figure 11. This helps us assess (or rather denote) individual Animals:Chickens in terms of their Succulence and Deliciousness. Or perhaps we can think about arranging our list of Animals in alphabetical order and referencing them by their position in that list. That would give a three-dimensional numeric measurement, as shown in Figure 12.
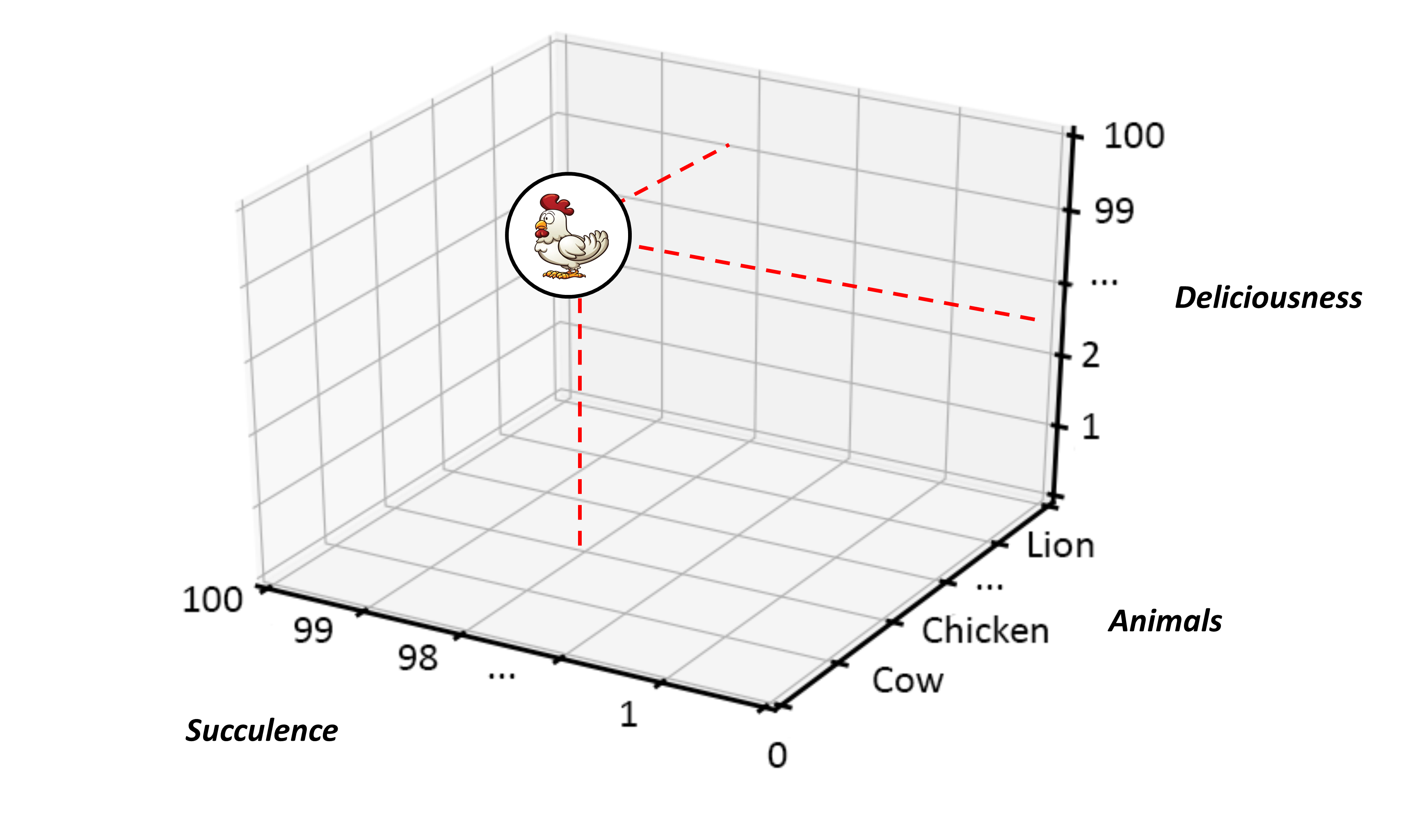
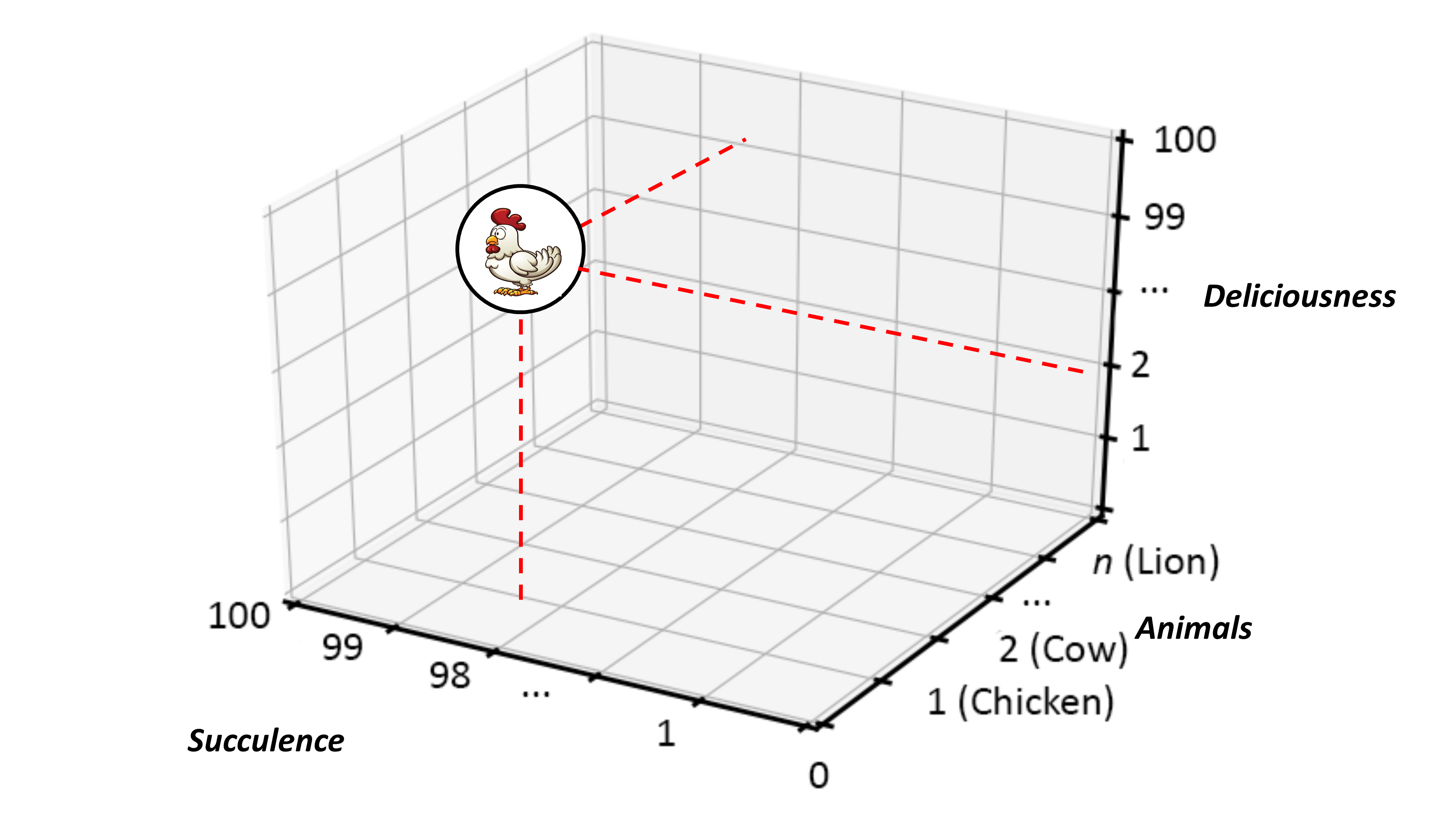
Now things start to get interesting. So, to complicate matters slightly, why not say that we are interested in two instances of Animals:Chicken, rather than one, and suggest that both offer different taste profiles, in which case we might see a representation not dissimilar to Figure 13.
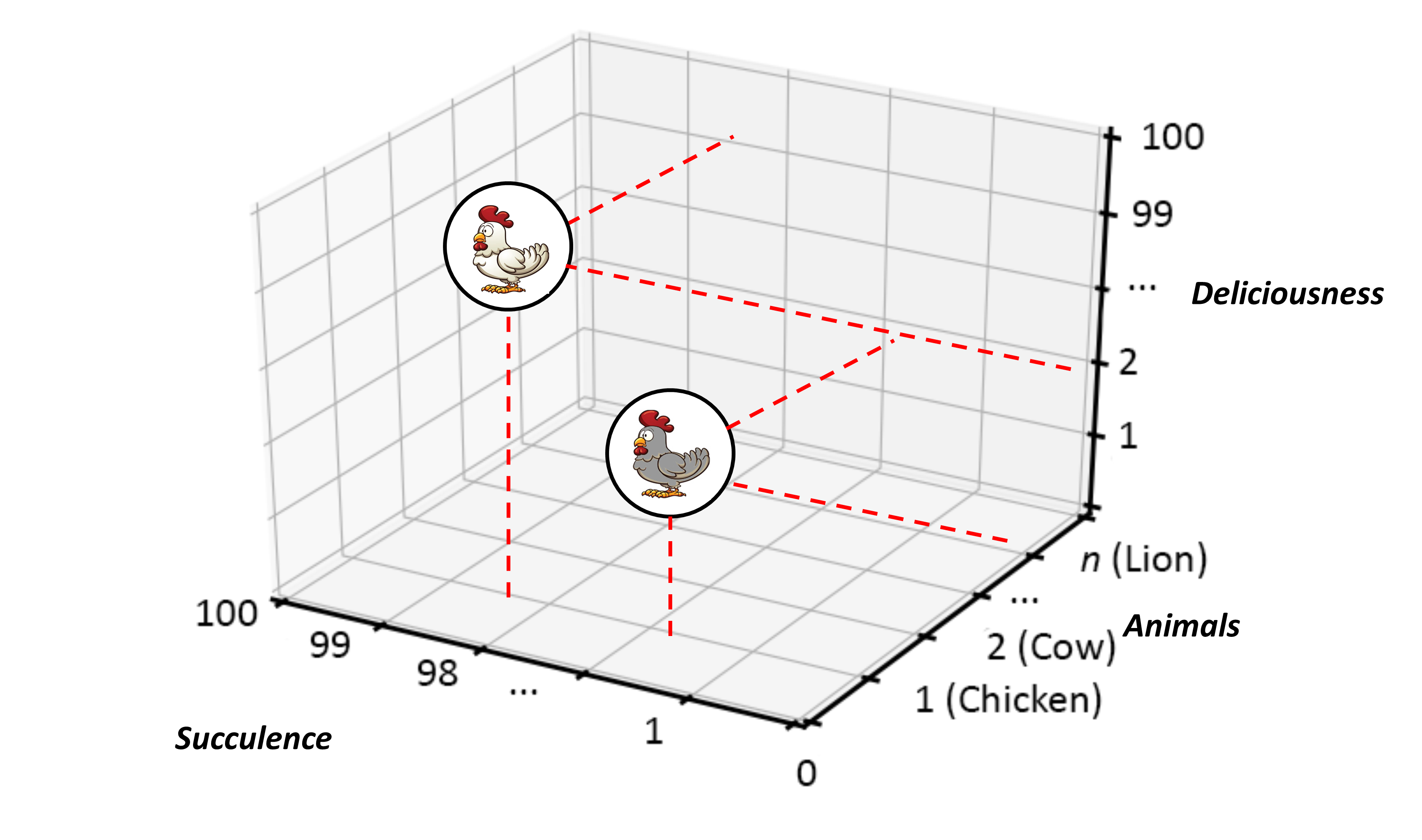
In Figure 13, it should hopefully be clear that both nodes have the same Animals type value of 1, thereby identifying them both as type Chicken, and that both chicken instances possess differing levels of Succulence and Deliciousness. In other words, our two “chickens” may share the same Animal type but do not have the same properties across the board. In this case, that simply implies that they taste different. In that, however, no indication is given as to which tastes better. Betterness, if there is such a thing, is not denoted here, so has no relevance to the context being described. It literally has no meaning.
3.7. Vectors
This scheme is useful because the mathematical measuring schemes imposed by the Animals:Chickens surrounding Cartesian space not only provides a mechanism to denote specific characteristics of interest, but it rather fortunately also provides a way to compare just how different any two Animals:Chickens might be across characteristics.
To make this comparison, the readings from each of the Cartesian axis associated with two Animals:Chickens can be combined into a mathematical system known as a vector, which uniquely identifies the position of each within its surrounding Cartesian space, as shown in Figure 14.
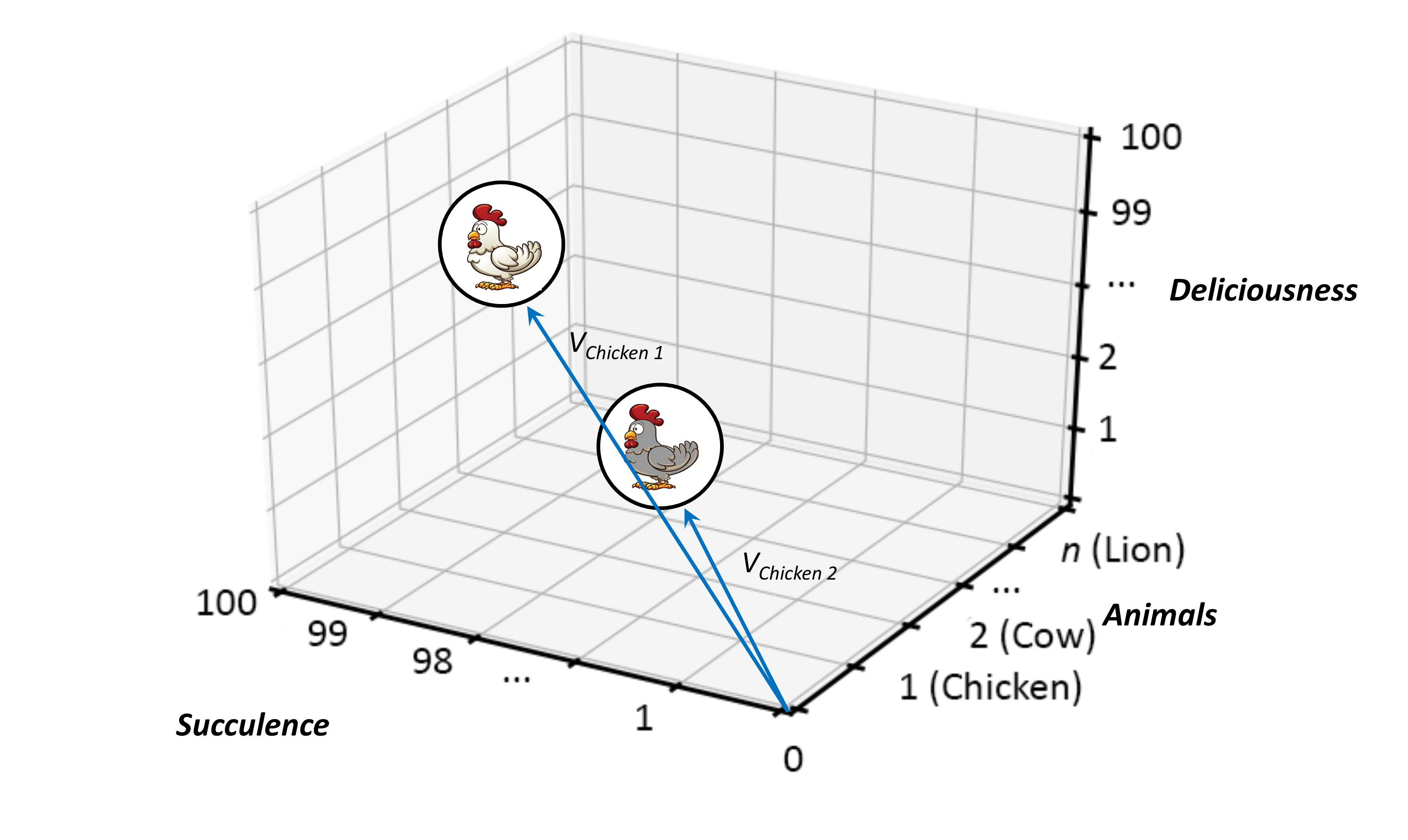
Vectors provide further mathematical advantage here, as they can, given that they contain both magnitude and direction, be used as data structures to store collections of coordinates. As such, they can be mathematically represented using arrays of numbers, where each array element corresponds to a value taken from the axes of any surrounding coordinate space. Similarly, vectors can be represented by a straight line, with its start point conventionally at the origin[19] of its Cartesian system. As a result, when vectors are drawn in such spaces, the space becomes what is known as a Vector Space [77], rather than a Cartesian Space.
3.8. Graph Node Comparison Using Vectors and Trigonometry
When a Vector Space and relevant vectors combine, the resultant framework allows questions to be asked of the things or ideas being represented in vector form and their associated characteristics. In other words, the characteristics of two or more graph nodes can be compared mathematically and with great precision, as shown in Figure 15.
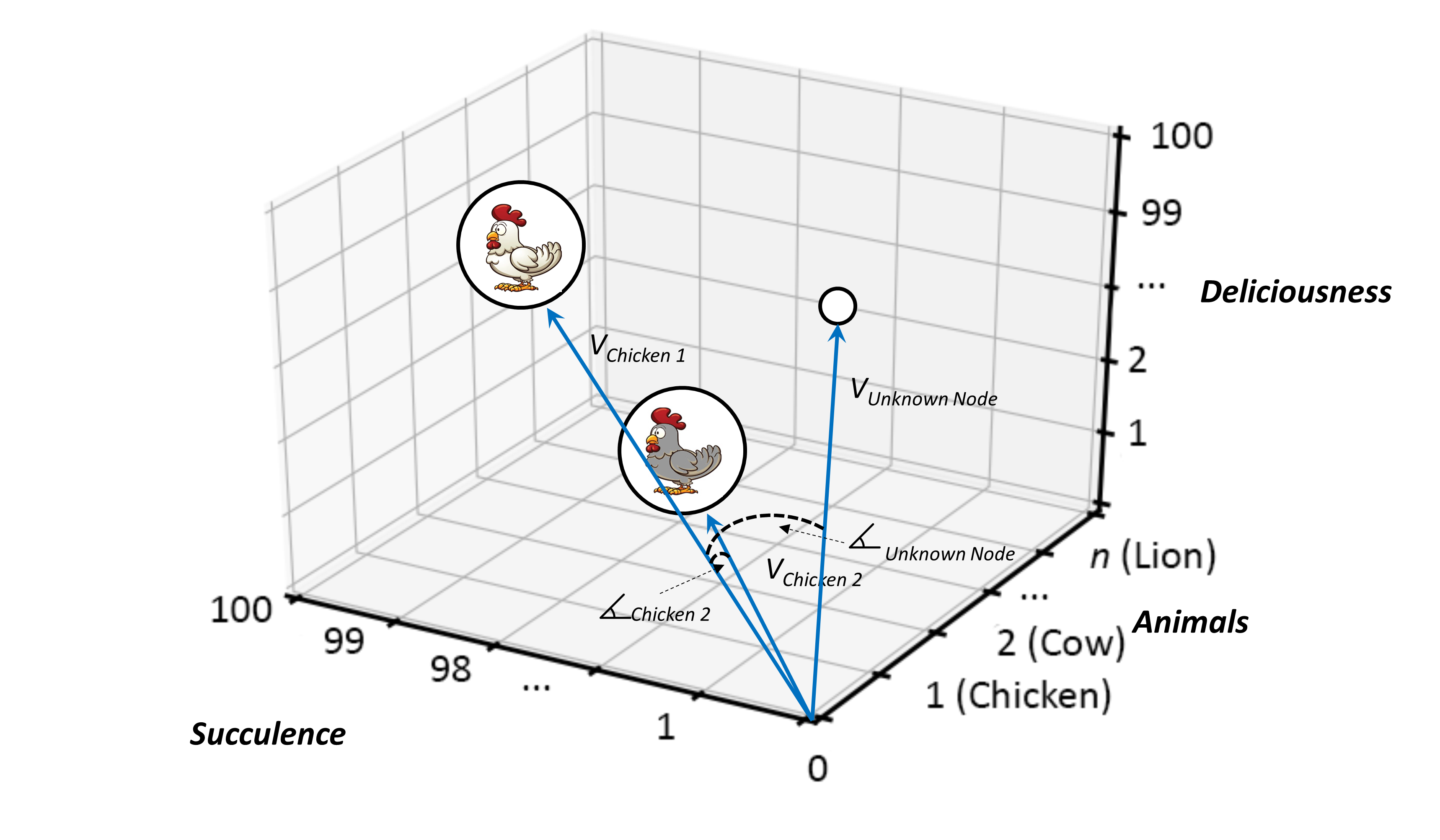
In starting to ask questions, then, the trick is to first forget about a vector’s size for a moment, by temporarily setting it to 1. This then produces what mathematicians refer to as a Unit, or Normalized Vector, and which maintains the same direction as its donor parent. From there on in, comparing any two node locations within a vector space becomes a matter of studying the angle between their respective unit vectors, using the branch of mathematics known as Trigonometry.
Trigonometry, or “Trigs” for short, is one of the basic mathematical staples doled out in school. You remember the drill. It was all about sines, cosines, tangents, and so forth. More formally, though, trigonometry is the branch of mathematics that deals with the relationships between the angles and sides of triangles — particularly right-angle triangles. It is, therefore, used to study the properties of triangles, circles, and other geometric figures, as well as to solve problems involving angles and distances, as we shall do here. The basic concepts of trigonometry include the definitions of the six trigonometric functions: sine, cosine, tangent, cosecant, secant, and cotangent, the relationships between these functions, and their application in solving problems.
That brings us to the outputs provided by these basic trig functions, which are all limited by upper and lower bounds of 1 and -1. With those limits in mind, a mathematical sidestep can next be used to great effect.
If you apply a mathematical modulus function over any trig output — which simply means throwing away any minus sign present — then something rather magical happens. At face value it merely reduces the range of trig output from -1 to 1 to between 0 and 1. Beyond that, however, it miraculously bonds together three highly valuable branches of mathematics. The first we know already, in trigonometry, but what is interesting is that both mathematical probability and continuous logic produce outputs within the same bounded numeric range as the trig-modulus trick we have just played. In that way, trigonometry, probability, and logic map onto the same solution space, meaning that they can all be used to understand the results from the same mathematical test. To say that another way, if you want to know the probability of two nodes in a graph being identical, then you also get the degree of truth associated with that proposition and a route to find the actual angle between the vectors representing both nodes when you apply the appropriate calculation. All are really just mathematical measures of proximity.
This is why the emphasis on John von Neumann’s work early on in this book. Whereas the normally used version of logic, first introduced by George Boole in 1854 and common to most digital computers today, is only interested in the numerical extremes of 0 and 1, von Neumann’s logic is more encompassing and can accommodate the full range of values on a sliding scale between 0 and 1.
You will hopefully recall that George Boole, the mathematician behind Boolean Logic was particular and extreme in his views — stating that logical truth was a discrete matter of all or nothing. In his mind, therefore, a proposition was either wholly true or wholly false. Just like a switch, it was all in or all out, all on or all off. There was no element of compromise in between. Von Neumann, on the other hand, was much more liberal in his position. In his world view, a proposition could be partially true and partially false at the same time. In that way, he considered the world in terms of degrees of truth. Overall therefore, Boolean logic is a subset of von Neumann Logic. Or, in both mathematical and philosophical terms, von Neumann wins. End of story.
In layperson’s terms, this all boils down to the same thing as asking, “How likely is it that something is true?”, such as in the question “How likely is it that that bird flying overhead is a chicken?” Indeed, we might even rephrase that. So, asking “How logical is it that that bird flying overhead is a chicken?”, gives exactly the same proposition as asking “how likely is it?” Chances are that it is not a chicken, so in Von Neumann’s logic that would give us an answer of less than 1/2, but more than 0. In that way, we might, for instance, mathematically reason that there is a 22% chance that the bird is a chicken. Or to rephrase; the probability of the bird being a chicken, based on all known properties and their available values is 0.22. Likewise, it is 0.22 logical that the bird in question is a chicken. Both propositions are mathematically the same. Von Neumann’s continuous logic and mathematical probability behave as if one. Lastly, it turns out that the cosine of the angle between a vector representing a chicken and the specific one that does not in our question, equates to 0.22. That means that the angle between the two vectors is 77.29096701 degrees.
But what are the mechanics of this mathematical love-in? The answer, it turns out, is both mathematically simple and blissfully elegant.
3.9. Cosine Similarity
Cosine similarity [78] is a measure of closeness, or sameness, between two non-zero vectors. Think of it like this: If two identical nodes (points translated into vectors) in any vector space were to be considered, then both would lie at the exact same position within that space — one atop the other. Likewise, they would also possess identical vectors, meaning that both vectors travel along identical paths through the vector space. Identical trajectories also mean that there is no angle between their respective paths, or, more formally, the angle between the trajectories of both vectors is 0 degrees. Now, take the cosine of 0 (zero) and that returns 1 (one), which, in terms of both mathematical probability and continuous logic, corresponds to absolute certainty or truth. In other words, there is complete assurance that both nodes are identical in nature. Or, when thinking in terms of the semantics that both vectors could represent, they carry identical meaning, and, therefore, for all intents and purposes, represent the exact same thing.
Now, consider the opposite extreme, as in when a cosine similarity test returns 0 (zero). Instinctively, it might be assumed that the two vectors being compared represent completely different things or ideas and that is kind of true, but not quite. It means, in fact, that their trajectories from the origin in any given vector space are at a 90 degrees tangent to each other about some particular plane (or set of dimensions/axes), which does give a very specific measure of difference in terms of denotational semantics, but not necessarily a “complete” difference. That is unless it has been externally agreed (denoted) that perpendicular vector orientation does indeed represent full and complete difference. That is because the idea of difference can be subjective, even from a mathematical point of view, as where the idea of absolute similarity is not.
Nevertheless, the use of cosine similarity provides a valuable tool for assessing the proximity of graph nodes, when mapped and measured as vectors in some vector space. It also provides a clear way of understanding just how alike any two nodes are within a graph. And in a complex ecosystem of dynamically changing systems and actors, that is important.
3.10. Bringing This All Together
Right, that is enough talk of chickens and waffles for now. Next, we ground ourselves firmly back in the world of IT architecture and lay down some basic rules for modeling systems in hyper-enterprise contexts. We will state them first, then revisit each in turn to outline why it is important:
-
Document and agree what you know
State the facts and prioritize them in terms of what is important and what needs to be achieved. -
Check and double-check your perspective
Remember that yours may not be the only relevant viewpoint on a problem or solution space. This is especially true in large and complex contexts. What might seem clear to you, could well come across differently to others. As a simple example, think of a sink full of water. To your everyday user, it likely represents no more than a convenience for washing, but to an ant or spider it might as well be an endless ocean. Recognizing that the world is not the same across all vantage points is, therefore, truly important, and accepting more than one interpretation of a situation or thing can often be useful, if not invaluable. -
Schematize what you have documented and agreed
Create whatever tried and tested architectural diagrams you think might be useful and make sure that all relevant stakeholders are bought into your vision. -
Translate your schematics into a generalized graph form
Get to a point of only working with nodes and arcs, with both types properly justified in terms of unique (wherever possible) identifiers, characteristics, attributes, and so on. -
Use your attribute and characteristics to create measurable dimensions (axes) in an abstract vector space
Construct an n-dimensional vector space, where each dimension corresponds to an attribute, characteristic, aspect, or feature needing architectural representation. -
Agree on how vector difference should be defined
Establish guidelines on what types of mathematics should be used to establish vector difference, and how that difference should be measured. -
Embed your graphs into their respective vector space(s)
Translate nodes into n-dimensional vectors and arcs into a separate set of two-dimensional vectors, containing only start-node identifiers and end-node identifiers.
In the case of our original graph example, then, that then gives a pair of vector spaces, as shown in Figure 16.
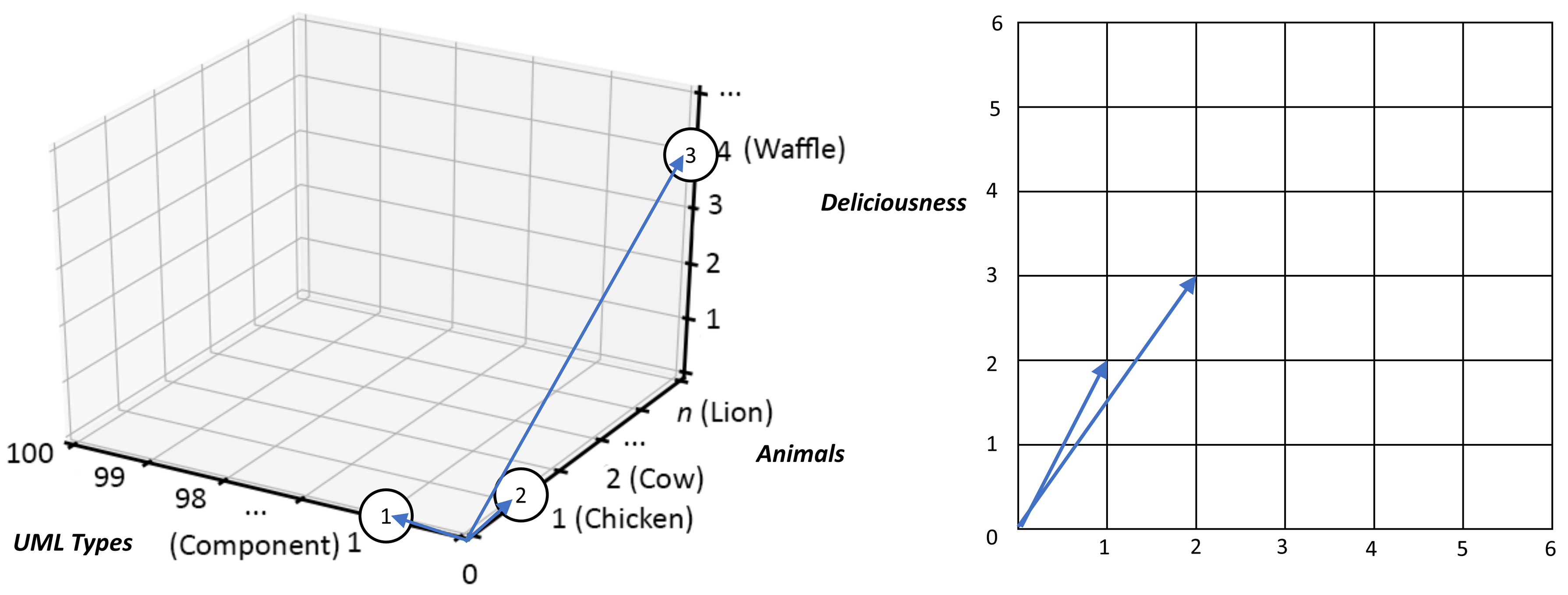
The three-dimensional vector space on the lefthand side of Figure 16 therefore shows the three nodes in our graph and thereby captures each node’s type. This space could, of course, be extended over five dimensions, so that, for instance, degrees of Succulence and Deliciousness might also be included — but in that case the resultant space would be difficult to visualize here. The two-dimensional vector space on the right illustrates how the various nodes in the graph are connected and makes it explicit, for example, that the node labeled “1” is connected to the node labeled “2”. That is via the vector  [20] [79]. Likewise, it further explains that the node labeled “2” is connected to the node labeled “3” — via the vector
[20] [79]. Likewise, it further explains that the node labeled “2” is connected to the node labeled “3” — via the vector  .
.
With both of these vector spaces in place, we now have a way of representing almost all architectural schematics in a graph-based vector form.
3.11. The Value of Vector Spaces in Modeling Ecosystems
By outlining the two vector spaces in the previous section, we have actually covered a lot of ground quickly. First, we have moved the language for architectural expression away from one less formal and open to interpretation — as in the “boxology” of drawn shapes and lines — to one which still accommodates informality of design thinking, but which is much more aligned with precise measurement and unambiguous semantics. Next, we have also found an open-ended way to capture both discrete and continuous measurement. Last, we have overlaid a range of mathematical techniques that can assess important architectural characteristics across the board — not least of which is similarity or sameness.
So far, so good. But now the question is why?
Almost certainly a major difference between classical Enterprise Architectures and hyper-Enterprise Architectural contexts is that ecosystems demand change over time and sometimes that happens beyond the control of the organizations, systems, or participants that they engulf or interact with. In one word, they “evolve”, and that evolution is just as likely to come from agreement en mass, as it is from any single decision or isolated influence. With that, the very idea of hyper-enterprise contexts breeds unpredictability and risk; two things that architects, business executives, and the like generally agree are not good.
But here is the thing. In a graph-based, vector-view of IT architecture, time just becomes one more dimension to consider within the vector spaces in use. So, in a vector-centric world, it therefore is not some extraneous threat, but something that can be accommodated and managed with relative ease. In that regard, it is just one additional mathematical axis (or measurement scale) to be considered. In truth then, by way of vector analysis, time and change actually become an architect’s friend rather than their enemy; immediately affording a way to formally compare the various states of any entity of interest as it plays out its role within some grander ecosystem context. Furthermore, by using techniques like cosine similarity, the implications of time can be rigorously reasoned and perhaps predicted. And that includes risk. If, for instance, the current state of an entity, artifact, property, attribute, or so on is known (through its vector position) and its change history is also understood (through a series of trigonometric calculations), then it becomes a relatively simple analysis task to project out into some future vector plane to guess where the entity’s evolutionary progression might be heading. Likewise, cosine-change-history can be used to help extrapolate out hidden influences driving any such trajectory.
Adding a time dimension can thereby help significantly de-risk hyper-enterprise IT architecture. By the very nature of evolutionary processes, all nodes and arcs in a time-dimensional vector space must be subject to change somehow. This is especially important when thinking in terms of integration. Quite legitimately, what might be presented as a strong and important relationship at one point in time, may well be weakened the next. In simple terms, relevancies may well change, and connections might break or be shown wanting. So, in circumstances where important elements of an architecture fail, how might IT architects look for alternatives?
3.12. Asset Approximation Using Vector Proximity
Here again, a vector-view of IT architecture comes to the rescue. If we look at examples of ecosystems in nature, then a major lesson to be learned explains that perfection is often impractical, if not implausible or even impossible. But sometimes imperfection carries its own advantages. It can lead to serendipity, for instance, one of evolution’s best friends.
The point here is that good enough is often good enough. Cows are equally as able to feast on silage as they are on fresh clover; they simply make do and their species survives regardless. The overall system that is a cow’s lifecycle simply adapts, adopts, and moves on. In short, approximation is good news in the world of ecosystems.
But how does this translate into the hard-nosed world of the IT architect, and our well-drilled practices based on tight conformance to requirements? The simple answer is that, as IT architects, we should, of course, remain focused on the same precise targets as always, but be somewhat prepared to blur their edges. Think of it as appreciating the various outer rings of a bull’s eye’s roundel. Or perhaps better, think in terms of architectural assets having an umbra[21] of definition. That is to say, they have a well-formed core of characteristics that taper off, rather than ending abruptly. Net, net, all hard-edged targets remain, but implanting them into vector-based frameworks opens up the opportunity to surround their boundaries in a blur of tolerable approximation. Absolute must-haves can sometimes, therefore, be translated into close compromises. In vector terms, this simply means that rather than describing a node singularly in terms of its specified dimensional coordinates, architects may consider a region surrounding it as being approximately equivalent. In that way, they can easily search over what they know of a given ecosystem and quickly surface close counterparts in the event of links going down or assets losing their value. Maintaining point-to-point integration then becomes a matter of understanding vector differences and applying fixes so that those differences tend toward zero.
In summary, this is like running a Google®-like [80] query over a complex IT architecture in search of compromise. As such, when things change in an ecosystem, an asset’s surrounding environment can be surveyed to find its closest-possible equivalents or contact points to those in place when the ecosystem was last architecturally sound or stable. Finding closest approximates through multi-dimensional fit-gap analysis, therefore, helps reduce risk and decreases any development effort required to keep up with environmental change. This might feel untried and complex, but it is certainly not the former. The use of “Google-like” was quite deliberate. Google is amongst many web search engines to have successfully used vector-based search methods for years now [81]. Indeed, vector-based search has been a staple of information retrieval research ever since the 1960s [82] [83].
3.13. Star Gazing and the Search for Black Holes
On to one more advantage.
When you ask Google for the details of a local plumber or what the price of milk might be, how do you think it gets its answer back so quickly? Does it throw some massively complex Structured Query Language (SQL) statement at a gargantuan database of all human knowledge? Of course not, not least for the reason that it would take longer to return than Deep Thought required to give its answer of “42” in Douglas Adams’s famous book, The Hitchiker’s Guide to the Galaxy [84]. A long time for sure and easily way longer than any Google user would tolerate. No, of course, it was a trick question. Google does not rely on the eloquent and reliable capabilities of SQL. Instead, amongst many tricks in its box of magic, it uses vector frameworks and vector algebra.
When the Web’s search bots crawl its structure and find a new webpage, they essentially chew it up, spit out the connecting tissue, and weigh up what is left. In doing that, they use techniques similar to those described above, first categorizing worthwhile content then grading it against various category headings. In vector terms, that gives the dimensionality of the web page and a set of measurements that translate into a cloud of points — graph nodes in the form of metered vector end points. These are then indexed and slotted into the grand galaxy of points that is Google’s understanding of the entire accessible World Wide Web.
So, in a very tangible way, when you ask questions of a web search engine it is like staring up at a clear night’s sky. All the Web’s content is mapped out as one great star field of points and connections. Amongst other things, such engines will translate your query into a set of vectors, then cast them out into the night sky that is its understanding. Then all they do is look for stars within the proximity of your query. In essence, they look for overlaps in the umbra of its understanding with that of your enquiry. If and when matches are found, and within tolerable distance, they then count as search results and, barring a few well-placed adverts and so on, the closer the proximity, the higher up the search ranking a result appears. In short, the nearest stars win.
Having said that, this astronomy-based analogy points toward at least one additional benefit for vector-based IT architecture. Believe it or not, search engines like Google, do not and cannot know everything about the Web. For a whole host of reasons, that is just impossible and, likewise, there are not many IT architects in the world who can genuinely claim to know every single detail about the systems that they design and deliver. Again, that is just silly. It is more or less impossible. Parts of the night sky are destined to stay dark, and likewise it is not unusual for regions in a complex IT architecture to be overlooked. Peering into such voids is just a pointless activity.
Or is it?
In many ways, this challenge is like the search for black holes in cosmology. The scientists rarely, if ever, find black holes by staring directly out into the vastness of space. Rather, they apply broad scanning techniques and look for regions where the presence of black holes feels likely. Then they cycle in, each time increasing the level of detail, until they hit or not. In that way, it is not so much the black hole that gives itself up, but rather the context within which it is hiding. This is rather like being asked to describe the shape of a single jigsaw piece without having access to the piece itself. The way to solve this problem is to ask for access to all the other pieces in the jigsaw, then, once assembled, the remaining hole will be the exact mirror image of the piece you seek. Rather than describing it precisely by direct view, you do the same by describing the hole it would leave when taken away from the completed jigsaw. Both descriptions are, therefore, for all intents and purposes the same.
Now, surprise, surprise, a similar trick can be played with Ecosystems Architecture. Once all the facts have been gathered, filtered, and plotted in line with the ideas of vector space representation, then that affords the opportunity to step back and look for unusual gaps. These are the blind spots in IT architecture, the gotchas that every experienced IT architect knows will jump out and bite them at the most inconvenient of times — the gremlins in the works, if you will.
So, might there be a way to help us hunt down these gremlins? Well, when coordinate-based mathematics is in use, as with vector spaces, that is exactly what is available. The mathematical field of homology [85], for instance, essentially deals with this challenge, through the idea of multi-dimensional surfaces — think of the various undulations of a mountain range, but not just in three dimensions. It tries to ask if the various characteristics of such surfaces can be considered as consistent. In two dimensions, that is not unlike putting up two maps in the expectation that a road might be followed from one to the other. If the maps do not cover adjacent terrain or if either or both is wrong in some way, then passage is not guaranteed and clearly there is a problem. Consequently, it is this exact idea of consistency, or rather lack of it, that homology homes in on, and which can be used to seek out “gaps” in multi-dimensional vector spaces. Homology, therefore, allows IT architects to perform the exact opposite of a Google search, by asking what is not present, rather than what is. By looking at the mathematical consistency of an ecosystem’s vector space, for instance, it can pick out jarring irregularities and point the way to the discovery of hidden actors, events, and more besides. This is not only helpful from the point of view of completeness, but also helps regarding essentials like audibility, regulatory compliance, testing, and so on.
This is indeed valuable, as when modeling we, as architects, regularly draw up what we know and want to share. However, we often fall victim to our self-confidence, believing all too often that we have a full understanding, when perhaps we do not. We must always, therefore, make a habit of questioning what we know and what we do not. For instance, is that space between those two boxes we drew on the last diagram deliberate? Is it going to remain open? Will that be forever, or just for now? Was it always a space? These are all valid questions. Indeed, in the case of physical engineering, the idea of voids and gaps has always been critical, not least because of its importance when balancing weight, ensuring structural integrity, and so on. In architectural terms then, we need to take the idea of gaps very seriously indeed and think long and hard about whether they are intentional or not.
3.14. GenAI
As implied, homology can therefore help understand where an architecture or IT system might well be lacking, as and when areas of total darkness are indeed found. These represent zones of missed requirements or bypassed opportunity — areas that are quite literally “off the map”, as it were. They identify matters of potential architectural concern and/or work to be done. They do not, however, necessarily point to a need for human intervention.
The use of the jigsaw analogy above was not coincidental, as it aligns perfectly with the target output of a new type of AI. Known as Generative Artificial Intelligence, or GenAI for short, it aims to automatically extend on the inputs it has hitherto been given; that is, to generate new material beyond that which it has seen.
The recent rush of excitement in ChatGPT [86] provides a great case in point. As a chatbot, it was designed specifically to soak up the Web’s facts, trivia, and happenstance, and then relay it back to interested conversationalists in ways that feel fresh, authoritative, and engaging. So, in essence, that makes it a gargantuan “gap-filler”, designed to augment the knowledge and capability of its users.
Now, admittedly, AI experts are in a quandary about the rights and wrongs of such skill, and also admittedly, GenAIs can be prone to hallucination [87], but when they get things right, the results can be impressive.
But here is the thing. The output from GenAI is not restricted to natural language, as required in casual bot-like exchanges. No, GenAI can output audio, video, and way much more. And not least on that list is program code. So, in a very real sense, it is now becoming plausible to use advanced AI to both find and fill any gaps found in human-designed IT systems, regardless of human-limited restrictions related to complexity and scale.
Furthermore, GenAI is growing in competence and flexibility at an astonishing rate. For instance, several ideas and approaches are already being worked through to equip the foundation models under GenAI with the ability to use external tools like search engines, web browsers, calculators, translation systems, and code[22] interpreters. This especially includes work on Large Language Models (LLMs) in particular aimed at teaching them to use external tools via simple API calls. This thereby not only allows them to find and fill in gaps associated with user input, but also to find and fill in gaps their own ability in autonomic ways.
As of August 2023, examples of ongoing work in this vein can be seen as follows:
-
Tool Augmented Language Models (TALM) combine a text-only approach to augment language models with non-differentiable tools, and an iterative “self-play” technique to boot-strap performance starting from a limited number of tool demonstrations
The TALM approach enables models to invoke arbitrary tools with model-generated output, and to attend to tool output to generate task outputs, demonstrating that language models can be augmented with tools via a text-to-text API [88].
-
Toolformer is an AI model trained to decide which APIs to call, when to call them, what arguments to pass, and how to best incorporate the results into future token prediction
This is done in a self-supervised way, requiring nothing more than a handful of demonstrations for each API. It can incorporate a range of tools, including calculators, Q&A systems, search engines, translation assistants, and calendars [89].
-
LLM-Augmenter improves LLMs with external knowledge and automated feedback using Plug-and-Play (PnP) modules
-
Copilot [91] and ChatGPT Plugins are tools that augment the capabilities of AI systems, like Copilot/ChatGPT), enabling them to interact with APIs from other software and services to retrieve real-time information, incorporate company and other business data, and perform new types of computations [92]
-
LLMs as Tool Makers (LATM) [93] — where LLMs create their own reusable tools for problem-solving
One such approach consists of two key phases:
-
Tool Making: An LLM acts as the tool maker that crafts tools for given tasks — where a tool is implemented as a Python® utility function
-
Tool Using: An LLM acts as the tool user, which applies the tool built by the tool maker for problem-solving
Another lightweight LLM, called the Dispatcher, is involved, which determines whether an incoming problem can be solved using existing tools or if a new tool needs to be created. This adds an additional layer of dynamism, enabling real-time, on-the-fly tool-making and usage.
-
The tool-making stage can be further divided into three sub-stages:
-
Tool Proposing: The tool maker attempts to generate the tool (Python function) from a few training demonstrations
If the tool is not executable, it reports an error and generates a new one (fixes the issues in the function).
-
Tool Verification: The tool maker runs unit tests on validation samples; if the tool does not pass the tests, it reports the error and generates new tests (fix the issues in function calls in unit tests)
-
Tool Wrapping: Wrapping up the function code and the demonstrations of how to convert a question into a function call from unit tests, preparing usable tools for tool users, and so on
The tool user’s role is therefore about utilizing the verified tool(s) to solve various instances of a task or problem. The prompt for this stage is the wrapped tool which contains the function(s) for solving the challenge in hand and demonstrations of how to convert a task query into a function call. With the demonstrations, the tool user can then generate the required function call in an in-context learning fashion. The function calls are then executed to solve the challenge accordingly.
The Dispatcher maintains a record of existing tools produced by the tool maker. When a new task instance is received, the dispatcher initially determines if there is a suitable tool for the task at hand. If a suitable tool exists, the Dispatcher passes the instance and its corresponding tool to the tool user for task resolution. If no appropriate tool is found, the Dispatcher identifies the instance as a new task and solves the instance with a powerful model or even invokes a human labeler. The instances from a new task are then cached until sufficient cached instances are available for the tool maker to make a new tool.
3.15. What Does this Mean for Architectural Practice and Tooling?
Make no mistake, working at hyper-enterprise levels will prove very challenging. Not only will the scale of architectural responsibility and associated workload increase by several factors, but the added vagaries and increases in abstraction involved will certainly be enough to overpower even the most able of IT architects. Furthermore, and as you now know, this sea change in capability leads to the need for some pretty advanced mathematics, and an appreciation for its position in a much broader landscape of deeply theoretical ideas.
Summed up, that is a big ask.
Nevertheless, there is not necessarily any need for concern or despair. As our understanding of IT architecture has improved, so have the tools and technologies within our reach. As already explained, this is an age-old story. As human need moves on, it is so often supported by technological advance. The Industrial Revolution rode on the back of our harnessing of steam power, for example, and likewise, many modern fields of science would not have been possible without the arrival of cheap and plentiful electronic computers. A perfect example can be seen with the relatively recent arrival of Complexity Science. As an undergraduate student at Dartmouth College, Stuart Kauffman [62] found himself staring into a bookshop window and realized that his life would be caught up in the eclecticism of modern science. In that, he marveled at the thoughts of scientific pioneers like Wolfgang Pauli, who had previously remarked that “the deepest pleasure in science comes from finding an instantiation, a home for some deeply held image”. What he was reaching out to would become known as the scientific study of deep complexity, a discipline he would later help establish. Some 30 years on, he had captured its nature in the principles that make physical complexity real. At its peak, he listed life itself as complexity’s greatest achievement and came to understand that physics had to embrace spontaneous chaos as well as order. Somewhere in the middle of both was evolution, and the fact that both simple and complex systems can exhibit powerful self-organization. That much became clear as his work progressed and he teased out the models and mathematics needed. But Kauffman was breaking out at a particularly fortuitous time. To test his ideas through manual experimentation would have proved impossible, as the very thing he was interested in was the same as the stubborn obstacle that had blocked scientific progress in the past, in that complexity feeds at scales well beyond easy human reach. But this time around, Kauffman could sidestep. Personal computers had just become commonplace and were starting to spread across the desks of his academic colleagues. These were more than fanciful calculators, and in the right hands Kauffman knew that they could be deftly programmed to model the aspects of complexity that had stumped his predecessors. In that way, by using modern computing power to augment human skill, Kauffman not only prevailed where others had not, but he blew the doors off previously blocked avenues of investigation. Computer Aided Research had found a sweet spot.
Dial forward to the present day and we find ourselves confronted with a veritable cornucopia of technical capabilities. We have long moved on from personal computers to augment the capability of the individual or group. Today we talk in terms of millions of easily accessible compute nodes, curtesy of the planet’s various cloud compute platforms. Furthermore, we easily measure AI variants, like neural networks, in terms of billions of nodes — increasingly counting even more than in the human brain.
This all boils down to one simple fact: just because a hyper-enterprise problem might be beyond the natural talents of the IT architects assigned to tame it, that does not mean that we do not have the calibre of tooling available to jump the obstacles in place. In fact, it is quite the opposite. To briefly return to our search engine example, companies like Google have harnessed the essentials of vector-based modeling with such success that they now top the list of the world’s most illustrious technical enterprises. So, make no mistake, we have already nailed the application of the highfalutin mathematics involved many times over. Indeed, we now even have a generation of cyber-hungry, phone-clicking millennials who depend upon it. This stuff is so in our face that it is not funny, and we have been ably applying tools and techniques to subdue hyper-headful overflow for decades. That is what modern information retrieval is all about. So sure, it is not beyond the capability of the IT architect community to adopt, adapt, and move on? This will not only push us out beyond the headful, but it will reshape our role in the world forever.
This will happen, make no mistake. Before long, AI-infused IT architecture will be a thing, and likely it will cloak its formidable capabilities behind a façade that will obfuscate the need for any real understanding or appreciation of the scale and complexity playing out behind the scenes. This is what good technology does. It makes the complex feel simple, and that presents an abundance of challenges for professional practice in the future.
Should we allow IT architects to practice without clearly demonstrating their proficiency at the wheel, as well as their understanding of the advanced tools and techniques we are expecting them to drive? If not, what should we teach the next generation of architects to keep them and those in the way of their outcomes safe? Should we allow the intelligence in AI to augment and take the lead, and should we trust its proclaimed ability to assist, rather than hinder or harm? Furthermore, should we slacken our tolerances around professional accreditation in the same way that we are advocating the widening of focus — to embrace umbral appreciation — at the ecosystems level? These are moral and professional questions that will need to be worked through, but certainly, the tools and techniques needed to help the jump to Ecosystems Architecture are very real and with us now. All that is really needed is an increased awareness amongst the global IT architect community and continued endorsement from various accrediting bodies, like The Open Group.
This position is further supported by a generation of new technologies, already perched on the horizon.
The ideas behind quantum computing may seem alien and new, but actually they are neither. Classical computers, or digital computing machines as they might be more correctly labeled, actually make up a subset of all possible ways to compute, and, as such can be seen as part of a much broader class of computers, which included quantum devices. All electronic switches are partially quantum-like in their makeup, for instance. For all that we usually consider such devices to be in either an on or off position, by virtue of the electrons flowing across them, when in the act of switching, there must come a point where a switch’s last few electrons are in transit between a its two poles. So, in that miniscule moment, the switch is neither on nor off, and it is extremely hard to ascribe which of the two positions is most relevant. This is one small step removed from the very essence of the quantum world, in the idea of super position — the fact that quantum systems can be seen to be in multiple states all at once. And to describe this super-class of switching capability, it is no coincidence that vector-based mathematics is used. In the world of quantum mechanics, the abstract vectors we have labored so hard to describe here actually carry a special name. In that world, they are known as eigenvectors — after the German term meaning “own”, and which is a good way to think of values or vectors that are “characteristic” in one way or another. Likewise, quantum mechanics relies heavily on the idea of probability to consider how superposition might change over time[23] into an identifiable state once inspected; this is just the flip side of a coin that also features continuous logic. All mix together into the same mathematical framework as we have previously described, and all are essential to penetrate the microscopic world below the reach of human experience.
Is this just coincidence? Is it some joke at the expense of those who do not understand the overlap between high-end mathematics and science? Absolutely not. There is a key phrase in the paragraph above, in the “reach of human experience”. Both the subatomic and the hyperscale are exactly that. They are unprobeable by any direct human means of interaction or inspection. Yet still, we know that both exist and are very much of our world. What we cannot do, however, is consider them as being humanly tractable, simply because their manifestation lives beyond the realm of direct human experience. One is firmly below us, while the other firmly above.
With all options to assess human-level relatability removed, we are then only left with one option. All that remains is our appreciation and understanding of the abstract and the uncertain, as how can we possibly ascertain any ground truth without help to augment our insight. This is like Neanderthal man learning to mine an anthill for protein with a stick, or ancient warriors favoring iron weaponry over bronze. In the same way, the invention of the microscope opened up much of modern medicine and likewise 20th century breakthroughs in philosophy led to the birth of the modern-day computer. Sticks, microscopes, and digital computers are all just tools, as are the various formulations of mathematics. All have been, and will be applied, to get a handle on what we cannot appreciate directly. Where the timing of events is uncertain, then mathematical probability becomes the weapon of choice, just like the box and the line are the IT architect’s weapons of choice on our traditional battlegrounds today. Likewise, abstract vectors point the way to understand what can only be contemplated in imaginary terms. There is no real difference. Box, line, probability, vectors. Simply pick your tool and step forward. A job of work needs to be done.
Likewise, at higher levels of abstraction, it is possible to think of additional suites of mathematics brought to help understand how Ecosystems Architectures might behave over time. Here, tools like mathematical Game Theory [94] and Monte Carlo Analysis [95] come to mind, but the key thing to remember is that, just like graph theory and vector analysis, they amount to nothing more than tools to help understand that which we cannot face head-on. Whole other chapters could be written on how and how not to apply them at hyper-enterprise levels, but there really is no need. The techniques listed above provide a framework for representation and can thereby hopefully act as a foundational layer over which additional tooling might be applied.
3.16. Limitations and Inference
Because of their inherent flexibility, graphs can model most things, but not all. This becomes especially clear when context-based conditionality is involved.
To illustrate, let us contemplate the relationship between ice and water. When considered from the perspective of their chemical composition, both are identical and can therefore be represented via a graph triple, as shown in Figure 17.

From a physical perspective, however, ice and water are obviously very different, with one being a solid and the other a liquid. On that basis then, the graph shown in Figure 17 could be extended to model the physical deltas in place. But that is all it would do. In that, it would capture the essence of the two physical states. What it would not do, however, is capture the conditions under which hydrogen and oxygen combine to give either water or ice. In simple terms, it would not capture the rules covering the creation or destruction of any state being modeled. In that sense then, graphs are good at recording statements about an individually named situation, thing, or idea, but are not so good at capturing how or why such statements might be seen as real, relevant, or valid.
Notice the word “statement” in the previous paragraph. It is indeed apt, as all that graphs really allow you to do is capture some essence of an individual state, being, or relevance. Any essence associated with transition or conditionality around those things must, therefore, be overlayed using some other technique — as we did earlier by using vector coordinate systems to perhaps model dynamic behavior over time. You can, of course, document any such rules as attributes alongside the nodes or arcs in a graph, but to understand and use those rules, their location and purpose would need to be made clear. And, as those instructions would be external to any graph, or graphs, involved, they too must be considered as an overlayed system.
Attempts have, however, been made to create graph specification languages specifically aimed at bringing denotational semantics and contextual rule systems together. For example, the Semantic Web Rules Language (SWRL) [96] [97] was developed under the auspices of the World Wide Web Consortium (W3C®) Semantic Web initiative [98] [99] in 2004. That was founded on Description Logic (DL),[24] [100] but suffered take-up challenges due to its abstract nature and problems with formal decidability [101].
Having said all that, and although rules inclusion is not hard-baked into the idea of graphs (or graph-based languages) directly, some very useful types of logic lie very close to graph theory. Inductive reasoning, or inferencing [102], for instance, is a key feature of graph-based modeling, which gives “the derivation of new knowledge from existing knowledge and axioms” [103], like those represented in a graph format by way of nodes and edges.
To understand this better, think of the fictional character Sherlock Holmes [104]. He used deductive powers to set him apart as the preeminent detective of Victorian London, taking known facts from his cases and related them to his encyclopedic understanding of crime and criminal behavior. That allowed him to discover new relationships between his foe and what he already knew about crimes and criminals. In a nutshell, that is inference.
As a specific example, consider these two facts about the ancient philosopher Socrates:
-
All men are mortal
-
Socrates was a man
From these it is possible to infer that Socrates was mortal and, therefore, either that he is dead or will die some day. None of these things have been explicitly stated, but they are eminently sensible based on what limited information has been provided. In a similar vein, it is possible to infer that two services interface together if specifics of their data exchange are given, even if a definitive declaration of integration is not.
3.17. GenAI Patterns for Ecosystems Architecture
All of this is leading to an interesting tipping point. As the pace of change accelerates in areas like GenAI, it is becoming increasingly plausible to use synthetic help to augment and automate architectural practice. For instance, LLMs, such as those used in Retrieval Augmented Generation (RAGs) patterns [105] are becoming more proficient by the day and many persist, retrieve, and process their data using vector-store databases. An example is shown in Figure 18[25]. These use the exact same mathematical techniques labored over in this chapter. To begin with, that means that there is an immediate and direct affinity between LLMs and the architectural methodology laid out here. In other words, it is eminently feasible, and indeed sensible, to sit LLM chatbot facilities alongside any knowledge-graph(s) created from an ecosystem site survey. In that way, once architectural thinking has been encoded into graph form, it can be embedded into a vector system and used to directly train some of the world’s most advanced AI — ultimately meaning that practicing architects can interact with massive-scale, massively complex hyper-Enterprise Architectures in a very human, conversational way and well above the level of a single headful.
By adding features for homological analysis, such LLMs can also not only understand the architectural detail surveyed but also what is missing. This is game-changing, as when questions are asked of an architecture, its attached LLM(s) can ask questions back to help automatically fill in gaps and extend existing knowledge. This moves the chatbot exchange on from a one-way question and answering flow, to a genuine two-way conversation. That both increases awareness and scopes out any need for functional extension by the LLM itself.

Semantic rule systems can also be overlaid to help establish context when training or tuning LLMs. This is equivalent to providing an external domain-specific grammar and helps cast differing worldviews down onto whatever knowledge is in place. In analogous terms, this generates guide rails to tackle ice-water-like problems, such as the one described earlier.
Finally, conversation workflows can be applied. These help govern the sequencing of LLM interactions and also filter out dangerous or inappropriate exchanges. For instance, an architect might ask about the specifics of a flight control system, without being appropriately qualified or cleared to do so.
Of course, all reasoning, inferencing, and gap-filling must be architecturally sound. And that is where the human element comes back into the equation. Sure, an LLM-based GenAI might, for instance, be able to ingest previously written program code in order to document it automatically — thereby saving development time and cost — but ultimately and rather amusingly perhaps, this points to some whimsical wisdom once shared by the famous author Douglas Adams. In his book, “Dirk Gently’s Holistic Detective Agency” [106], Adams laid out a world in which everyone has become so busy that it is impossible to meaningly sift through the amount of television available. As a result, inventors have developed an intelligent Video Cassette Recorder (VCR) which can learn what programs viewers like and record them spontaneously. Even better, as these machines are intelligent, they soon work out that humans no longer have time to watch television at all. So, they decide to watch it instead, then erase the recording afterwards to save humans the bother.
3.18. So What?
This all leads to a big “so what?”
Hopefully, the primary challenge is clear, in that there is a very real opportunity to take AI too seriously and too far. That is why human judgement must always, always be kept in the loop. Beyond that, there is just more and more data coming at us and in more and more ways — from more processing, more sensors, and increasingly more data created about data itself. The list just goes on and its growth is beyond exponential. What is more, now, with the growing potential of the new AI-on-AI echo-chambers before us, yet more data will surely be added to the tsunami. As a result, we humans will simply run out of time and options to consume all the information that is important. So, how can we make sure we stay in the loop for the essential intel? How do we navigate in a world of overflowing headfuls? This is surely a problem for us all, but more so for us as architects.
This also obviously raises significant moral, ethical, and professional challenges, but also, ultimately, further highlights an inevitable paradox: we cannot progress without some form of external, almost certainly artificial help, while, at the same time, that help threatens to undermine the very tenets of professional practice and, dare we say it, excellence. For instance, what if we were to use GenAI to create both our architectural designs and the spewing code they demand to create the IT systems of the future? More profound still, what if we were to use AI to help drive out architectural standards? These possibilities have both now crossed the horizon and are increasingly within reach. Exciting, maybe. Dangerous, potentially. World-changing, almost certainly.
In short, we urgently need to find ways to monitor, learn from, account for, and limit the AIs we choose to help augment our world. But how we do that is, as yet, unclear. Control over individual AI instances will likely be untroublesome, and, sure, general rules, regulations, and laws can be laid down over time. But what about the network effect? What about muting the echoes from the world-wide AI echo chambers that will surely emerge. Imagine an AI equivalent of the World Wide Web, with billions of connections linking millions of small and apparently benign AIs — all feeding on the human thirst for more and more data, more stimulus… more help and, perhaps, more servitude and adoration? Make no mistake; this is the potential for swarm intelligence beyond ad nauseam. It is what the author Gregory Stock once referred to as “Metaman” [107] — the merging of humans and machines into a global super-organism. Or perhaps even the technical singularity first prophesied by John von Neumann himself, back in 1958, and in which all we will see is a “runaway reaction” of ever-increasing intelligence.
In truth, we are seeing this already at low levels, by way of the Augmented Intelligence already emergent through the World Wide Web of today. World-wide awareness of news and global affairs has risen for the better, for instance, as has open access to education. But so too has the speed at which radicalization and hate crime can spread. So, what we have the is a double-edged sword that will surely only cut deeper if we tip over from augmentation headlong into a reliance on that which is fully artificial.
And who will protect us against that? Who are the guardians? Where are the Jedi when we need them?
Some would argue that it is us, the IT architects who hold the AI genie’s bottle for now. Can we even stop the cork from popping? This is but one of the profound questions we must face as the age of Ecosystems Architecture dawns.
4. That is All Well and Good — Coping Mechanisms
The preceding chapter was all about technique; that is, it outlined a method already in widespread use, but perhaps not so well known amongst IT architects and software engineers. It also explained how that technique might be used to reason over multiple headfuls of information, so that they might be consumed in chunks of a single headful or less. In other words, how extremely large problem spaces might be cataloged and used successfully by your everyday (human) IT architect for work at the hyper-enterprise level.
Highlighting such a technique was not about prescription though, but more about highlighting that tools already exist to allow individuals to reach beyond the cognitive limits of the average human brain, and which do not necessarily rely on traditional reductionist problem-solving techniques.
With all that said, more pragmatically-inclined readers should hopefully have raised cries of “so what?”, and quite rightly so. Multi-headful party tricks amount to little more than tools available to the would-be Ecosystems Architect. They act as implements to assist, but provide little in the way of advice on how, where, when, and why they should be used. In other words, they provide little in the way of methodology.
Methods on their own add little value. Without some methodology to surround and support them, some rational for application and purpose as it were, along with instructions for how to go about whatever practice is necessary, methods amount to little more than instruction manuals for a car you cannot drive.
So, what might an Ecosystems Architecture methodology look and feel like?
4.1. Prior Art
As with all new endeavors, the wisest way to push forward is not to do anything rash. Instead, progress should not only, but must, be based by extension on provenly successful practice. So, with any approach targeted at hyper-enterprise IT architecture, the trick must be first to consult established practice in the hypo-enterprise space — netting out into an appreciation of the most widely accepted Enterprise Architecture methods; for example, the TOGAF® Standard and the Zachman Framework™ [108] [109]. This should further be supported by an appreciation of the underpinning principles coming from computer science, mathematics, and so on (as covered in the Prologue).
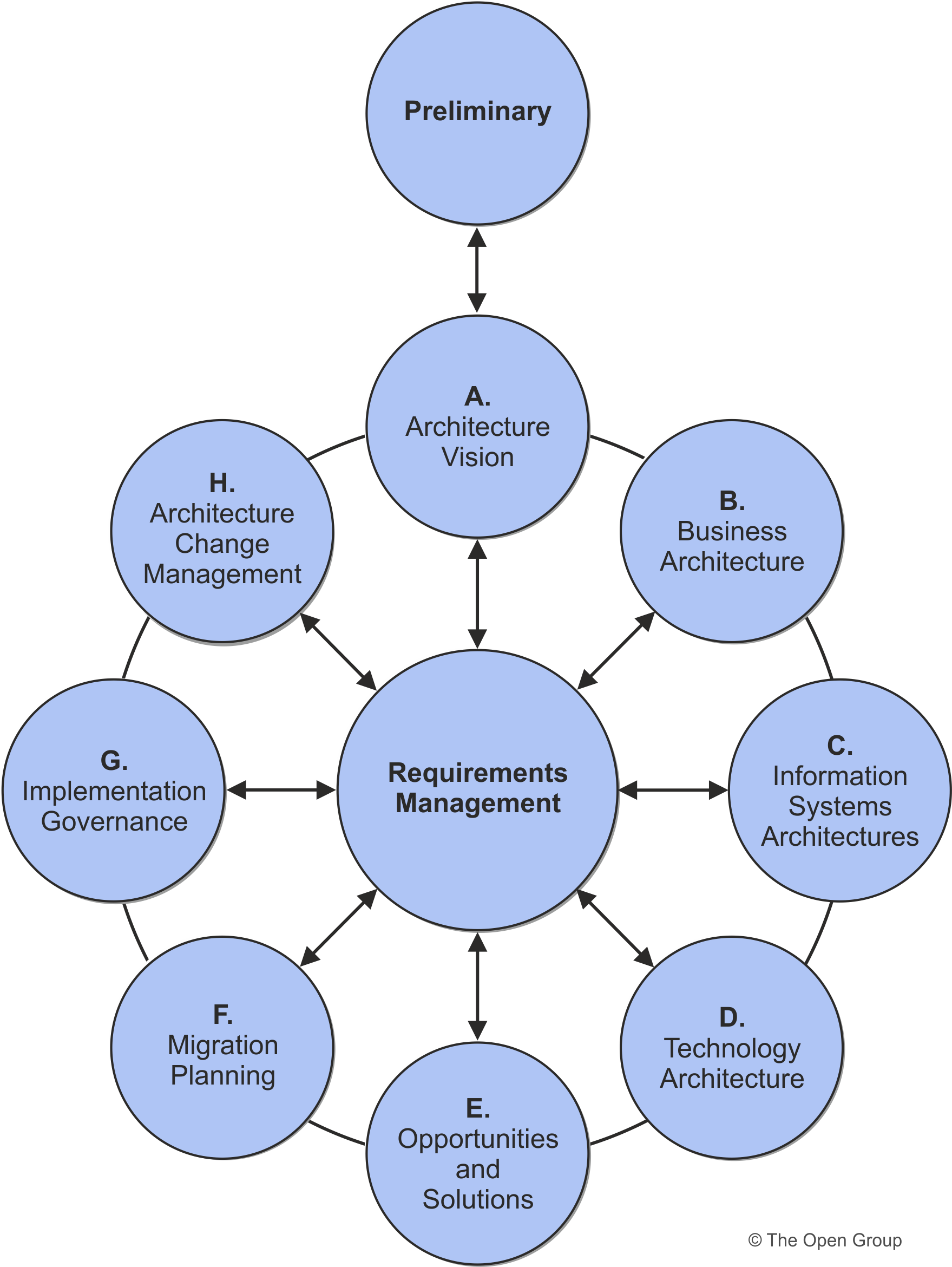
The TOGAF Standard was initially established in 1995. It prides itself on being an approach that satisfies business needs as the central concern of all design activities, but, at its core, it is fundamentally a collection of structured[26] and systems thinking practices [110] laid out to achieve systematic progress across the planning, design, build, and maintenance lifecycles of any collective group of enterprise IT systems. It does this by splitting Enterprise Architecture across four domains: Business, Application, Data, and Technical, and advising an approximate roster of work across an eight-phase method, known as the Architecture Development Method (ADM).
The Zachman Framework, shown in Figure 20,[27] by contrast, is slightly older, having first been published in 1987, and is somewhat more lenient in its doctrine. As such, it concentrates on describing the relationships between different Enterprise Architecture artifacts and perspectives and traditionally takes the form of a 36-cell matrix of ideas. Zachman, therefore, does not provide any guidelines for creating architectural artifacts, but instead prioritizes enterprise awareness by providing a holistic overview of perspectives and relationships across an enterprise. In that regard, Zachman is not necessarily a methodology per se, but rather a template for mapping out the fundamental structure of Enterprise Architecture.
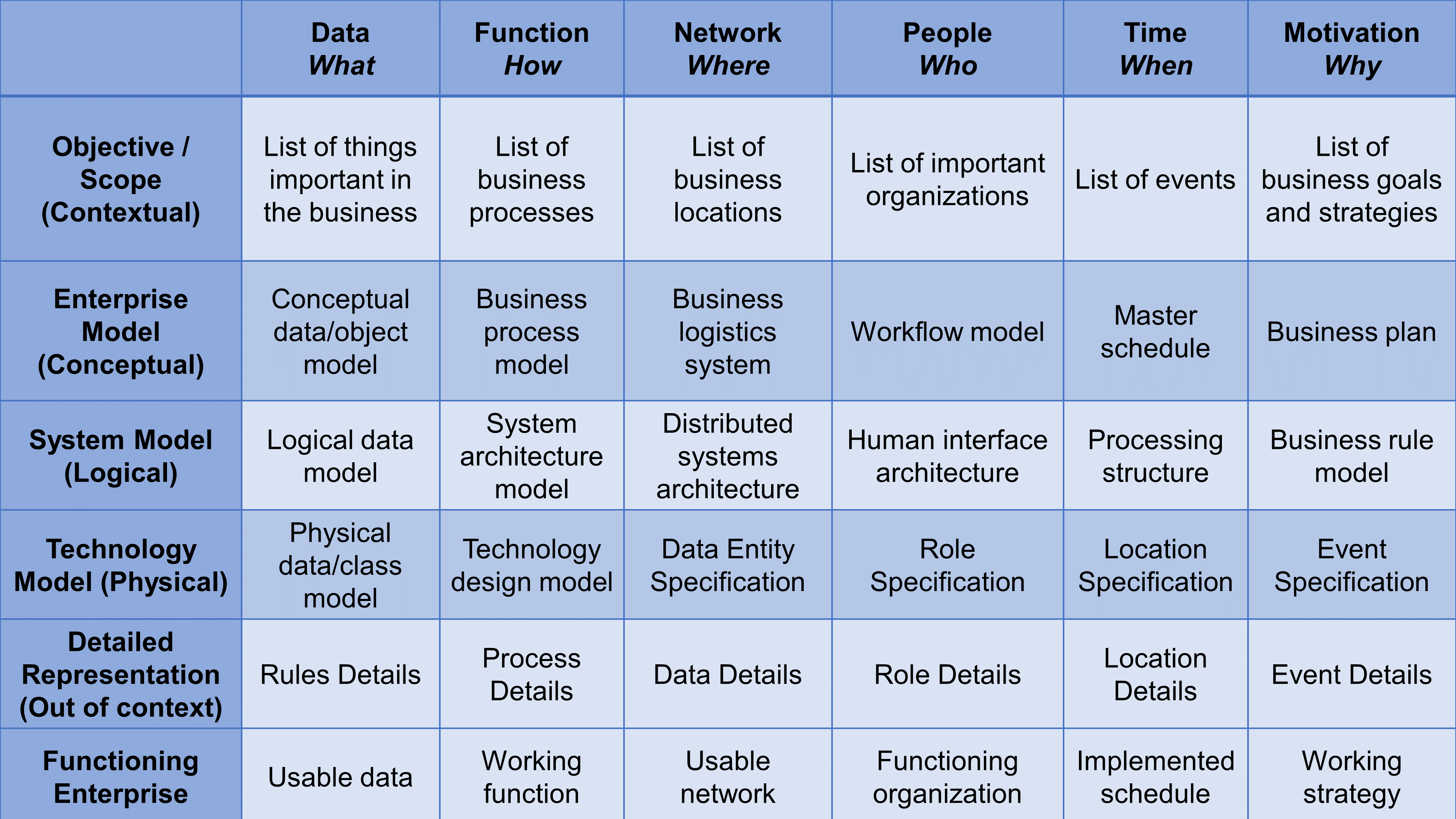
Both the TOGAF Standard and the Zachman Framework act as guidelines for applying a variety of architectural tools, many of which are graphical and/or graph-based. Both are also based on earlier architectural frameworks, usually focused on the systematic and the top-down structured development of singular IT systems and/or the various architectural artifacts involved. This lineage includes frameworks and toolsets worthy of mention, including the UML [111], Structured Systems Analysis & Design (SSADM) [112], Object-Oriented Design (OOD) [113], Jackson Systems Development (JSD) [114], and so on.
All, however, are merely examples of structured thinking approaches which help make sense of a complex world by looking at it in terms of wholes and relationships. All also try to emphasize sequenced pathways combining processes that incrementally contribute toward some form of key delivery event; be that completion of a system’s, or systems’, design, a go-live date, or whatever.
Boiled down to their essentials, all such frameworks can be summarized as a sequenced set of steps, or stages, aimed at:
-
Understanding a target problem space
-
Accounting for that space and describing a suitable (IT-based) solution aimed at alleviating related business challenges or releasing new business benefit
-
Exploring, explaining, realizing, and exploiting any resultant IT solution, once in place
4.2. Software Lifecyle Approaches
This leads to a broad-brush depiction of the IT overall systems lifecycle within any given enterprise, as shown in Figure 21.
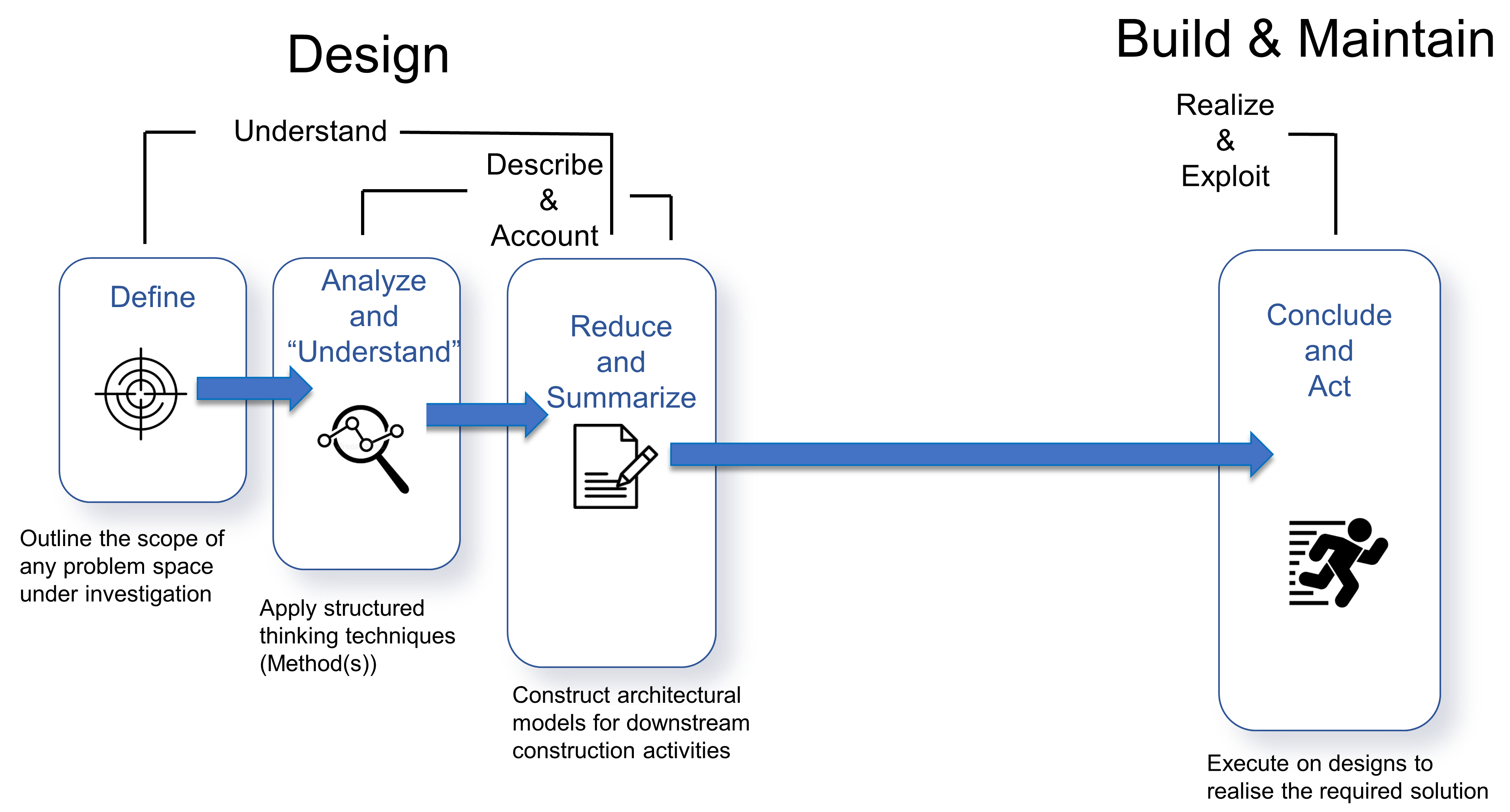
Here we see the same basic structure as listed at the end of the previous section. As such, the first two and a bit stages map onto the process of understanding a target problem space, the latter part of the second and all of the third stages focus on accounting and describing what needs to be done to implement any IT solution required — to make it “real”, as it were — while the fourth and final stage is all about actually making real and then ensuring that tangible benefit can result from delivery outputs.
Various systems and software lifecycle approaches have been developed over the years to help IT delivery across these stages, and range from the more traditional, as in Waterfall [115] or V-style [116], through to more contemporary modes of work, like Agile [117] delivery. All equip the IT architect with a structured set of coping mechanisms, and all are aimed at helping understand the viability of any work they are being asked to assist and/or undertake. And in so doing, they hopefully step up in support when asking questions like:
-
What am I, as an IT architect, uniquely responsible for?
-
How might I justify and explain my actions?
-
Am I doing things at the right time and in the right order?
-
What will not get done if I do not act professionally?
-
What are the value propositions associated with my work?
-
How am I contributing to the overall vitality of a particular business function or enterprise?
-
What are the consequences of not following some form of architectural method?
4.3. The VIE Framework
All of these ideas, tools, and approaches complement foundational systems thinking, like that found in the Viable Systems Model (VSM) [118] [119], which seeks to understand the organizational structure of any autonomous system capable of producing itself. VSM was developed over a period of 30 years and is based on observations across various different businesses and institutions. It therefore sees a viable system as any arrangement organized in such a way as to meet the demands of surviving in a changing environment. Viable systems must be adaptable and, to some extent at least, autonomous, in that their housing organizations should be able to maximize the freedom of their participants (individuals and internal systems), within all practical constraints of the requirements of them to fulfill their purpose.
As Paul Homan reminds us, this leads to an overarching set of characteristics common to all practically evolving sociotechnical systems at, or below, enterprise level:
-
VIABILITY
Participants (humans and systems) must be able to instantiate, exist, and co-exist within the bounds of all relevant local and global constraints/rule systems.In simple terms: Things should work and actually do what they are expected to do when working with, or alongside, other things.
-
INTEGRITY
Participants (humans and systems) must contribute meaningfully across local and global schemes and/or communities and in ways that are mutually beneficial to either the overriding majority or critical lead actors.They must not unintentionally damage the existing cohesion and content of the systems (as opposed to intentional damage that promotes adaption growth in light of environmental adaptation).
In simple terms: Do not fight unless absolutely necessary. Progressive harmony normally points the way forward.
-
EXTENSIBILITY
Functional and non-functional characteristics (at both individual and group levels) must be open to progressive change/enhancement over time, and not intentionally close off any options without commensurate benefit.In simple terms: Change is good, but generally only good change.
4.4. The Seeds of a Hyper-Enterprise New Method
The VIE framework nicely summarizes many decades of thinking focused on evolving professional practice, but it still leaves several gaps when the need to work at ecosystems level arises. For instance, most, if not all, established methods provide little in the way of thinking when it comes to the probabilistic nature of change or degree of functional and non-functional fit. Nor do they adequately address the challenges of ever-increasing abstraction levels, as networks scale out above enterprise level.
All of this consequently signals a need for methodology extension or modification at the very least. In doing that, you will recall a preference from the method outlined in the previous chapter, which presents the ideas of nodes and graphs as a ubiquitous way to model all the architectural detail required at both hypo and hyper-enterprise levels. You will also recall from Chapter 1 that the structure of the systems involved can be recursive; therefore, creating a need to work across multiple levels of abstraction.
For illustrative or convenience purposes, then, such abstraction levels can be labeled with unique names like Systems-Level, Enterprise-Level, Reef-Level, Planet-Level, and so on, but no generic unit for grouping or abstraction is provided. So, let us do that now by introducing the idea of cells.
4.5. Cells
A cell represents a generic collection of graph nodes, in the form of a complete and coherent graph or sub-graph at a specific level of abstraction, and which carries both viable architectural meaning and business and/or technical relevance.
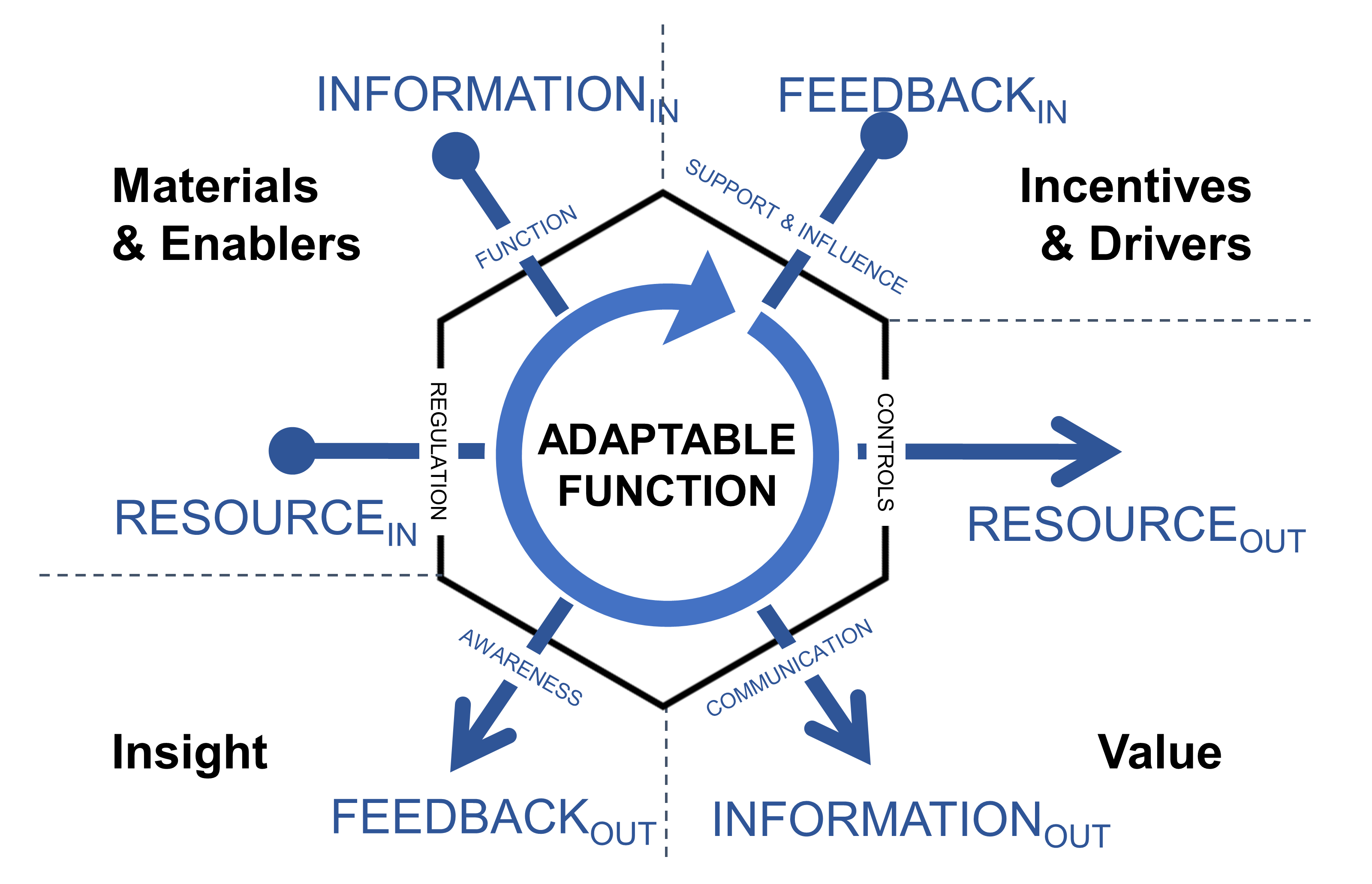
Because of their recursive nature, cells provide a scheme for describing the Matryoshka-doll-like nature of systems, enterprises, and ecosystems, and become interchangeable with the idea of nodes as abstraction levels rise. As such, it is perfectly legitimate for a cell to consist of a graph composed of nodes or a graph of cells containing other cells, containing cells or nodes, and so on. Likewise, this implies that architectural graphs can accept cells as individual nodes which mask lower levels of abstraction.
This means that Ecosystems Architecture remains graph-based, as abstraction (and scale) increases, but it allows the overlaying of classification schemes to hide lower levels of detail — not unlike the idea of information hiding found in object orientation [120] [121] [122]. This follows the principles of concern, segregation, and separation, common to many structured thinking approaches.
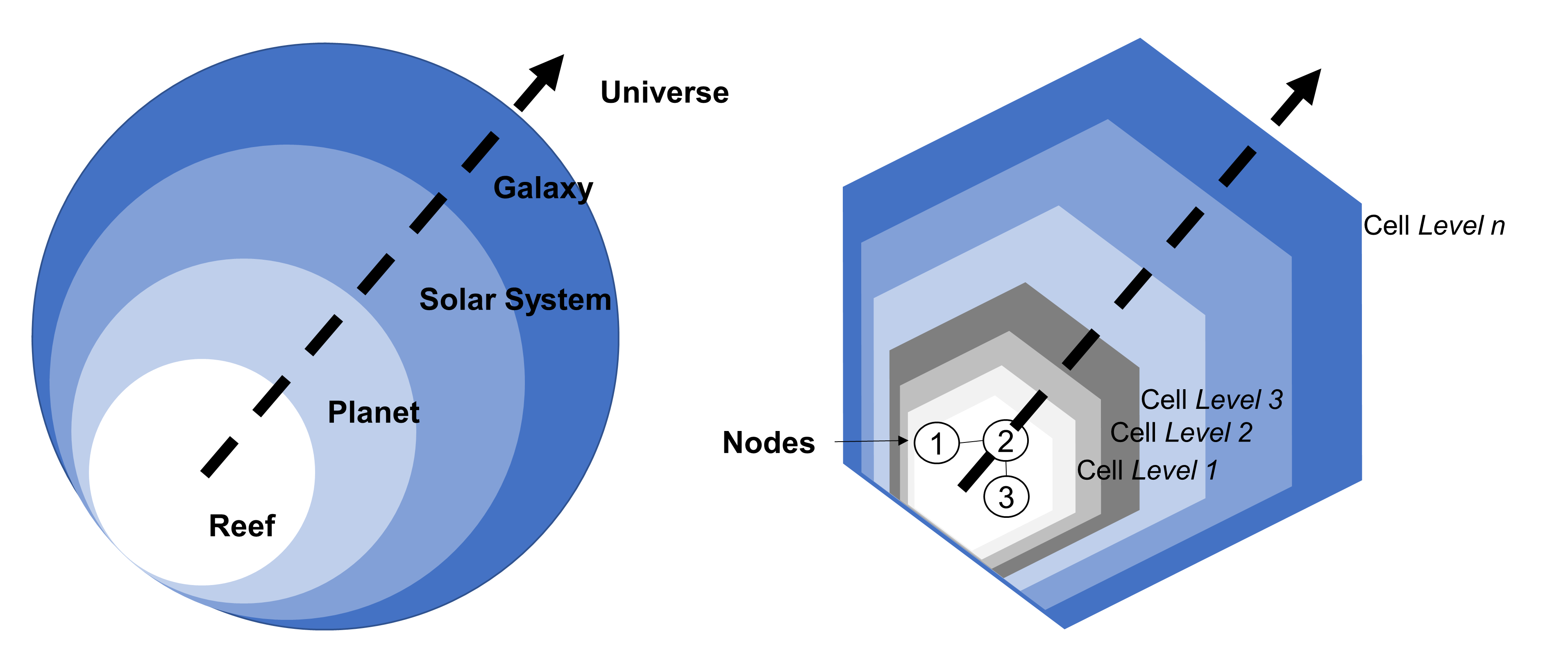
Cells also fit naturally with the ideas of viable systems thinking, in that they promote a pattern based on adaptable function. This sees cells as fitting into a self-organizing hierarchy of arrangement and also being dependent on a collection of both technical and business-focused inputs and outputs. These cover both information (technical) and resources (business) requiring transformation, and include the idea of self-regulation via specialized inputs classified as feedback.
All cells consequently act as both aggregating classifiers and participating nodal elements within an Ecosystems Architecture — regardless of their specific abstraction level and with any outermost cell acting as the embodiment of the containing ecosystem itself. Innermost, or lowest level cells, therefore, act as labels or indexes to the finest-grain graph content of relevance within an ecosystem, likely at, or below the systems-level. Lastly, everything outside an ecosystem’s outermost cell can be considered as its environment, even though that will itself have a recursive cell structure. This creates a continuum of interaction and co-evolution across adjacent domains/landscapes/universes, etc.
4.6. From VIE to VIPER
Expanding out into the ecosystems arena also implies extension to the list of essential characters for a viable system:
-
VIABILITY
Participants (humans and systems) must be able to instantiate, exist, and co-exist within the bounds of all relevant local and global constraints/rule systems.In simple terms: Things should work and actually do what they are expected to do when working with, or alongside, other things.
-
INTEGRITY
Participants (humans and systems) must contribute meaningfully across local and global schemes and/or communities and in ways that are mutually beneficial to either the overriding majority or critical lead actors. They must not unintentionally damage the existing cohesion and content of the systems (as opposed to intentional damage that promotes adaption growth in light of environmental adaptation).In simple terms: Do not fight unless absolutely necessary. Progressive harmony normally points the way forward.
-
PROBABILITY
Participants (humans and systems) may or may not exist and/or participate depending upon context. Participation may be beyond the control of both the individual and/or group.In simple terms: Certainty may well take a back seat at times. Prepare for that.
-
EXTENSIBILITY
Functional and non-functional characteristics (at both individual and group levels) must be open to progressive change/enhancement over time, and not intentionally close off any options without commensurate benefit.In simple terms: Change is good, but generally only good change.
-
RESPONSIVENESS
Participants (humans and systems) must be open to monitoring and participation in feedback loops.In simple terms: Help yourself and others at all times.
The inclusion of probability and responsiveness, therefore, captures the essential evolutionary self-organizing nature inherent to every ecosystem. They also highlight the need for any associated methods, methodologies, tools, and so on to be deeply rooted in mathematical techniques focused on chance, approximation, and connectivity. This does not mean, however, that mathematical formality needs to be forefront in any such approach, and certainly not to the point where advance mathematical wherewithal becomes a barrier to entry. No, it simply implies that some appreciation of probability is favorable and, at the very least, that probability should be considered as an essential (but not mandatory) property of any graph nodes and connections being worked with.
Probability and responsiveness also extend any overarching lifecycle framework in play, by highlighting the need for the unbiased gathering of detail before thinking about architectural patterns, abstraction, or hierarchy of structure. This pushes reductionist thinking toward the back end of the lifecycle and promotes Taoist-like neutrality and open-mindedness upfront.
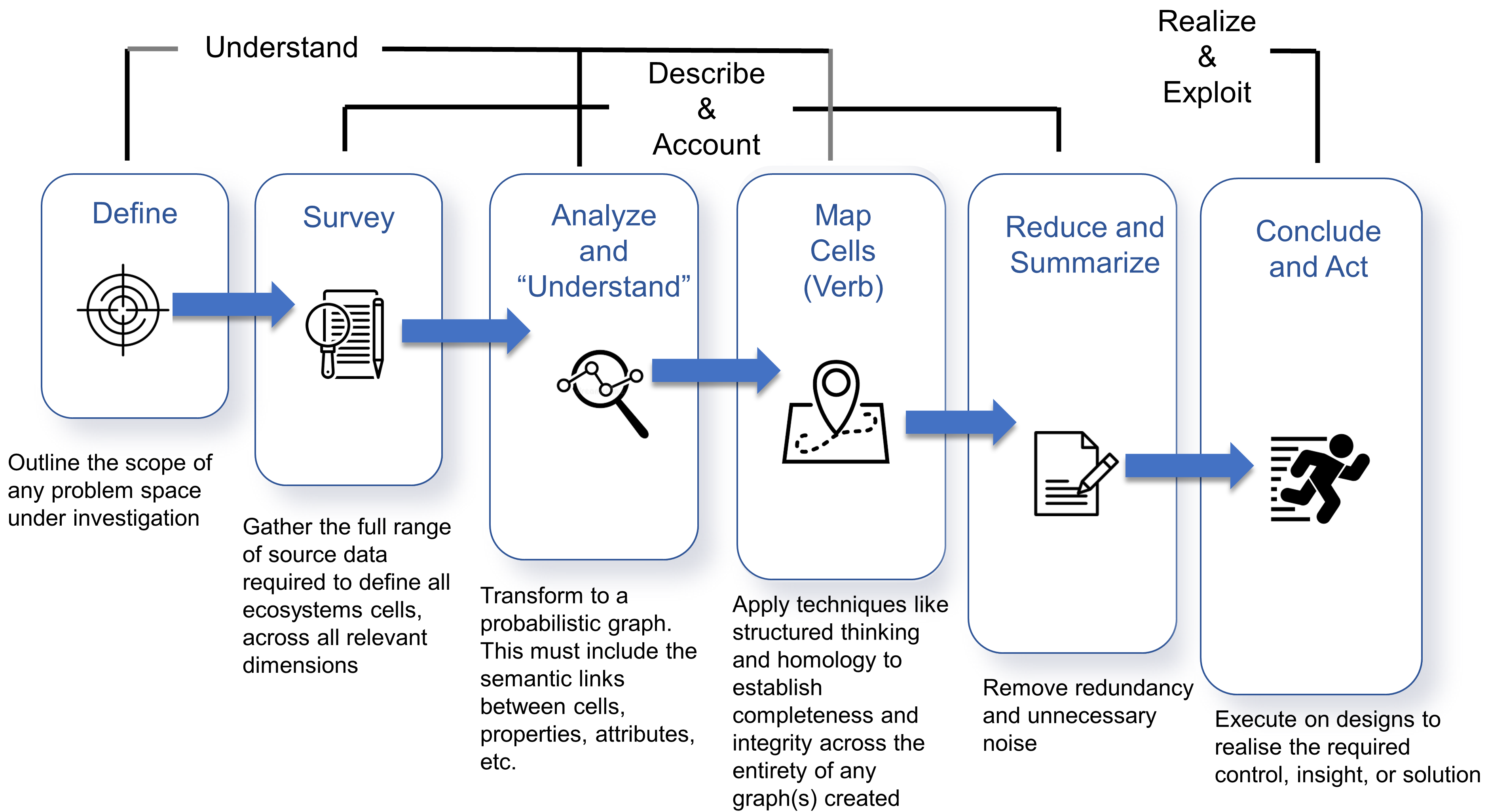
4.7. The 7+1 Keys of Viable Enterprise Ecosystems
The VIPER framework also leads to a more fine-grained list of essential characteristics, as outlined by the IBM® Academy of Technology [123]. This provides insights into areas of operational importance, such as orchestration, functional and non-functional restriction, interoperability, and governance.
4.7.1. Principles of Vitality and Evolution
-
Function and Mutuality
Participants (humans and systems) must be able to do something that contributes to all, or a meaningful part, of the ecosystem. -
Communication and Orchestration
Participants (humans and systems) must be able to communicate and co-ordinate resources with other elements, either within their immediate context (the ecosystem) or outside of it (the environment) — must possess amplification and attenuation capabilities to suite. -
Controls
It must be possible to control the ways in which participants (humans and systems) group (structure), communicate, and consume resources in a common manner. -
Awareness
An ecosystem must support instrumentation and observation at both participant (humans and systems) and group levels. This includes implicit awareness of any environment, given that this can be considered as a both a unit and group participant in the ecosystem itself. -
Regulation
An ecosystem must support constraints at the group level that guide it as a whole to set policy and direction. -
Adaptability (including Tolerance)
Participants (humans and systems) and groups must be able to adapt to variance within the ecosystem and its environment. -
Support and Influence
Participating elements must be able to use resources supplied from other participating elements, groups, and/or the environment itself.
4.7.2. Principles of Self
-
Scaling
Structures must allow self-similarity (recursion/fractal) at all scales and abstractions.
4.8. End Thoughts
Hopefully, these and the other ideas presented will provide a starting point for structured thinking aimed at the hyper-enterprise level. They are by no means complete or definitive, but they have at least now been debated and (partially) field tested over a number of years and across a number of cross-industry use cases. What is badly needed now is review from the wider IT architecture community and the coming together of consensus over applicability, value, and overall direction.
5. Existing Ecosystems Thinking and Practice
“Let our advance worrying become advance thinking and planning.” — Winston Churchill
Now that the basics of how we might begin to address the challenge of hyper-enterprise systems have been covered, it is time to summarize what has already been done to establish practice in this approximate area.
5.1. Social Machines
Here, we essentially find two categories of capability, with the first being somewhat more academic than the other. This is the study of social machines [124], which sets out to understand how group-level IT systems involving human communication (like those found on social media) apply the technology inherent to their immediate surroundings. This is akin to the swarm-type intelligence seen in a colony of ants or a murmuration of starlings, only this time supercharged by the digital compute capabilities brought by every participant involved.
This is distributed computing at its most potent, yet, unbelievably, no explicit hierarchy of control or centrality of management is present or needed. Instead, the crowd simply decides en masse as consensus emerges, and this is what gives social machines their power.
Although this might sound like science fiction, it most definitely is not. If you were to look at how governments were overthrown during the Arab Spring,[28] for instance, you will see an example of social machines at their best. This is shown well in an amazing YouTube™ video [125] by André Panisson, which brings the power of social machines starkly to life. In it, you will see an animated graph of Twitter conversations bubbling over as dissatisfaction against the then Egyptian government reaches its peak. What is striking in this video is that, although clusters of interest are clear around a few nodes (representing key social influencers or revolution ringleaders in this case) in the graph, none show up as any point of obvious focus. In other words, no single point of instigation stands out, which is what frustrated the authorities in their attempts to quell the uprising, and ultimately led to the government’s downfall in 2011.

This type of evolving consensus amongst social groups is now well understood and should not be underestimated as we become interested in Ecosystems Architecture. That is because all IT systems exist in one way or another to serve human need. Technology can never exist purely to serve technology, as it were, although that might not always be clear from surface inspection. No, at the root of all that drives every single IT system will be found some human want, whether that be to lessen a workload, generate profit, pass on news, or whatever. IT systems exist to serve us and not the other way around. For that reason, if a shift in human need occurs, it will sooner or later change the demand for IT, the technical requirements in hand and the nature of the solutions we as IT architects are expected to build and maintain. Furthermore, given that we are inherently a social species, the likelihood is that that change in demand will come from shifting consensus, rather than lightning strikes of individual ingenuity, creativity, or compulsion. As with the events of the Arab Spring, the group may well decide, rather than any individual, authority, or organization. Obviously, there are, and will be, exceptions to that rule, but as general guidance, history speaks to its related wisdom.
This is the unfolding world in which we live and work. It is essentially the backdrop to the whole of human existence, and that includes the domains of commerce, politics, religion, and so on. For the first time in human history then, with the Arab Spring, we had amassed sufficiently advanced statistical techniques, professional competence, and adequate computing support to help analyze the social mechanics in play when its various rebellions broke out. In truth, however, academics and practice leaders had been working on the ideas behind those mechanics for some time. What they saw then, was an unusually speedy alignment of opinion played out across the Web’s relatively new social platforms. For the first time, they allowed the connected consciousness of whole populi to be recorded and analyzed in detail. That essentially allowed us to bottle the genie and convince it to give up its spells. In that way we now mostly know how the environmental conditions and human need worked together to disrupt and drive out change. No wonder then that world-class academic institutes, like Media Lab at MIT [127] are becoming increasingly interested. There, they are driving research to “develop data science methods — based primarily on natural language processing, network science, and machine learning — to map and analyze communication and interaction in human networks, and to design tools and field experiments to investigate new forms of social connectivity”.
Likewise, several universities in the UK and US are also deeply interested in the idea of social machines. For instance, the SOCIAM program [128] [129] [130] [131] [132] is spread across Southampton, Edinburgh, and Oxford universities and has “set out to explore how existing and emerging social media platforms are changing the relationship between people and computers”.
All of this is great for the theory behind Ecosystems Architecture, but unfortunately, it is not all good news. For all that the ideas behind social machines can help us understand the wherewithal behind hyper-enterprise change, they add little or nothing when it come to the practicalities of actual IT delivery.
This is where our second example of existing thinking/practice comes in.
5.2. Gaia-X
Having come this far in the discussion, some things should be clear about hyper-enterprise architectures. Sure, both they and their surrounding environments change over time; sure, they can be large and complex; and sure, they can demand some pretty abstract thinking to understand them properly. But how might that help when it comes to making the IT involved actually work?
For instance, it is one thing to understand the need to update an interface between two nodes in an ecosystem, as, for whatever reason, one or both of those nodes undergoes change. It is also fine to understand that similar nodes might lie within reach — meaning that either or both ends of the integrated connection might be technically replaced to achieve the update required. But how might you actually go about the work necessary to make that happen in a reasonable way. That is, in the face of all relevant constraints and considerations? For instance, it might feel all right to think of replacing a legacy system with a more contemporary equivalent, like, say, a containerized service deployed on the latest whizzy cloud. But what if that system talks using EBCDIC-based[29] EDI[30] flat files, whereas its replacement via some dialect of ASCII-based[31] JSON squirted out through some esoteric REST API?[32] Is that feasible? Probably, but at what cost and with how much delay? These and a myriad of other practical questions must be answered before any practical progress can be made.
As IT architects, we de-risk situations involving challenges like this by talking in terms of standards, patterns, methodologies, methods, and so on. These stoically set out to communicate guidelines in terms of best practice and/or accepted norms, and in ways that can be easily understood and adopted. In essence, they try to establish safe and common ground based on what we know to be tried, tested, and true. This is often strengthened through the support of independent standards bodies consisting of recognized experts and the like. Similarly, it is not unheard of for bodies to spring up outside the professional standards community, with specific aims to level the playing field, as and when major shifts in technology or usage patterns occur. With that in mind, the Gaia-X [133] association was established in the summer of 2019 to overcome the interoperability challenges associated with real-world hyper-enterprise IT systems. Gaia-X brings together industry, politics, government, research, academic, technical, and scientific leaders from Europe and beyond to collaborate on the next generation of trusted data infrastructures. It therefore represents:
“…a European initiative that aims to create a secure and trustworthy data infrastructure for Europe, which will facilitate the exchange and sharing of data between companies and individuals. It was set up as a joint effort by the European Union and the German and French governments, and with the goal of creating a secure and sovereign data infrastructure for Europe that is based on European values and principles. The initiative was launched in 2019, and since then, it has grown to include more than 300 members from different sectors, including industry, academia, and government.”
The base values that Gaia-X seeks to promote include:
“…transparency, openness, and interoperability, while also ensuring that data remains under the control of the owner.”
Gaia-X’s goal is therefore to “establish an ecosystem, whereby data is shared and made available in a trustworthy environment” and to give “control back to the users by retaining sovereignty over their data.” This will, in Gaia-X’s words “not be a cloud. It is a federated system linking many cloud service providers and users together in a transparent environment that will drive the European data economy of tomorrow.” It therefore aims to help establish decentralized IT architectures based on shared European values and by specifically focusing on the advantages associated with data-sharing infrastructure and the idea of data as a common shareable resource [135] [136].
The federated data infrastructure and data-sharing frameworks developed by Gaia-X have already been applied to several vertical ecosystems [137] across sectors including automotive, energy, and agriculture [138], and although in its current form it focuses on Europe’s data economy, its reference architecture [139] and principles are broadly location-independent. It can, therefore, be applied to cater for global participation by using compatible federated protocols and identities.
That said, Gaia-X’s original ambitions have not yet been fulfilled [140] [141], and progress appears to have reached a trough of disillusionment [142]. Still, Gaia-X has helped move the needle on Ecosystems Architecture in Europe by establishing consensus within several, economic, and political communities. Its ongoing struggles no doubt point to a fundamental characteristic of ecosystems, however, in that they generally do not respond well to direction from any single source — no matter how official or justified that direction or its origin. To say that another way, “just causes generally do not flourish in a sea of opinions”. As discussed already, consensus, and therefore commitment en mass, generally emerges from the masses, rather than through direct intervention. Consequently, the odds of any mandated interoperability program succeeding in an ecosystem context may be average at best. But then, that is always the challenge with any start-up standards initiative. Even so, several prima facie examples can be found which suggest that leading by example can be a good thing. And it turns out that the inclusion of new technology in the mix can be of decided benefit.
Take, for instance, the case of the QWERTY keyboard. Although its layout is ubiquitous today, it is by no means the most efficient design for human typing. In fact, in 1873 an engineer named Christopher Scholes designed its layout specifically to slow typists down, given that the typewriting machines of the day tended to jam when typists typed too fast. But the Remington Sewing Machine Company mass-produced a typewriter using the QWERTY system, which meant that lots of typists began to learn its layout, which meant that other typewriter companies began to offer QWERTY versions of their own machines, which meant that still more typists began to learn it, and so on and so on. Through this process of positive reinforcement, the QWERTY keyboard layout is now used by millions. Early market entry and positive feedback have therefore catapulted it to be the standard for all its flaws and weaknesses.
To reinforce this point, consider the Betamax™ versus VHS™ competition in the videotape market of the 1970s and 80s. Even in 1979, it was clear that the VHS format was well on its way to cornering the market, despite the fact that many experts had originally rated it to be technologically inferior to Betamax. How could this have happened? Simply because the VHS vendors were lucky enough to gain a slightly bigger market share in the beginning, which gave them an enormous advantage in spite of the technological differences. Video stores hated having to stock everything in two formats and consumers hated the idea of being stuck with obsolete VCRs, so everyone had a big incentive to go along with the market leader. That pushed up the VHS market lead even more and the small initial difference grew rapidly. This is again a case of increasing returns and a fine example of how the propensity to use certain types of technology can lock in users.
5.3. Semantic Web-Enabled Software Engineering
Moving on, it turns out that the idea of formally describing large, complex, self-organizing IT systems in an effort to engineer within them, is not a new thing.
Back in the mid-1990s, just around the time when the World Wide Web was about to hit mass adoption, a group of engineers intent on helping its progress spotted a problem. That charge was led by the computer scientist Ramanathan Guha [143] who argued, given that the Web was being run on computers, would it not make sense for those computers to understand the content they were serving as well? In other words, would it not be great if the Web was made machine-readable? That would help increase levels of automation, not least in the increasingly important area of advanced search.
At the time, this was a revelation. The world’s search engines were only just starting to stand up and progress in Natural Language Processing research was slow. To enhance the Web’s architecture and enable computers to do more useful work just made sense. Out of that came the W3C [144] Semantic Web [98] [99], or “Web of Data” initiative. Its central idea was to add metadata to Web pages and other online resources and in a standardized format, so that machines could understand what the pages were about and how that related to other information elsewhere on the Web. This was primarily to make it easier for computers to “reason” about the content, and to link related information together. The Semantic Web, therefore, uses a variety of technologies and standards, including the Resource Description Framework (RDF) [145], the Web Ontology Language (OWL) [146], and the SPARQL [147] query language. These allow developers to create rich, structured data sets that can be easily shared and queried by other applications.
As part of the Semantic Web work, the W3C started a Best Practices and Deployment Working Group [148] in 2004, with the aim to provide hands-on support for developers of Semantic Web applications. That then spun out a subsidiary task force [149] specifically asked to investigate potential synergies between the Semantic Web and domains more traditionally associated with software engineering. In practice, that amounted to a fait accompli, as its members already knew that technologies like RDF could be used to catalog and describe software-focused assets, like program code, data stores, and so on. Likewise, they knew that the same technologies could be repurposed to catalog and describe IT architectures at both systems and enterprise levels.
To do this was relatively simple. RDF and OWL are derivatives of the eXtensible Markup Language (XML®) [150], and so are built from the ground up to document collections of structured assets or ideas. That makes them graph-based by definition, meaning that XML is based on the idea of denoted nodes linked by denoted connections. Therefore, XML is eminently suitable for describing all forms of connected systems, be they data-based, software-based, architecture-based, or even chicken-n-waffle-based!
The highfalutin way to say this is to state that semantic web technologies are ontologically focused, but hopefully you get the point. That is, that the semantic web offers an equivalent framework to that of graphs encoded using eigenvectors. Overall, it is a different encoding method, but with the same approximate end effect. Not only that, but it is possible to translate between the two with little or no loss in translation. In that way, architects can seamlessly move from the precision offered by the mathematics of vector algebra, across into the practicalities of a strongly grammar-based language, as found in XML derivatives. What is more, as those derivatives are machine-readable and potentially machine-understandable, it is a relatively trivial task to automatically generate program code from the XML specifications in hand. In that way, using semantic-web technologies provides intermediate translation mechanisms that allow systems, systems-of-systems, and ecosystems-based architectures to be accurately specified then transformed into working solutions, give or take a few minor practicalities along the way.
So, with regard to our earlier example of an interface between two ecosystems nodes needing an update, so long as that change is specified in enough detail, and equivalent detail is also available to describe both the participating nodes and their connection, in an increasing world of advanced AI it should not be insurmountable to quickly generate replacement code upon request.
5.4. GenAI and Intermediate Modeling Languages
As an interesting aside, it is worth noting that RDF and OWL are both just text-based modeling languages and, given that many popular GenAI models are also text-based, they can be instructed to provide output using the syntax of either language. For example, a GenAI instance can be prompted to:
“Output all the following text using the sytnax of the Web Ontology Language OWL. Confirm you understand”.
Then prompted with the following text:
“Interface A interacts with Interface B using REST exchanges and a packet size of 128KB”.
This will instruct the GenAI to produce the output shown in OWL Format Code.
# Define the classes for Interface A and Interface B :A rdf:type owl:Class. :B rdf:type owl:Class. # Define the interaction relationship :A interactsWith :B. # Define the type of interaction (REST) :AInteraction rdf:type owl:Class. :BInteraction rdf:type owl:Class. :A interactsWith :AInteraction. :B interactsWith :BInteraction. # Define the packet size using an annotation property :packetSize rdf:type owl:AnnotationProperty. :AInteraction :packetSize "128KB"^^xsd:string. # Define the type of exchange (REST) :restExchange rdf:type owl:Class. :AInteraction rdf:type :restExchange. :BInteraction rdf:type :restExchange.
Other text-based modeling languages can also be used to control output syntax. For example, Mermaid JavaScript™ [151] and Plant UML [152] both support text-based modeling languages that can be used to generate architectural schematics. It is therefore not only reasonable, but eminently practical to perhaps think of generating such schematics automatically using GenAI.
For instance, by first providing the prompt:
“Output all the following requests as PlantUML code. Confirm if you understand”.
Then instructing:
“Create a class diagram to show the essential characteristics of a facade software pattern”.
Which will output the code shown in PlantUML Code.
Plantuml
@startuml FacadePattern
class Client {
+ operation()
}
class SubsystemA {
+ methodA1()
+ methodA2()
}
class SubsystemB {
+ methodB1()
+ methodB2()
}
class SubsystemC {
+ methodC1()
+ methodC2()
}
class Facade {
- subsystemA: SubsystemA
- subsystemB: SubsystemB
- subsystemC: SubsystemC
+ operation1()
+ operation2()
+ operation3()
}
Client --> Facade
Facade --> SubsystemA
Facade --> SubsystemB
Facade --> SubsystemC
@enduml
This code can then be fed into a PlantUML editor like PlantText [153] to produce the schematic shown in Figure 26.
5.5. Quantum Semantics and Applied Quantum Computing
Now, one final curveball.
It is all well and good that we have managed to find a route from an abstract understanding of hyper-enterprise systems down to ways to automate their construction and maintenance, but some very basic properties of these systems stand a very real chance of getting in the way. All along, for instance, we have stressed the idea that hyper-Enterprise Architectures can be large and complex. Humongous might even be a better word. So, those familiar with the tools and techniques we have been advocating might also understand that they are fine when dealing with small problems, but humongous is a whole other thing. XML for example, in theory provides an infinitely extensible framework for description and/or specification. Likewise, there is no theoretical upper limit to the size of systems that it can describe. However, and it is a big however, XML is a particularly verbose language that can take a lot of computing to process effectively. That, therefore, creates a practical upper limit to what can and cannot be handled. Furthermore, it must be asked why all the trouble of describing a quantum-like approach to specification, then advocating an intermediate step of translating via an XML derivative. Surely that is like mixing oil with water, right? Why use a chisel to do the job of a screwdriver? Might it not be possible to use the same paradigm throughout, perhaps sidestepping any practical limitations brought by the potential scale of the problem being addressed?
Well, the answer is potentially “yes”, but it is still very much early days.
Given that all the ways forward advocated in this document have been strongly based on graphs and graph theory, might it not be possible to represent and process such graphs directly using a quantum approach to computing? That, in essence, means modeling a target problem space and its nascent architecture directly using quantum computers and the qubits that they contain.
The short answer is potentially “yes”,[33] but before understanding why, the workings of quantum computers need to be briefly summarized.
You will no doubt know that the fundamental unit of information storage in a traditional digital computer is the bit. As such, each bit behaves like a tiny switch and is only ever referenced when it is purely on or purely off. There is no middle ground. Classical computer bits are therefore tiny binary switches that measure microns across, but nonetheless likely comprise many thousands of atoms. In practical engineering terms then, even the smallest physical bit could, if you so wished, be inspected under a microscope. Quantum computers work differently, however. Instead of using classical bits, they use quantum bits or qubits, which are made from single atoms or photons of light. That not only means that these devices are tiny, and so cannot be inspected directly at the human scale, but they work in some counter-intuitive ways, dictated by the laws of quantum mechanics.
At this point, we need to mix in some basic chemistry. Hopefully, you will remember that atoms comprise of a tiny nucleus, surrounded by a spinning cloud of electrons, and that in certain circumstances the number of electrons present can leave an atom with an electronic charge. Such charged atoms are what we call ions and, in the most common model of quantum computing, they provide the stuff from which qubits are made.
Now, it turns out that the electrons in an ion are particularly hard to pin down, but there are ways of persuading them to help align their parent atom in very useful ways. This is rather like taking an eight-ball from a pool table and carefully rotating it so that the number eight faces up or down, front or back and so forth. Cleverly, this kind of precise rotation and the ion’s resulting orientation correlates with the idea of on or off, 0 or 1 in a classical bit. And because icons can be rotated in three dimensions, that means that, by default, qubits can hold six values, rather than just the two in a standard classical bit.
This is a game-changer in itself, but it is not quite the full story. Because electrons are devilishly hard to pin down, it is never a simple matter of just asking an ion to align itself as you would like. Instead, ions like to misbehave, as quantum mechanics itself mandates. That means that some of the time a qubit will switch properly and sometimes it will not, therefore making reading and writing qubits a bit of a gamble.
In a more formal way, that means that qubits are probabilistic and require multiple attempts to persuade them to behave as we would like. This nets out into the fact that you cannot just read the value of a qubit once and expect the answer to be correct. Instead, you have to read it multiple times and average out the result. This might seem like a clumsy way to go about things, but actually, we know how to do it well now and modern quantum computers are getting better all the time in the ways that they get qubits to perform.
All that aside, there are a couple of other features of qubits, and quantum computers in general, that are particularly exciting when applied to Ecosystems Architecture.
The first is that, although standard engineering practice and a good deal of theoretical physics suggest that qubits must align precisely up or down, front or back, right or left, that does not necessarily mean that that always has to be the case. For instance, using deliberate contortion tricks, likely involving error correction techniques, we could possibly ask a qubit to orientate five degrees right of vertical up. Indeed, we could ask a qubit to align in an infinite number of orientations if we were granted enough engineering precision.
In information engineering terms, this is truly significant. From that vantage point, a classical bit can be said to hold a vocabulary of two settings or symbols, as in the values 0 and 1. Likewise, a classical qubit can be seen to hold a vocabulary size of six. In that way, it could be said that a classical bit uses the binary base system, whereas classical qubits work according to the higher order number systems, like the senary (heximal) [154] base system. In a similar way then, if we were able to coerce a qubit to align in any one of 256 ways, it would work according to base-256.
Now, what is interesting here is that when thinking in terms of base-256, you do not necessarily have to imagine a number line consisting of 256 discrete number values. Instead, you can associate each entry in that base with a different system of symbols. So, instead of considering base-256 as being a numeric vocabulary, it is just as valid to consider it as representing a character-based system, like, say the ASCII character set [155]. But why stop there? We could practically think of qubits working according to base-1000, base-10000 or whatever, in which case each symbol could act as an index, rather than a character or a number. What that therefore means is that we could encode an effective referencing system at the atomic level, and if that system had enough capacity, we could store an index to describe any of the nodes present in an ecosystem and/or its associate architecture.
That covers node documentation, but what about the connections between nodes? How might we represent an abstract graph model across a number of qubits?
Again, it turns out that quantum mechanics comes to the rescue with a property known as quantum entanglement.
Quantum entanglement is therefore a phenomenon where two or more atomic particles become connected in a way that their properties are correlated, even when they are physically separated from each other. This correlation exists regardless of the distance between the particles and can be instantaneously observed when one of the entangled particles is measured, affecting the other particle’s properties simultaneously.
To say that differently, we can, in theory, plug qubits together much like we do nodes in an abstract graph, and in that way potentially model hyper-Enterprise Architectures across meshes of qubits.
Needless to say, in making this statement, just as with qubit orientation, quantum entanglement need not just be fully engaged or not, and the same way as described above, you can theoretically encode a use full referencing system via degrees of entanglement.
All of this amounts to the emerging field now known as Quantum Semantics [156] [157], and although the practical details of how it might be implemented still need to be worked through, the theory involved is remarkably sound. It also indirectly speaks to one particular advantage brought by quantum computing over classical variants.
When a problem space is large and all its constituent elements must be considered, there are generally only two ways to go about that. The first requires that each element is inspected in turn, sequentially and via a continual loop. This, of course, carries the drawback of perhaps being time-consuming to the point of obstruction. Parallel inspection, therefore, provides an alternative and is where all elements are inspected at once. But this approach also has its limitations, in that parallel execution demands a lot of computing power, and often specific types of machine, to do the work necessary.
This class of challenge covers what computer scientists refer to as being np[34] complete problems, in that associated tasks can be accomplished in a measurable, but not necessarily practical, period. np hard problems, therefore, represent a class of np complete problems that are known to take a lot of time to compute and will therefore likely drain a lot of computing resource. On that basis then, addressing the needs of hyper-enterprise systems could highly likely be called out as an np hard challenge, which is not exactly ideal. Not ideal, that is, for classical forms of computing, but not so much for quantum variants, as it happens.
Through a property of quantum mechanics known as quantum collapse, it is possible to undertake the equivalent of high-scale parallel processing using a fraction of the computing resources needed when classical computers are used. In this technique, it is possible to represent all possible outcomes of a problem within a quantum computer, then take a guess as to what the most appropriate answer might be. Rather than returning with the specifics of that choice, the machine will tell if your guess was right or wrong.
All told, therefore, the promise of quantum computing and quantum information feels ideally placed to help assist to a world of Ecosystems Architecture. The next few years will see both fields mature to the point of realistic adoption and real-world application. Whereas now, we are at a stage little more advanced than when classical computers needed programming with assembler, progress on everything quantum is moving apace.
5.6. Feet Back on the Ground
This is, of course, all well and good. But there are many more areas and ideas to explore, and not all can be covered in a single book like this. Nevertheless, we can signpost that this type of thinking indeed holds potential for several well established, ongoing IT challenges.
The following list highlights just two interesting, and hopefully obvious, examples:
-
Organizations Looking to Decentralize Internally and Externally
This may be in response to market opportunities, internal or external pressures, or other reasons. Regardless, circumstances may require ecosystems to be created and/or adapted both within and around the enterprise — thereby entailing that business functions or whole organizations become essential to several ecosystems and at a number of levels. This presents a multi-faceted challenge requiring that individual ecosystems work well and without significant cross-boundary (interoperability) interference.
Traditionally, Enterprise Architecture primarily looked at internal interoperability — perhaps wrongly. Multi-level decentralization changes that focus. -
Organizations Looking to Recentralize
Rather perversely, organizations that have allowed or even encouraged a proliferation of internal silos also need to consider bringing an ecosystems perspective into play. This will help ensure that they do not exclusively become inward-facing, thereby restricting opportunities for collaboration, expansion, and so on.
6. Summary and Final Comments
“If you think of [the Web] in terms of the Gold Rush, then you’d be pretty depressed right now because the last nugget of gold would be gone. But the good thing is, with innovation, there isn’t a last nugget.” — Jeff Bezos
“If in doubt, make it stout and use the things you know about.” — anon
As IT architects, we like structure. Structure not only in what we do and say, but in the how and why and when of our practice. We are also naturally wary of risk and are taught early to neutralize it in the face of opportunity, innovation, or change. When we therefore come across a problem we have not encountered before, we recoil and ask for the opinions of our peers. If and when that hits ground truth, we hopefully find tenets laid down through best practice and community agreement. These are the foundational standards upon which the entire IT architecture profession is based. From there, lest some disaster befall us, we elaborate to instill the value of sober governance and consensus agreement. In essence, we do things by the book. That is what professionals do.
But what to do when such standards and governance processes cannot provide coverall protection? What to do when a world view simply refuses to conform with all that has gone before? These and other questions face us in the brave new world of hyper-enterprise systems.
During the preparation of this book, a group of experts met regularly within The Open Group Architecture Forum to discuss progress and any issues that arose. The result was not only some extremely useful professional debate, but also something of an adjustment process. Some of the participants were rightly nervous. While they welcomed the new ideas being presented, they were keen to ground them in what they knew and trusted. What followed was often a case of going back to first principles and then rebuilding in a fresh light.
For instance, we often referred to the fact that IT architects sometimes start the process of architectural thinking by referencing written descriptions of a desired solution offered up by business counterparts deep in an enterprise’s bowels. As a result, they pick over that text and pull out just the nouns and verbs that capture the solution’s essence. These become names or descriptors of the various elements in the first of a series of architectural schematics, all of which incrementally define the design and delivery process of the target IT system in hand.
In that, things are very systematic. Nouns become actors or events, and verbs become functions or actions. In that way, the prescription of any chosen architectural method can be doled out and progress towards some agreed end game can begin.
But what if you do not have the nouns or verbs to describe what is going on or required? Worse still, what if you have the required wording, but the implications of its use are just too much for you to handle? What if those words simply cause all the tools within your reach to short out or overflow under the stress? Likewise, what if the wording you have is correct today, but perhaps not tomorrow? These are the things that worried the team looking to supervise the birth of Ecosystems Architecture.
In the end, however, we can report that the child was delivered safely.
During that process, a few things became clear, not least of which was the absolute need not to jettison existing practice. Ecosystems Architecture, therefore, builds upon Enterprise Architecture, as does Enterprise Architecture atop systems architecture. All that changes is an added openness to the way typing is applied, and therefore how vocabularies of architectural terms and symbols might be laid down and adopted, and a few additional ways of working on top.
In a nutshell, that boils down to the dynamic extension and scaling of established architectural practice.
What normally happens is that when architects pick over the needs of their clients, they are happy to accept certain verbs, nouns, and numbers, but not others. If these relate to a change of state or a need to communicate at reasonable size and speed, for instance, then all is fine, as they translate into familiar tractable concepts etched into established architectural thinking. They are safe and are practically deliverable, in other words. But if they talk of deliciousness or succulence perhaps — to quote our examples from Chapter 3 — then noses might well be turned up.
Nevertheless, in an ecosystems’ world, these and other non-standard concepts might well need representing and may well change over time. This is simply because accompanying narratives could be too vague and/or too large and complex to record using conventional means. So, the starting point must be to first capture as much value as possible, then work from there. That also requires means that are qualifiable, quantifiable, and amenable to storage, representation, and translation at very high scales and complexities.
This might seem like a contradiction, but it is not. In fact, we have tackled all of these challenges and more besides, with outstanding success in the past. Qualifiable and quantifiable simply means that any information open to architectural thinking must be uniquely identifiable and in ways that we can classify, count, measure, query, and perhaps reason over. This should come as no surprise, given that we already do this all the time in IT systems involving large and complex data. We call that indexing or mapping, in that we merely replace any characteristics that make a thing or idea stand out with a unique string — normally called a key or hash — and which acts as a proxy shortcut for that thing or idea. What is more, given that indexes are normally much smaller than the characteristics they reference, that allows for catalogs of descriptive content at much larger scales and complexities than we humans can naturally handle.
This is where vector-based mathematics, borrowed from the world of information retrieval, comes in, as it can ground any denotational semantics associated with the things we need to model and implement, and in ways that allow measurable comparison relative to any broader problem space. It can also encode the various attributes that hang off these assets, as they are assigned unique keys. In that way, both keys and attributes can be compressed using the same mathematical approach and arranged to map out the details of any relevant ecosystem.
That nicely brings us to a simple summary of the change advocated in this book:
Ecosystems Architecture advances practice by focusing on higher-order systems archetypes and abstractions. It thereby augments assets and attribute representation using mathematical (vector-based) indexing and compression as a starting point.
This essentially recasts a remarkably familiar problem. As the Web’s early pioneers worked to bring its nascent search engines to life, they too had to ask how to embrace an ecosystem of sorts. Back then, interest focused on the expanding vastness of the Web as it blanketed its underlying Internet, and, looking back, that hurdle was jumped with ease. This time, however, the challenge is broader and more difficult.
In many ways, the World Wide Web was, and still is, a uniform phenomenon, with its various languages, protocols, and formats being governed by a surprisingly small group of standards. As such, its placement within the digital ether is fixed relative to the internet and its presentation is therefore relatively easy to predict and understand. With the planet’s web of interlinked IT systems, however, we are not as lucky. As new IT paradigms, specifications, and standards spring up, we are left with a wake of change in which generations of technology are left to fight it out for survival. That can leave IT professionals in a perpetual realm of firefighting. So, how can we rotate out from this inward-facing uphill struggle to practically grasp the advantages offered by the wider digital context?
The ultimate answer must lie in a combination of updated tooling and augmented practice. Today, for instance, chatbots like ChatGPT [158] make it relatively easy to extract nouns and verbs from human-readable text as justifiable entities, actions, attributes, and so on. Likewise, it is now trivial to create that text directly from human speech and perhaps even via some process involving chatbot interviews. This is the burgeoning world of openly available AI that we appear willing to accept, so it is by no means a stretch of the imagination to think of a world where requirements and supporting narratives are harvested automatically at scale and with ease. That is what the “A” for artificial in AI gives us, but there is also another “A” involved. Once any corpus of detail has been amassed and perhaps automatically structured into a graph format, it will still need inspection by suitably qualified IT architects to ensure that its contents can be moulded into downstream deployable assets. This may require direct interaction with that corpus, its index (by way of its vector-based graph) or may itself be assisted by the use of artificial intelligence so that implementation details are hidden. Regardless, the bringing together of human skill with advanced tooling gives us augmented intelligence, the other “A” in AI. What is more, if this work extends to more than just a handful of practitioners, then we soon arrive at the lower limit of what might be described as a social machine — as explained in Chapter 5.
Tried and tested architectural practice can kick in through filtering, inferencing, or other techniques applied to the corpus, so that manageable viewpoints can be extracted and worked on at the headful level. If, for example, returned results match or approximate something like a collection of components, then the chances are they can be modeled in a standard way, by segmenting into headfuls and using a component model maybe. In that way, progress can be made. Same with a sequence diagram or any other established form of architectural model, documentation, or method. Similarly, just because we might not have standard nomenclature to express the things that need to be said, so long as we can justify the representation required, there should be nothing to stop architects from creating new ad hoc types and/or associated symbology. In that way, it is perfectly acceptable, if somewhat extreme, to think of architectural diagrams containing shapes not unlike either chickens or waffles, just so long as their parent types can be justified and applied with repeated formality.
Furthermore, basic graph theory provides a safety net, in that if new nomenclature cannot be found or agreed, the default of circles for nodes and straight lines for connections between nodes can be used, and associated types overlaid via annotation. Graphs can therefore model most things, as they have an elegant and flexible syntax. As a result, we can think of graphs encoded using vector-based mathematics as a kind of back-end context-free-grammar,[35] allowing for universal jotter pads of ideas to be formalized by way of ontological corpora and without restrictive limits on scale, complexity, symbology, or semantics. From there, we can springboard in and out of whatever codification we like to get over the architectural points needing communication, construction, testing, and so on. Once architects are happy with the filter and typing overlays they have applied, they can use them to codify relevant semantics using more specialized language models — including XML derivatives like RDF and OWL. From there, it is a relatively short hop to the automatic generation of code, documentation, testing, and eventual deployment of useful technical assets, as advocated by ideas of MDA [159] [160] [161] [162] [163] [164] and especially ontology-driven software engineering [165].
Appendix A: Referenced Documents
The following documents are referenced in this document.
(Please note that the links below are good at the time of writing but cannot be guaranteed for the future.)
Muehlenkamp, R. How Many People Died in All the Wars in the 20th Century?, January 2017; refer to: www.quora.com/How-many-people-died-in-all-the-wars-in-the-20th-century |
|
Richie, H., L. Rodés-Guirao, L., Mathieu, E., and Gerber, M., World Population Growth, April 2017; refer to: ourworldindata.org/world-population-growth |
|
Interview with Maurice Perks; refer to: archivesit.org.uk/interviews/maurice-perks/ |
|
Cognitive Complexity, Wikipedia: The Free Encyclopedia; refer to: en.wikipedia.org/wiki/Cognitive_complexity |
|
Klein, M., What Boolean Logic Is & How It’s Used In Programming, March 2022; refer to: www.codecademy.com/resources/blog/what-is-boolean-logic/ |
|
Feynman, R. P., Simulating Physics with Computers, 1982, International Journal Of Theoretical Physics, Vol. 21(6/7), pp.467-488 |
|
Reductionism, Wikipedia: The Free Encyclopedia; refer to: en.wikipedia.org/wiki/Reductionism |
|
Booch, G, Discussion on the History of Software Engineering Methodologies [Interview], June 2023; refer to: www.youtube.com/watch?v=QUz10Z1AfLc |
|
Grady Booch, Bio; refer to: research.ibm.com/people/grady-booch |
|
Object-Oriented Design, Wikipedia: The Free Encyclopedia; refer to: en.wikipedia.org/wiki/Object-_oriented_design |
|
Object-Oriented Programming, Wikipedia: The Free Encyclopedia; refer to: en.wikipedia.org/wiki/Object-oriented_programming |
|
Paul Homan, Bio; refer to: www.opengroup.org/member/paul-homan |
|
Interview with Fishman, N, via email re The Three Golden Ages of Architectural Thinking, June 30, 2023 |
|
Formal Methods, Wikipedia: The Free Encyclopedia; refer to: en.wikipedia.org/wiki/Formal_methods |
|
The TOGAF Standard, 10th Edition, a standard of The Open Group (C220), April 2022, published by The Open Group; refer to: www.opengroup.org/library/c220 |
|
Rouse, M., Generative AI, June 2023; refer to: www.techopedia.com/definition/34633/generative-ai |
|
Large Language Model, Wikipedia: The Free Encyclopedia; refer to: https://en.wikipedia.org/wiki/Large_language_model |
|
Neural Network, Wikipedia: The Free Encyclopedia; refer to: en.wikipedia.org/wiki/Neural_network |
|
Tetlow, P. and Homan, P., Engineering Ecosystems Architectures, published by IBM Academy of Technology, 2019 |
|
Furda, A. and Hedges, J., The Emerging Role of the Ecosystems Architect, March 2018; refer to: www.researchgate.net/publication/324942808_The_Emerging_Role_of_the_Ecosystems_Architect |
|
Marshall, A., The New Age of Ecosystems, July 2014; refer to: www.ibm.com/thought-leadership/institute-business-value/report/ecosystem-partnering |
|
Davidson, S., Harmer, M., and Marshall, A., The New Age of Ecosystems: Refining Partnering in an Ecosystem Environment, July 2014; refer to: www.ibm.com/downloads/cas/ZQRNRRMY |
|
Enterprise, Definition; refer to: www.dictionary.com/browse/enterprise |
|
Ecosystems Architecture Update, IBM Academy of Technology, 2021 |
|
Service Economy, Wikipedia: The Free Encyclopedia; refer to: en.wikipedia.org/wiki/Service_economy |
|
Service-Dominant Logic, Wikipedia: The Free Encyclopedia; refer to: en.wikipedia.org/wiki/Service-dominant_logic |
|
Lusch, R. F. and Vargo S. L., Service-Dominant Logic: Premises, Perspectives, Possibilities, published by Cambridge University Press, June 2014 |
|
The Life Centricity Playbook: Proven Strategies for Growth and Relevance; refer to: www.accenture.com/gb-en/insights/song/life-centricity-playbook |
|
The Human Paradox: From Customer Centricity to Life Centricity; refer to: www.accenture.com/content/dam/accenture/final/a-com-migration/r3-3/pdf/Accenture-Human-Paradox.pdf |
|
The New Age of Ecosystems, IBM Institute for Business Value, 2015; refer to: www.ibm.com/thought-leadership/institute-business-value/en-us/report/ecosystem-partnering |
|
Rigby, D., Digital-Physical Mashups, September 2014; refer to: hbr.org/2014/09/digital-physical-mashups |
|
Global Digital Disruption Executive Study, IBM Institute of Business Value, 2013 |
|
Complete Guide to GDPR Compliance; refer to: gdpr.eu/ |
|
The European Data Act, February 2022; refer to: www.eu-data-act.com/ |
|
Data Act — Questions and Answers; refer to: ec.europa.eu/commission/presscorner/detail/en/qanda_22_1114 |
|
17 Goals to Transform Our World, United Nations Sustainable Development Goals; refer to: www.un.org/sustainabledevelopment/ |
|
Mcleod, S., Maslow’s Hierarchy of Needs; refer to: www.simplypsychology.org/maslow.html |
|
Sociotechnical System, Wikipedia: The Free Encyclopedia; refer to: en.wikipedia.org/wiki/Sociotechnical_system |
|
Tetlow, P., The Web’s Awake: An Introduction to the Field of Web Science and the Concept of Web Life, pp32-33, published by Wiley-IEEE Press, May 2007 |
|
Tetlow, P., Chapter “Some Key Questions Still Remain” in The Web’s Awake: An Introduction to the Field of Web Science and the Concept of Web Life, pp.119-120, published by Wiley-IEEE Press, May 2007 |
|
Blackmore, S., The Meme Machine, published by Oxford University Press, January 1999 |
|
Solé, R., and Goodwin, B., Signs of Life, How Complexity Pervades Biology, published by Basic Books, January 2002 |
|
Tetlow, P., Chapter “Why on the Web?” in The Web’s Awake: An Introduction to the Field of Web Science and the Concept of Web Life, pp.149-151, published by Wiley-IEEE Press, May 2007 |
|
Waldrop, M. M., Complexity: The Emerging Science at the Edge of Order and Chaos, published by Pocket Books, September 1992 |
|
Choose an Organizational Structure for Digital Business, published by Gartner, 2018 |
|
The Future of Your Business Ecosystem in the Age of Digital Business: A Gartner Trend Insight Report, September 2018; refer to: ibm.northernlight.com/document.php?docid=IA20180913040000110&datasource=IBM&context=html_export |
|
Wannemacher, P., Amazon Flirts With Banks and Their Customers: Here’s What You Should Do, April 2018, published by Forrester; refer to: www.forrester.com/blogs/amazon-flirts-with-banks-and-their-customers-heres-what-you-should-do/ |
|
Banks Must Adapt to a Platform-Dominated World, April 2018, published by Forrester; refer to: www.forrester.com/report/Amazon+Invades+Banking+Heres+What+You+Should+Do/-/E-RES143116# (Accessed June 18, 2019. Note: This reference is no longer available online.) |
|
Evolve Now to Personalization 2.0: Individualization, May 2017; refer to: ibm.northernlight.com/document.php?docid=IA20171206990000040&datasource=IBM&context=html_export |
|
The Customer Experience Ecosystem Redefined, November 2016; refer to: ibm.northernlight.com/document.php?docid=IA20080302360068160&datasource=IBM&context=html_export |
|
Understanding Consumer Preferences Can Help Capture Value in the Individual Market, September 2017; refer to: ibm.northernlight.com/document.php?docid=IA20180228090000070&datasource=IBM&context=html_export |
|
Stuart Kauffman, Wikipedia: The Free Encyclopedia; refer to: en.wikipedia.org/wiki/Stuart_Kauffman |
|
Kauffman, S., Chapter “Darwinian Preadaptation” in Reinventing the Sacred: A New View of Science, Reason, and Religion, pp.131-143, published by Basic Books, February 2010 |
|
SOCIAM: The Theory and Practice of Social Machines; refer to: sociam.org/about |
|
Kelly, K., Out of Control: The New Biology of Machines, Social Systems, and the Economic World, published by Basic Books, April 1995 |
|
Easley, D. and Kleinberg, J., Networks, Crowds, and Markets: Reasoning about a Highly Connected World, published by Cambridge University Press, September 2010 |
|
Yachi, S. and Loreau, M., Biodiversity and Ecosystem Productivity in a Fluctuating Environment: The Insurance Hypothesis, published in Proceedings of the National Academy of Sciences of the United States of America, pp.1463-1468, February 1999 |
|
Doak, D. F., Bigger, D., Harding, E. K., Marvier, M. A., O’Malley, R. E., and Thomas, D., The Statistical Inevitability of Stability-Diversity Relationships in Community Ecology, published in American Naturalist, pp.264-276, March 1998 |
|
Promoting Deeper Learning and Understanding in Human Networks, Laboratory for Social Machines, MIT Media Lab; refer to: www.media.mit.edu/groups/social-machines/overview/ |
|
Shadbolt, N., O’Hara, K., De Roure, D., and Hall, W., The Theory and Practice of Social Machines, published by Springer, February 2019 |
|
Kauffman, S., Reinventing the Sacred: A New View of Science, Reason, and Religion, pp.131-143, published by Basic Books, February 2010 |
|
Kauffman, S., The Origins of Order: Self-Organization and Selection in Evolution, published by Oxford University Press, June 1993 |
|
West, G., Scale: The Universal Laws of Life and Death in Organisms, Cities, and Companies, published by W&N, May 2018 |
|
Autocatalysis, Wikipedia: The Free Encyclopedia; refer to: en.wikipedia.org/wiki/Autocatalysis |
|
Autocatalytic Set, Wikipedia: The Free Encyclopedia; refer to: https://en.wikipedia.org/wiki/Autocatalytic_set |
|
Tetlow, P., Chapter “Autocatalitic Sets” in The Web’s Awake: An Introduction to the Field of Web Science and the Concept of Web Life, pp.130-131, published by Wiley-IEEE Press, May 2007 |
|
Franklin’s Lost Expedition, Wikipedia: The Free Encyclopedia; refer to: ://en.wikipedia.org/wiki/Franklin%27s_lost_expedition |
|
Double Seam, Wikipedia: The Free Encyclopedia; refer to: en.wikipedia.org/wiki/Double_seam |
|
Intersection (Set Theory), Wikipedia: The Free Encyclopedia; refer to: https://en.wikipedia.org/wiki/Intersection_(set_theory) |
|
Set Theory, Wikiepedia: The Free Encyclopedia; refer to: en.wikipedia.org/wiki/Set_theory |
|
Graph Theory, Wikipedia: The Free Encyclopedia; refer to: en.wikipedia.org/wiki/Graph_theory |
|
Haque, S. J., Graph Theory 101, August 2021; refer to: sitn.hms.harvard.edu/flash/2021/graph-theory-101/ |
|
Najera, J. Graph Theory — History & Overview, November 2018; refer to: towardsdatascience.com/graph-theory-history-overview-f89a3efc0478 |
|
Seven Bridges of Königsberg, Wikipedia: The Free Encyclopedia; refer to: en.wikipedia.org/wiki/Seven_Bridges_of_K%C3%B6nigsberg |
|
Vatsal, Node2Vec Explained, January 2022; refer to: towardsdatascience.com/node2vec-explained-db86a319e9ab |
|
Cartesian Coordinate System: Revision History, Wikipedia: The Free Encyclopedia; refer to: en.wikipedia.org/w/index.php?title=Cartesian_coordinate_system&action=history |
|
Vector Space, Wikipedia: The Free Encyclopedia; refer to: en.wikipedia.org/wiki/Vector_space |
|
Cosine Similarity, Wikipedia: The Free Encyclopedia; refer to: en.wikipedia.org/wiki/Cosine_similarity |
|
Vector Notation, Wikipedia: The Free Encyclopedia; refer to: en.wikipedia.org/wiki/Vector_notation |
|
Google; refer to: www.google.com/ |
|
Sato, K. and Chikanaga, T., Find Anything Blazingly Fast with Google’s Vector Search Technology, December 2021; refer to: cloud.google.com/blog/topics/developers-practitioners/find-anything-blazingly-fast-googles-vector-search-technology |
|
van Rijsbergen, K., The Geometry of Information Retrieval, published by Cambridge: Cambridge University Press, 2004 |
|
Widdows, D., Geometry and Meaning, published by CSLI Publications, 2004 |
|
The Hitchhiker’s Guide to the Galaxy; refer to: en.wikipedia.org/wiki/The_Hitchhiker%27s_Guide_to_the_Galaxy |
|
Homology (Mathematics), Wikipedia: The Free Encyclopedia; refer to: https://en.wikipedia.org/wiki/Homology_(mathematics) |
|
ChatGPT, OpenAI; refer to: openai.com/chatgpt |
|
Hallucination (Artificial Intelligence), Wikipedia: The Free Encyclopedia; refer to: en.wikipedia.org/wiki/Hallucination_(artificial_intelligence) |
|
Parisi, A., Zhao, Y., and Fiedel N., TALM: Tool Augmented Language Models, May 2022; refer to: browse.arxiv.org/pdf/2205.12255.pdf |
|
Schick, T., Dwivedi-Yu, J., Dessì, R., Raileanu, R., Lomeli, M., Zettlemoyer, L., Cancedda, N., and Scialom, T., Toolformer: Language Models Can Teach Themselves to Use Tools, February 2023; refer to: browse.arxiv.org/pdf/2302.04761.pdf |
|
Peng, B., Galley, M., P. He, P., Cheng, H., Xie, Y., Hu, Y., Huang, Q., Liden, L., Yu, Z., Chen, W., and Gao J., Check Your Facts and Try Again: Improving Large Language Models with External Knowledge and Automated Feedback, March 2023; refer to: browse.arxiv.org/pdf/2302.12813.pdf |
|
Get More Leads with LinkedIn, Copilot; refer to: www.copilotai.com/ |
|
Empowering Every Developer with Plugins for Microsoft 365 Copilot, May 2023; refer to: www.microsoft.com/en-us/microsoft-365/blog/2023/05/23/empowering-every-developer-with-plugins-for-microsoft-365-copilot/ |
|
Cai, T., Wang, X., Ma, T., Chen, X., and Zhou, D., Large Language Models as Tool Makers, May 2023; refer to: browse.arxiv.org/pdf/2305.17126.pdf |
|
Game Theory, Wikipedia: The Free Encyclopedia; refer to: en.wikipedia.org/wiki/Game_theory |
|
Monte Carlo Method, Wikipedia: The Free Encyclopedia; refer to: en.wikipedia.org/wiki/Monte_Carlo_method |
|
SWRL: A Semantic Web Rule Language Combining OWL and RuleML, May 2004; refer to: www.w3.org/submissions/SWRL/ |
|
Semantic Web Rule Language, Wikipedia: The Free Encyclopedia; refer to: /en.wikipedia.org/wiki/Semantic_Web_Rule_Language |
|
Semantic Web, March 2023; refer to: www.w3.org/standards/semanticweb/ |
|
Semantic Web Standards, August 2019; refer to: www.w3.org/2001/sw/wiki/Main_Page |
|
Description Logic, Wikipedia: The Free Encyclopedia; refer to: en.wikipedia.org/wiki/Description_logic |
|
Parsia, B., Sirin, E., Cuenca, B., Ruckhaus, E., and Hewlett, D., Cautiously Approaching SWRL; refer to: cs.uwaterloo.ca/~gweddell/cs848/SWRL_Parsia_et_al.pdf |
|
Inference, Wikipedia: The Free Encyclopedia; refer to: en.wikipedia.org/wiki/Inference |
|
What is Inference?; refer to: www.ontotext.com/knowledgehub/fundamentals/what-is-inference/ |
|
Sherlock Holmes; refer to: en.wikipedia.org/wiki/Sherlock_Holmes |
|
Retrieval Augmented Generation (RAG); refer to: docs.aws.amazon.com/sagemaker/latest/dg/jumpstart-foundation-models-customize-rag.html |
|
Dirk Gently’s Holistic Detective Agency; refer to: https://en.wikipedia.org/wiki/Dirk_Gently%27s_Holistic_Detective_Agency |
|
Stock, G., Metaman: The Merging of Humans and Machines into a Global Superorganism, published by Simon & Schuster, September 1993 |
|
Zachman International and The FEAC Institute; refer to: zachman-feac.com/ |
|
Chapter “ADM and the Zachman Framework” in the TOGAF Standard, Version 8.1.1 Online, Part IV: Resource Base, published by The Open Group; refer to: pubs.opengroup.org/architecture/togaf8-doc/arch/chap39.html |
|
Systems Thinking, Wikipedia: The Free Encyclopedia; refer to: en.wikipedia.org/wiki/Systems_thinking |
|
Booch, G, Rumbaugh, J, and Jacobson, I., The Unified Modeling Language User Guide, published by Addison Wesley, May 2005; refer to: patologia.com.mx/informatica/uug.pdf |
|
SSADM — An Introduction; refer to: web.archive.org/web/20130219234253/http://www.dcs.bbk.ac.uk/~steve/1/sld001.htm |
|
Object-Oriented Analysis and Design; refer to: www.informit.com/articles/article.aspx?p=360440&seqNum=8 |
|
Jackson System Development, Wikipedia: The Free Encyclopedia; refer to: en.wikipedia.org/wiki/Jackson_system_development |
|
Petersen, K., Wohlin, C., and Baca, D., The Waterfall Model in Large-Scale Development, published by Springer, 2009; refer to: www.diva-portal.org/smash/get/diva2:835760/FULLTEXT01.pdf |
|
Kumar, D., SDLC V-Model; refer to: www.geeksforgeeks.org/software-engineering-sdlc-v-model/ |
|
What is Agile?, published by Agile Alliance; refer to: www.agilealliance.org/agile101/ |
|
Viable System Model, Wikipedia: The Free Encyclopedia; refer to: en.wikipedia.org/wiki/Viable_system_model |
|
The Viable System Model — Stafford Beer, published by Business Balls; refer to: www.businessballs.com/strategy-innovation/viable-system-model-stafford-beer/ |
|
Object (Computer Science), Wikipedia: The Free Encyclopedia; refer to: en.wikipedia.org/wiki/Object_(computer_science) |
|
OOPs Object Oriented Design; refer to: www.geeksforgeeks.org/oops-object-oriented-design/ |
|
Information Hiding, Wikipedia: The Free Encyclopedia; refer to: en.wikipedia.org/wiki/Information_hiding |
|
IBM Academy of Technology, Wikipedia: The Free Encyclopedia; refer to: en.wikipedia.org/wiki/IBM_Academy_of_Technology |
|
Social Machine, Wikipedia: The Free Encyclopedia; refer to: en.wikipedia.org/wiki/Social_machine |
|
Panisson, A, The Egyptian Revolution on Twitter, February 2011; refer to: www.youtube.com/watch?v=2guKJfvq4uI |
|
Panisson, A, The Egyptian Revolution on Twitter, February 2011; refer to: www.youtube.com/watch?v=2guKJfvq4uI&t=131s |
|
The Laboratory for Social Machines, MIT Media Lab; refer to: socialmachines.org/ |
|
SOCIAM: The Theory and Practice of Social Machines; refer to: gow.epsrc.ukri.org/NGBOViewGrant.aspx?GrantRef=EP/J017728/2 |
|
SOCIAM: The Theory and Practice of Social Machines; refer to: www.cdcs.ed.ac.uk/research-clusters/media-communications/sociam |
|
SOCIAM: The Theory and Practice of Social Machines; refer to: www.cs.ox.ac.uk/projects/SOCIAM/ |
|
Hall, W., EPSRC. SOCIAM: The Theory and Practice of Social Machines; refer to: www.southampton.ac.uk/research/projects/w-hall-epsrc-sociam-the-theory-practice-of-social-machines |
|
Besha, P., Promoting Deeper Learning and Understanding in Human Networks; refer to: www.media.mit.edu/groups/social-machines/overview/ |
|
Gaia-X; refer to: www.data-infrastructure.eu/GAIAX/Navigation/EN/Home/home.html |
|
Gaia-X; refer to: www.bmwk.de/Redaktion/EN/Dossier/gaia-x.html |
|
Guha, R.V., Data Commons: Making Sustainability Data Accessible, April 2022; refer to: blog.google/outreach-initiatives/sustainability/data-commons-sustainability/ |
|
Data Commons; refer to: www.datacommons.org/ |
|
Ecosystems; refer to: gaia-x.eu/who-we-are/vertical-ecosystems/ |
|
Lighthouse Projects; refer to: gaia-x.eu/who-we-are/lighthouse-projects/ |
|
Gaia-X Conceptual Model; refer to: gaia-x.gitlab.io/technical-committee/architecture-document/gx_conceptual_model/ |
|
Where Did Gaia-X Go Wrong?, October 2022; refer to: www.forrester.com/what-it-means/ep289-future-of-gaiax/ |
|
European Cloud Project Gaia-X is Stuck in the Concept Stage, April 2022; refer to: www.cio.com/article/308818/european-cloud-project-gaia-x-is-stuck-in-the-concept-stage.html |
|
Gartner Hype Cycle; refer to: www.gartner.co.uk/en/methodologies/gartner-hype-cycle |
|
Ramanathan V. Guha Ramanathan, Wikipedia: The Free Encyclopedia; refer to: en.wikipedia.org/wiki/Ramanathan_V._GuhaRamanathan |
|
W3C; refer to: www.w3.org/ |
|
Resource Description Framework (RDF); refer to: www.w3.org/RDF/ |
|
Web Ontology Language (OWL); refer to: www.w3.org/2001/sw/wiki/OWL |
|
SPARQL Query Language for RDF; refer to: www.w3.org/2001/sw/wiki/SPARQL |
|
Semantic Web Best Practices and Deployment (SWBPD) Working Group Charter; refer to: www.w3.org/2003/12/swa/swbpd-charter |
|
Software Engineering Task Force (SETF); refer to: www.w3.org/2001/sw/BestPractices/SE/ |
|
Extensible Markup Language (XML); refer to: www.w3.org/XML/ |
|
Mermaid Diagramming and Charting Tool; refer to: mermaid.js.org |
|
PlantUML at a Glance; refer to: plantuml.com/ |
|
Plant Text — The Expert’s Design Tool; refer to: www.planttext.com/ |
|
Senary, Wikipedia: The Free Encyclopedia; refer to: en.wikipedia.org/wiki/Senary |
|
ASCII Table According to Windows-1252; refer to: www.ascii-code.com/ |
|
Tetlow, P., Garg, D., Chase, L., Mattingly-Scott, M., Bronn, N., Naidoo, K., and Reinert, E., Towards a Semantic Information Theory (Introducing Quantum Corollas), January 2022; refer to: arxiv.org/abs/2201.05478 |
|
Widdows, D., Kitto, K., and Cohen, T., Quantum Mathematics in Artificial Intelligence, January 2012; refer to: arxiv.org/abs/2101.04255 |
|
Introducing ChatGPT, OpenAI, November 2022; refer to: openai.com/blog/chatgpt |
|
MDA® — The Architecture of Choice for a Changing World; refer to: www.omg.org/mda/ |
|
Object Management Group, Model Driven Architecture (MDA), MDA Guide Rev. 2.0, January 2014; refer to: www.omg.org/cgi-bin/doc?ormsc/14-06-01.pdf |
|
Meta Object Facility, Version 2.5.1, October 2016; refer to: www.omg.org/spec/MOF |
|
XML Metadata Interchange, Version 2.51, June 2015; refer to: www.omg.org/spec/XMI |
|
Common Warehouse Metamodel, Version 1.1, March 2003; refer to: www.omg.org/spec/CWM |
|
MDA Specifications; refer to: www.omg.org/mda/specs.htm |
|
Jeffrey, P. Z., Staab, S., Aßmann, U., Ebert, J., Zhao, Y., and Oberle, D., Ontology-Driven Software Development, published by Springer, 2013 |
|
The Cognitive Enterprise: Reinventing your Company with AI, published by BizTech Insights IBM, 2019; refer to: advance.biz-tech-insights.com/whitepaper/Q4-IBM-Industry-Marketing-CS-1-land.html |
|
Berners-Lee, T. and Hendler, J., From the Semantic Web to Social Machines: A Research Challenge for AI on the World Wide Web, published in Artificial Intelligence, Vol. 174(2), pp.156-161, February 2010 |
|
Shadbolt, N., Smith, D., Simperl, E., Van Kleek, M., Yang, Y., and Hall, W., Towards a Classification Framework for Social Machines, pp.905-912, in 22nd International World Wide Web Conference, Rio De Janerio, 2013 |
|
Smart, P., Madaan, A., and Hall, W., Where the Smart Things Are: Social Machines and the Internet of Things, published in Phenomenology and the Cognitive Sciences, Vol. 18(3), pp.551-575, July 2018 |
|
Lyngs, U., Binns, R., Van Kleek, M., and Shadbolt, N., So, Tell Me What Users Want, What They Really, Really Want!, March 2018; refer to: arxiv.org/abs/1803.02065# |
|
Smart, P., The Rise of the (Social) Machines, 17th IFIP Working Conference on Virtual Enterprises, Portugal, 2016 |
|
Luczak-Roesch, M., Tinati, R., O’Hara., K., and Shadbolt, N., Socio-Technical Computation in 18th ACM Conference Companion on Computer Supported Cooperative Work & Social Computing, Vancouver, 2015 |
|
Matrix (Mathematics), Wikipedia: The Free Encyclopedia; refer to: https://en.wikipedia.org/wiki/Matrix_(mathematics) |
|
Tensor, Wikipedia: The Free Encyclopedia; refer to: en.wikipedia.org/wiki/Tensor |
|
Gayler, R.W., Vector Symbolic Architectures Answer Jackendoff’s Challenges for Cognitive Neuroscience, published by Cornell University, December 2004; refer to: arxiv.org/abs/cs/0412059 |
|
Complete Guide to GDPR Compliance; refer to: gdpr.eu/ |
|
Society 5.0, Japanese Cabinet Office; refer to: www8.cao.go.jp/cstp/english/society5_0/index.html |
{kind=link}