21. Software Architecture
This chapter defines software architecture and covers key software architecture styles, patterns, and practices for the digital age.
21.1. What is Software Architecture?
Modern software systems are composed of multiple components that communicate and interact to deliver whole “applications” that can now be composed of several user (e.g., a front-office and a back-office UI) and programmatic interfaces (API for the UI, API intended to be consumed by the customer, etc.).
Software architects deal with system decomposition and their responsibilities and dependencies. They use models, such as the C4 Model, to describe software system architecture effectively through simple diagrams with boxes and lines.
Software architecture deals with significant elements of the components of these systems and their structure, as well as how they interact together.
Software architecture has a strong focus not only on the structure of code but also on all the non-functional requirements:
-
Security (authentication, authorization, integrity and confidentiality, auditability, etc.)
and the cross-cutting inner concerns of software, detailed in Section 21.5, that include selecting technology, planned evolution, and defining roadmaps by following market and community evolution.
The process and practices of the team(s) that produce software systems are also closely related to the topic of software architecture; these practices include:
-
Design of the software: tactical building-blocks and principles of domain-driven design
-
Software-craftmanship practices
-
Source code management: how the team works with version-control systems like Git, and their branching strategy
-
Testing strategy and practices: test-driven development, behavior-driven development, property-based testing, etc.
-
Release engineering (a reliable release process is the foundation of a reliable service [Beyer 2016])
-
Quality insurance and control
-
Defining standards such as reference architectures, practices, tools, etc.
-
Project management framework (Kanban, Scrum, etc.)
Besides the pure engineering role, software architects also need to have good soft and human skills in order to:
-
Coach and mentor software engineers
-
Help people to grow their skills
-
Provide leadership through publications, blogs, conference talks
-
Own the system’s big picture
-
Foster a culture of quality and improvement
-
Be a good communicator and decision-maker
21.2. Event-Driven Architecture
As its name implies, event-driven architecture is centered around the concept of an “event”; that is, whenever something changes an event is issued to notify the interested consumers of such a change. An event is a powerful concept to build architecture around because of the immutable and decoupling nature of events, as well as being a great way to design and build domain logic. The following sections detail the concepts and benefits of event-driven architecture, and then dive into the practical details of implementing such an architecture.
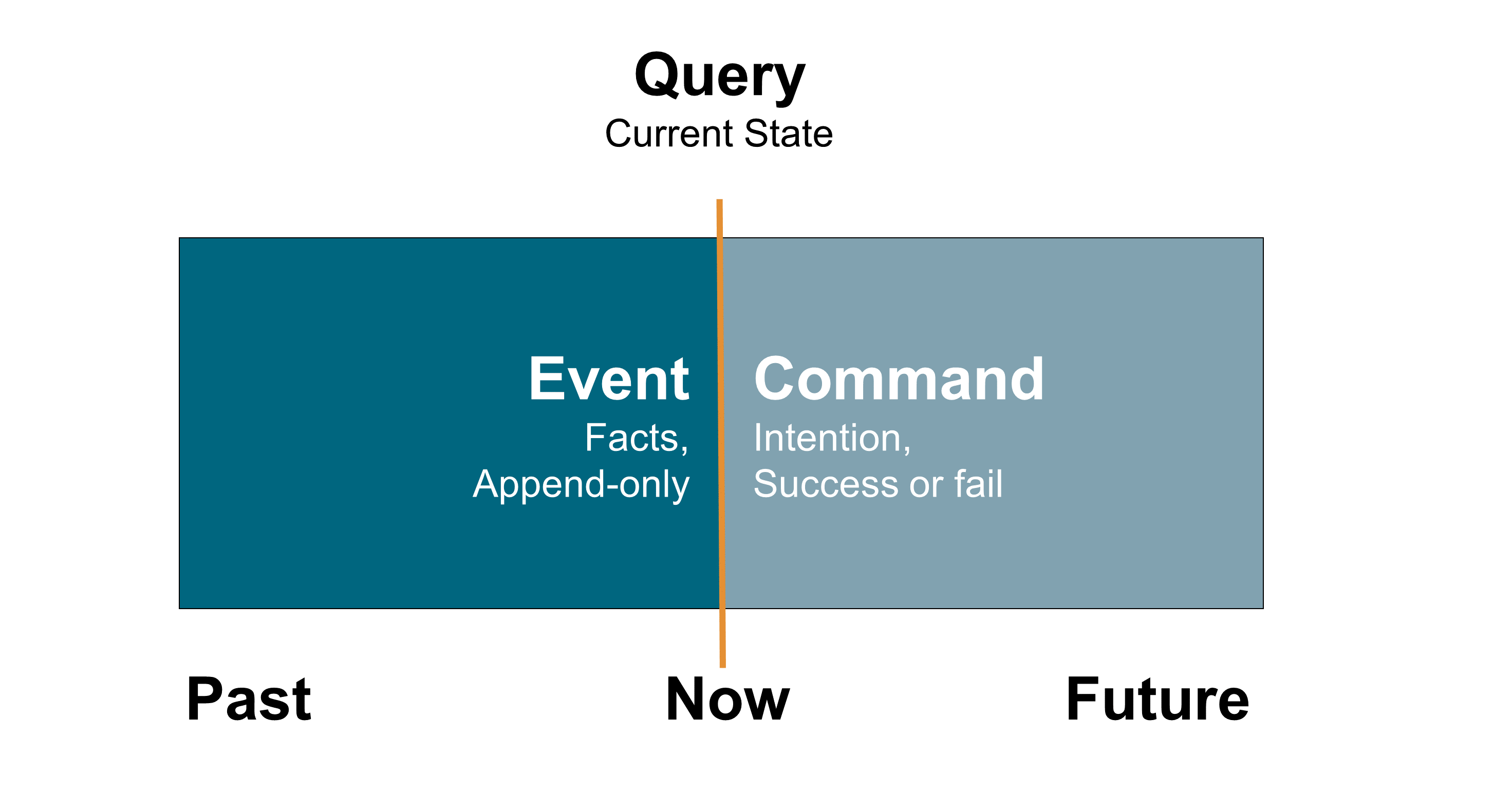
21.2.1. Concepts of Command, Query, and Event
First, before diving into the event-driven architecture style, this document will define the command, query, and event concepts and their relations regarding time and state management:
-
A command represents the intention of a system’s user regarding what the system will do that will change its state
-
A query asks a system for its current state as data in a specific model
-
An event represents a fact about the domain from the past; for every state change the system performs it will publish an event to denote that state mutation
Figure 53 illustrates these time-related concepts.
Command
"A command is a request made to do something."
A command represents the intention of a system’s user regarding what the system will do to change its state.
Command characteristics:
-
The result of a command can be either success or failure; the result is an event
-
In case of success, state change(s) must have occurred somewhere (otherwise nothing happened)
-
Commands should be named with a verb, in the present tense or infinitive, and a nominal group coming from the domain (entity of aggregate type)
Query
"A query is a request asking to retreive some data about the current state of a system."
A query asks a system for its current state as data with a specific model.
Query characteristics:
-
A query never changes the state of the system (it is safe)
-
Query processing is often synchronous
-
The query contains fields with some value to match for, or an identifier
-
A query can result in success or failure (not found) and long results can be paginated
-
Queries can be named with “get” something (with identifiers as arguments) or “find” something (with values to match as arguments) describing the characteristics of the data to be retrieved
Event
"Something happened that domain experts care about." (Evans 2003)
An event represents a fact about the domain from the past; for every state change the system performs, it will publish an event to denote that state mutation.
Event characteristics:
-
Events are primarily raised on every state transition that acknowledged the new fact as data in our system
-
Events can also represent every interaction with the system, even when there is no state transition as the interaction or the failure can itself be valuable; for example, the failure of a hotel booking command due to no-vacancies can be an opportunity to propose something else to the customer
-
-
Events reference the command or query identifier that triggered them
-
Events can be ignored, but cannot be retracted or deleted; only a new event can invalidate a previous one
-
Events should be named with a past participle
-
There are internal and external events:
-
Internal events are raised and controlled in the system bounded context; see Bounded Context
-
External events are from other upstream bounded contexts to which the system subscribes
-
Events are published whenever there is an interaction with the system through a command (triggering or not a state transition; if not, the failure is also an event) or a query (no state transition, but the interaction is interesting in itself, such as for analytics purposes).
21.2.2. Benefits of Event-Driven Architecture
Better Handling of State, Concurrency, and Time
Basically, command and query represents the intention of end users regarding the system:
-
A command represents the user asking the system to do something – they are not safe as they will mutate the state
-
A query asks the current state of the system – they are safe as they will not mutate any data
This distinction relates to state and time management as well as expressing what the user wants the system to do and, once the state has mutated, the system will publish an event notifying the outside world that something has happened.
The Real World is Event-Driven
The world is event-driven as the present is very difficult to grasp and only the past and future can be clearly separated. The past is the only thing that it is possible to (almost) be sure of and the event way of describing the result that occurred in the past, or should occur with the future system, is to use an event. It is as simple as “this happened”. The event storming workshop format (see Chapter 19) is one of the most efficient and popular ways of grasping a domain for people involved in software design.
Loose-Coupling and Strong Autonomy
Event mechanisms loosen the coupling between the event publisher and the subscribers; the event publisher does not know its subscribers and their numbers. This focus on an event also enforces a better division of concerns and responsibility as too many events or coarse-grained events can be a design issue.
Focus on Behavior and Changeability
Commands and events force software designers to think about the system’s behavior instead of placing too much focus on its structure.
Software designers and developers should focus on separating their domain logic between:
-
Contextual data: retrieving data for that command to execute
-
Decision logic: whether this command is actually able to operate given the current contextual state (that includes any data coming from external systems, such as market data as well as time)
-
State mutation logic: once the context data is retrieved and decisions are made, the domain logic can issue what the state mutations are – whether internal or external
-
State mutation execution: this is where transactional mechanisms come into play, being automated for a single data source or distributed using a Saga pattern (see Section 21.2.7) and compensating transactions
-
Command execution result: the command execution result, be it a success or a failure, is expressed as an event published for private or public consumption
This separation of different concerns leads to greater changeability of software systems.
Better Operability with Events: Stability, Scalability, Resilience, and Observability
Commands can be used to better represent the user’s intention, and fit well with the deterministic domain logic that benefits from consensus algorithms, such as the Raft Consensus Algorithm [Raft], to distribute the execution of business logic on several machines for better resiliency and scalability, along with some sharding logic [Ries 2009].
Good operability needs good observability of the running system and this is reached by strong logging practices. Good logs are actually events in disguise; replaying a system’s behavior through logs is actually following the flow of technical and domain events that exhibit what the system has done.
21.2.3. Event Sourcing
The event store becomes the source of truth and the system’s end-state is the end result of applying all these events. Event-driven architecture does not mean event sourcing.
21.2.4. Command Query Responsibility Segregation (CQRS)
The main motivation of CQRS to use these dedicated models is to simplify and gain better performance for interactions with a system that is unbalanced (read-intensive/write-scarce or write-intensive/read-scarce interactions). If CQRS simplifies each model in itself, the synchronization and keeping all the models up-to-date also brings some complexity. CQRS can be implemented sometimes without proven requirements and can lead to some over-engineering.
21.2.5. Command, Query, and Event Metadata
Every command, query, and event should share the same metadata, essentially telling us who is emitting when, where, and with what relevance. Also, each artifact should be uniquely identified. This metadata can be the following:
-
Identifier: an identifier, such as a Universally Unique Identifier (UUID) or a Uniform Resource Name (URN) [IETF® 2017]
-
Type: an identifier of the type of this artifact; it should be properly namespaced to be unique among several systems
-
Emitted-by: identifier of the person or system emitting the command/query/event
-
Emitted-at: a timestamp in Coordinated Universal Time (UTC) of when the command/query/event was emitted by the source
-
Source: the source system that emitted the artifact (in case of a distributed system, it can be the particular machine/virtual machine that emitted that artifact)
-
Various key: for partitioning the artifact among one or several values (typically, the command issued for a particular use organization of the system, etc.)
-
Reference: for event, the command or query that triggers that particular event
-
Content-type: the content type of the payload
-
Payload: a payload as a data structure containing everything relevant to the purpose of the artifact
The Cloud Native Computing Foundation (CNCF) issued a specification describing event data in a common way [CloudEvents].
21.2.6. System Consuming Other Systems' Events
Events that originate from a bounded context must be explicitly defined and then they can be consumed by the bounded contexts of others. The traditional domain-driven design context map and the various strategic patterns of bounded context integration are very useful tools for mapping the landscape.
This document also recommend the translation of each event that comes from another bounded context into a command from the context that consumes it, to denote explicitly the intention behind the event’s consumption.
21.2.7. Ensuring Global Consistency with Saga Patterns
To ensure global consistency across multiple systems mechanisms are required to “rollback” or compensate the effect of applying a command to get the system’s global state back to a consistent one (a consistent state does not mean reverting to the state that existed before applying all those commands; a consistent state is where all the sub-systems are consistent with their data).
As an example, think about the way your bank “cancels” a contentious movement in your account; the bank does not remove the contentious movement, instead it issues a new movement compensating the effect of the bad one. For instance, given a contentious debit movement of $100, the bank issues a credit movement of $100 to get back to a consistent balance even if the movements list of the account now exhibits two movements cancelling each other.
As a first step, it is necessary to identify the inverse of each command that will cancel the effect or “compensate” a former one. The Saga patterns describe the structure and behavior needed to attain such a consistency goal: in case of the failure of one command, the other services issue new commands that compensate the former one, and thus “rollback” the whole distributed transaction as a result. Two types of the Saga pattern exist: choreography and orchestration.
Saga Pattern: Choreography
-
Benefits:
-
Simple and easy to understand and build
-
All services participating are loosely-coupled as they do not have direct knowledge of each other; a good fit if the transaction has four or five steps
-
-
Drawbacks:
-
Can quickly become confusing if extra steps are added to the transaction as it is difficult to track which services listen to which events
-
Risk of adding cyclic dependency between services as they have to subscribe to one another’s events
-
Saga Pattern: Orchestration
-
Benefits:
-
Avoids cyclic dependencies between services
-
Centralizes the orchestration of the distributed transaction
-
Reduces complexity for participants as they only need to execute/reply to commands
-
Easier to implement and test; rollback is easier
-
-
Drawbacks:
-
Risk of concentrating too much logic in the orchestration
-
Increases the infrastructure complexity as there is one extra service
-
21.3. Hexagonal Architecture: Why? Benefits?
One of the greatest challenges of application architecture is to reach a good separation of concerns between the domain, application, and infrastructure logic in the code. Particularly it is necessary to keep the domain logic clean of any technologic concerns (persistence, distribution, UI, etc.). Big maintainability and evolvability troubles occur when domain logic is scattered all over the codebase. Hexagonal architecture decouples the application, domain, and infrastructure logic of the considered system.
Hexagonal architecture, created by Alistair Cockburn [Cockburn 2005], brings an interchangeability of adapter implementation and, therefore, a great suppleness in composing the domain with various ways of interacting with the software, as well as implementing infrastructure capabilities. Hexagonal architecture allows an effective decoupling of application, domain, and infrastructure concerns.
Hexagonal architecture is a departure from layered architecture that is considered as not solving correctly the coupling challenge between the different “layers”. The name “hexagonal architecture” was used because a hexagon is a shape that composes easily, has a great natural symmetry, and allows people drawing schema to have room to insert ports and adapters wherever they need to. There is a notable symmetry not only denoted by its shape, but also with the inbound ports and adapters on the left side and outbound on the right side.
21.3.1. Domain, Application, and Infrastructure Code
The domain code is the code dealing with the domain concepts and related behavior. The application code is the code that interacts with the external world. It makes the software concrete; applications receive requests from end users or other systems.
21.3.2. Inside and Outside, Ports and Adapters
Hexagonal architecture emphasizes that the “inside” of an application, its domain core, must be kept safe from the “outside”, the application and infrastructure logic that embeds the domain into the real world. The domain part of an application is its most valuable asset. Application and infrastructure code change very rapidly given the pace of technology evolutions; just look at the changes in the front end world in recent years.
All dependencies in the application are directed towards the center of the hexagon: the domain. The application and infrastructure logic depend on the domain.
Isolating the code of the domain from the rest of the code is crucial. To ensure the domain part is valuable and not anemic, architects need to ensure that all the domain logic is in the domain part and not scattered in the application and infrastructure code. A good enforcing practice is to automate business scenario tests to run on the domain code only, which ensures that no logic stays in other parts. Domain code should be runnable as a stand-alone library, capable of executing all the domain logic in-memory.
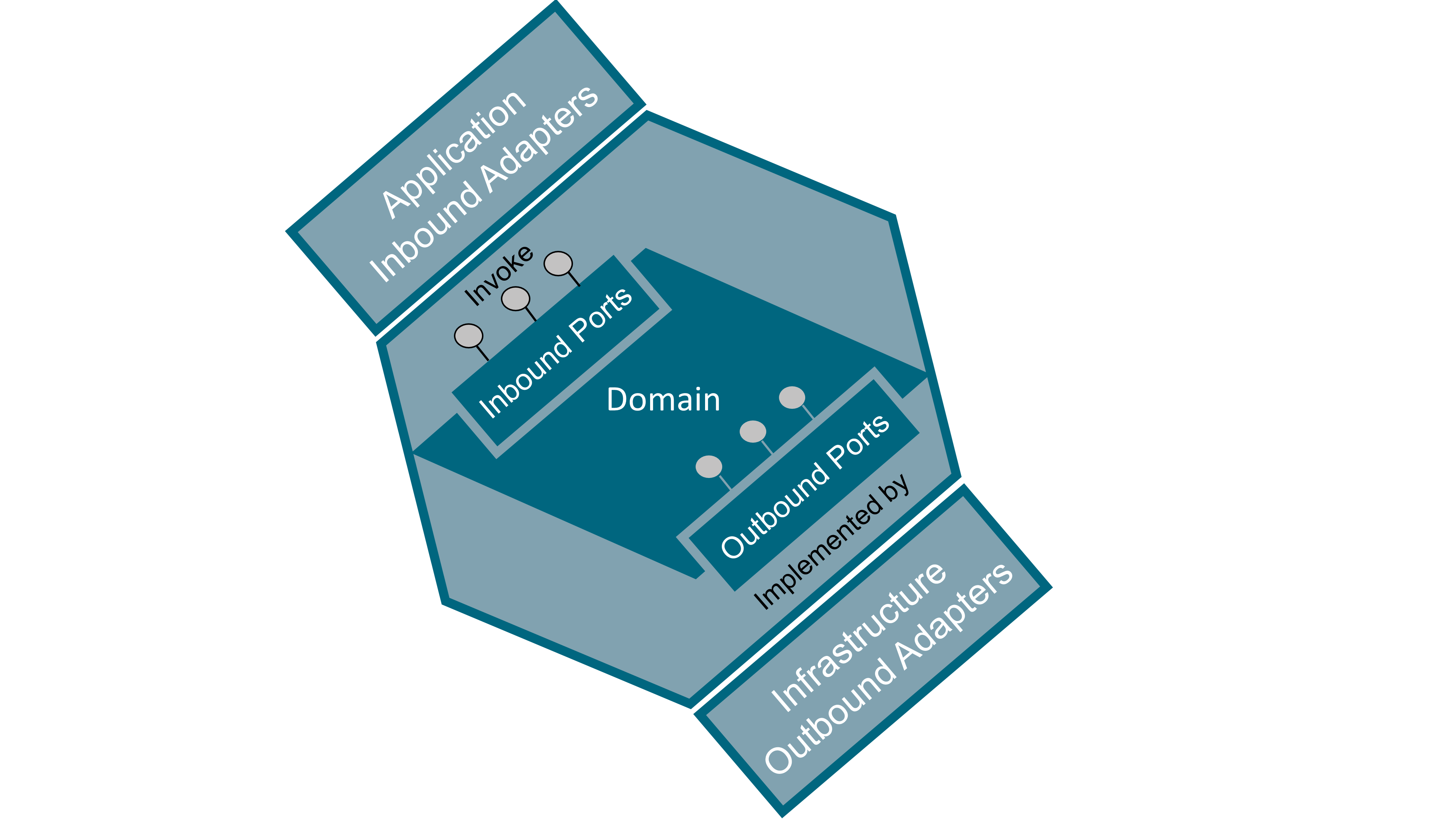
Ports represent the boundaries of the domain. Adapters are any implementation that adheres to the protocol exposed by a port and follows the correct behavior. Adapters can be plugged into the domain to make use of its logic.
This pattern decouples interaction from the domain code by using interfaces located in the domain part (ports) and implementations (adapters) located in the application and infrastructure parts that are wired into the domain, as shown in Figure 54. Hexagonal architecture makes heavy use of the interface/implementation decoupling mechanism found in many programming languages nowadays.
21.3.3. Inbound Ports and Adapters (or Primary, Driving, Left, API)
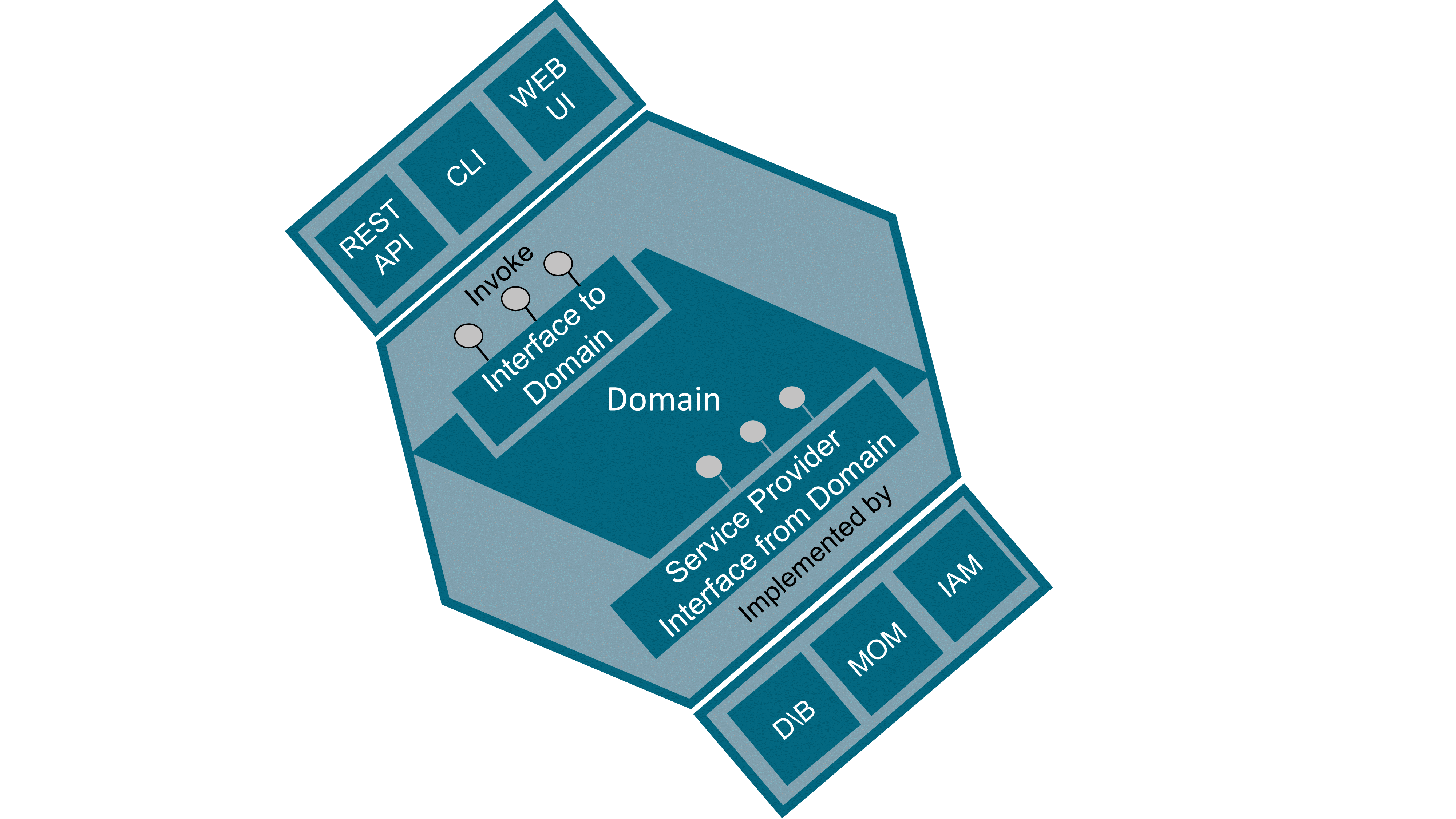
Inbound ports are entry points to the domain. These ports are “driving” the domain; they receive requests from other systems or end users and have the domain react on these stimuli. Inbound ports are located on the left side of the hexagon. Inbound ports are sometimes named as primary, left, driving, or simply API to the domain.
Inbound adapters are implementations of inbound ports that invoke the domain entry point. Common inbound adapter examples are: REST API, Graphical User Interface (GUI), or Command Line Interface (CLI). Inbound adapters are “driving” the domain.
21.3.4. Outbound Ports and Adapters (or Secondary, Driven, Right, SPI)
Outbound ports are exit points invoked from the domain. These ports are “driven” by the domain to perform infrastructure-related tasks. These ports expose contracts abstracted from the underlying infrastructure. Outbound ports are located on the right side of the hexagon. The interfaces that represent these ports are located in the domain code, their implementation being outside of it in the infrastructure code. Outbound ports are sometimes named as secondary, right, driven, or simply Service Provider Interface (SPI).
Outbound adapters are implementations of outbound ports that are invoked from within the domain. The domain exposes outbound ports as the interface of the operations it intends to invoke while being completely agnostic of their implementation; infrastructure code then implements these ports. Of course, implementation of the interface must obey the Liskov substitution principle that states that components must be interchangeable regarding not only their operations signature but also, and in particular, their behavior. Outbound adapters are “driven” by the domain. Common outbound adapter examples are: DataBase (DB) repository, Message-Oriented Middleware (MOM), Identity and Access Management (IAM) systems, and other external systems on which the domain depends.
21.4. Non-Functional Software Requirements
Software architects must assess the priority of every non-functional requirement of the system they are building. Given that it is impossible to reach the maximum for every quality attribute, and that cost and delay add themselves to the equation, trade-offs must be made given the system context and the priorities given. By the way, a name with no negation would be better, so it may be better to talk about Operational Requirements instead of Non-Functional Requirements but people are used to NFRs.
The following sections give an overview of software quality attributes that must be dealt with by software architects.
21.4.1. Security
Major security topics are:
-
Global architecture view and governance of IAM
-
Proper and unique identification of persons and systems accessing software systems
-
Standard authentication modes
-
Authorization: what permissions on what resources for who, and what workflow services?
-
Audit logs of access
-
Monitoring abilities (metrics and alarms)
-
Data security and privacy (including logs produced by the software itself)
-
Security incident management
-
System and communication protection
-
Integrity and confidentiality of data at rest and in transit with encryption, signature, and key management
-
Vulnerability and patch management (breach testing)
Software security needs a plan and a budget defined by business, security teams, and IT teams.
21.4.2. Reliability
Reliability is decomposed into three quality attributes: maturity, recoverability, and fault tolerance.
Maturity (aka Stability)
Maturity relates to the mitigation of negative side effects that change can introduce (especially with high velocity development). Maturity can be measured with mean time between failures, test coverage, and availability of integration and deployment pipelines.
Practices that improve maturity are:
-
Standardized development cycle
-
Thorough tests (unit, integration, end-to-end)
-
Fully automated continuous integration (test, packaging, build, release)
-
Continuous deployment pipeline (with staging, canary, production phase)
-
Progressive rollout of new version (deploy, release, post-release) in relation to feature toggling
-
Dependencies (known with fallback in case of failure)
-
Routing and discovery
-
Deprecation and decommissioning
Recoverability
Recoverability can be measured with mean time of failure detection and alert, mean time to mitigate, mean time to resolve, recovery point and recovery time, and data backup coverage.
Practices that improve recoverability are:
-
Good failure detection
-
Reversion mechanisms (ability to roll back to previous version of code and data with backup)
-
Process for handling incidents and outages
-
Levels and impact of failures
-
Clearly defined mitigation strategies
-
Five stages of incident response (assess, coordinate, mitigate, resolve, follow-up)
-
Fault Tolerance
Fault tolerance can be measured with failure rate and proportion of degraded features after failure.
Practices that improve fault tolerance are:
-
Avoiding single points of failure (redundancy)
-
Proper fault isolation (circuit breaker, bulkheads, etc.)
-
Identifying failure scenarios on all layers: hardware, network, dependency, internal
-
Resiliency testing:
-
Unit, integration, end-to-end tests
-
Regular/automated load testing
-
Chaos testing (including degraded network conditions)
-
-
Implementing the “stability” patterns [Nygard 2018]
21.4.3. Performance
Scalability
Scalability can be measured with Requests per Second (RPS), latency percentiles, Queries per Second (QPS), and business metrics (x per second, percentiles).
Practices that improve scalability are:
-
Effective load testing
-
Quantitive growth scales are well known (RPS, QPS)
-
Qualitative growth scales are well known (e.g., business metrics growth scale related to the system)
-
Capacity planning is automated and performed on a scheduled basis
-
Scalability of dependencies is known and managed
-
Traffic:
-
Patterns are understood (burst, etc.)
-
Can be re-routed in case of failures
-
Performance
Bare performance is different to performance with an increased load; system performance and efficiency change when load is increased, and a system with poor performance during unitary usage has fewer chances to get a better performance with multiple concurrent usages. Performance is usually measured by: RPS, latency percentiles, QPS, business metrics (x per second, percentiles).
Practices that improve performance are:
-
Effective load testing
-
Bottlenecks of resources and requirements have been identified (profiling)
-
Handling and processing tasks in a performant manner (favor statelessness, non-blocking Input/Output (IO))
-
Handling and storing data in a scalable and performant way (best database for use-case?)
Efficiency
Efficiency can be measured with RPS, QPS, and business metrics (maximum x per second, percentiles).
Practices to improve efficiency are:
-
Effective load testing
-
Use hardware resources efficiently
-
Dedicated or shared hardware?
-
Resource abstraction or allocation technology?
-
-
Resource awareness
-
Resource requirements are known (Central Processing Unit (CPU), Random Access mMmory (RAM), etc.)
-
How much traffic one instance can handle (CPU/RAM required?)
-
Resource bottlenecks?
-
21.4.4. Operability
Observability
Observations are event logs, metrics, traces (end-to-end flow in case of distributed system), and errors with context. Practices to improve observability are:
-
Collecting logs, metrics, and traces effectively for each layer: host, infrastructure, platform, application
-
Scalable and cost-effective centralized logging solution?
-
Does logging accurately reflect the state of the system at any given time?
-
-
Dashboard with key metrics and easy to interpret (how is the system working?)
-
Effective alerting: appropriate thresholds, actionable, with entries in an on-call runbook
-
Building a culture of engineering based on facts and feedback
Documentation
Practices to improve the understanding of systems are:
-
Comprehensive and useful documentation, updated regularly (distinguish “How-to” and “Why” documentation, living documentation whenever possible)
-
Documentation contains:
-
Descriptions of the system
-
Architecture diagrams
-
On-call information, runbook (updated after postmortem)
-
Endpoints, request flow, dependencies
-
Frequently Asked Questions (FAQs)
-
-
Architecture is reviewed and audited frequently (with shared checklist)
-
Developers understand production-readiness standards
Deployability
Some practices to improve deployability are:
-
Environments parity (development, staging, production, etc.)
-
Build and deployment pipeline with different stages: build, packaging, testing, deployment, releasing in canary environment (small percentage of production traffic), slow rollout to full production
-
Versioned configuration, separated from code
-
Proper versioning scheme, semantics, and behavior with each release
-
Treat dependency as attached resources
-
Fast startup time and graceful shutdown
-
Zero-downtime mechanisms
21.4.5. Maintainability
Maintainability designates the amount of effort needed to modify the software. A lot of practices exist to improve maintainability; some widely accepted practices are:
-
Software craftmanship approach to software development:
-
Activities that improve developers' skills: kata, pair programming, mob programming
-
Define software quality criteria:
-
Meet user needs through clearly defined use-cases
-
Develop with controlled costs and deadlines
-
Intrinsic qualities of the project: modularity, stability, scalability, readability
-
-
Build and maintain teams of passionate, involved, pragmatic, humble, and legitimate developers
-
Promote communication and pairing practices in order to maintain the team’s homogeneity in its practices and values
-
Let the developers choose their tools as far as possible and within the constraints
-
Encourage an environment conducive to design practices (domain-driven design), testing (behavior-driven development and test-driven development), and frequent code refactoring
-
Set up moments of exchange on techniques and practices so that each employee (business, technical, manager) can learn from the knowledge of the other
-
Rely on the community to benefit from its innovations (conferences, meetups, etc.)
-
-
Domain-driven design
-
Test-driven development
-
eXtreme programming practices (still valuable):
-
Coding practices: simplicity, refactor mercilessly, develop coding standards, develop a common vocabulary
-
Developer practices: integrate continuously, practice pair programming, test-driven development, collect code ownership
-
Business practices: sustainable pace, add customers to the team, planning game, release regularly
-
Maintainability can be refined further into quality attributes, as detailed in the next sections.
Testability
Elements promoting testability are:
-
Stateless design and distinction between mutable and immutable data; the functional programming approach greatly increases testability
-
Test datasets that do not vary between execution
-
Easy substitution of component implementation behind the interface – usually the greater the coupling and mutable state inside the software, the lower the testability, so a good separation of concerns, low coupling, and high cohesion promotes good testability
Coupling, Modularity, and Stability
21.4.6. Interoperability
Interoperability refers to the ability of software systems to exchange data and use common protocols to do so. The elements that promote good interoperability are to be classified according to:
-
Semantic interoperability, which deals with the meaning of information (i.e., words) exchanged between entities
It is directly related to the domain model; entities agree on the meaning of the data they exchange. Semantic interoperability characterizes the ability to agree on:
-
The context of the exchange that defines the meaning of words (e.g., a person is seen as a patient in a health application and as a citizen in a public administration application)
-
The process of the exchange: what are the actors, events, and activities related to the exchange?
-
The meaning and structure of the information exchanged needs some kind of agreement, often through documentation
There are some initiatives on the web for structuring common data [Schema.org] and various industries have their own data exchange standards.
-
-
Syntactic and technical interoperability, which conveys information defined at the semantic level and formatted at the syntactic level
It deals with technical norms and standards for:
-
Navigation and restitution technologies
-
Technologies for data exchanges between systems (e.g., REST API over HTTP)
-
The basic technologies necessary for exchanges (infrastructure, including network protocols)
-
Software interoperability is contextual to its environment and is promoted through easy connection with other middleware services that allow quick and easy integration. Some communication protocols like REST API over HTTP are now ubiquitous and provide good openness, but context should drive particular technology usage. Asynchronous communication can also be considered but is more tied to a particular technology stack (e.g., Kafka®, etc.). When dealing with legacy middleware, integration or a bridge can be provided (e.g., Cross File Transfer (CFT), MQSeries®, etc.). The implementation of security and “meta” mechanisms in data that transits through middleware (who, where, when, what) is also an important concern.
21.5. Software Cross-Cutting Concerns
Software architects need to address several cross-cutting concerns in their decisions while building software:
-
Programming language choices: platform more than languages (Common Language Runtime (CLR), Java Virtual Machine, JavaScript engine, etc.); in choosing the best tool for the job, consider the language ecosystem and available skills
-
Testing strategy: a test strategy provides a rational deduction from organizational, high-level objectives of quality to actual test activities to meet those objectives, and a modern testing approach and techniques are crucial to balance the speed of delivery with actual quality
Tests are the safety net of modern software practices like continuous integration/delivery and, beyond the fundamental test-driven development approach, testing techniques have been greatly increased and enhanced recently (generative and property-based testing, resiliency testing, etc.).
-
Persistence of data: particularly the consistency aspect of data, and the storage model (document, relational, graph, etc. )
-
Session handling
-
Business rules
-
Interoperability through:
-
API for synchronous communication between components
-
MOM for asynchronous communication between components (and event-driven architecture style choice)
-
-
UI with unidirectional architecture
-
Parallelism and concurrency
-
Load balancing and fault tolerance
-
Error handling
-
Configuration
-
Stability patterns
-
Monitoring and troubleshooting: logging, metrics, alerting
-
Release, packaging, and deployment mechanisms
-
Versioning
-
Documentation (living documentation)
-
Batch
-
Reporting
-
Legacy migration or integration strategy