This chapter describes in detail the heart of COM: the notion of interfaces
and their relationships to the objects on which they are implemented.
More
specifically, this chapter covers what an interface is (technically), interface
calling conventions, object and interface identity, the fundamental interface
called
IUnknown(), and COM's error reporting mechanism.
In addition, this chapter describes how an object implements one or more interfaces
as well as a special type of object called the ``enumerator'' which comes
up in various contexts in COM.
As described in Part I, the COM Library provides the fundamental implementation locator services to clients and provides all the necessary glue to help clients communicate transparently with object regardless of where those objects execute: in-process, out-of-process, or on a different machine entirely. All servers expose their object's services through interfaces, and COM provides implementations of the ``proxy'' and ``stub'' objects that make communication possible between processes and machines where RPC is necessary.
However, as we'll see in this chapter and those that follow, the COM Library also provides fundamental API functions for both clients and servers or, in general, any piece of code that uses COM, application or not. These API functions will be described in the context of where other applications or DLLs use them. A COM implementor reading this document will find the specifications for each function offset clearly from the rest of the text. These functions are implemented in the COM Library to standardize the parts of this specification that applications should not have to implement nor would want to implement. Through the services of the COM Library, all clients can make use of all objects in all servers, and all servers can expose their objects to all clients. Only by having a standard is this possible, and the COM Library enforces that standard by doing most of the hard work.
Not all the COM Library functions are truly fundamental. Some are just convenient wrappers to common sequences of other calls, sometimes called ``helper functions.'' Others exist simply to maintain global lists for the sake of all applications. Others just provide a solid implementation of functions that could be implemented in every application, but would be tedious and wasteful to do so.
An interface, in the COM definition, is a contract between the user, or client, of some object and the object itself. It is a promise on the part of the object to provide a certain level of service, of functionality, to that client. Chapter 1 and Chapter 2 have already explained why interfaces are important to COM and the whole idea of an object model. This chapter will now fill out the definition of an interface on the technical side.
Technically speaking, an interface is some data structure that sits between the client's code and the object's implementation through which the client requests the object's services. The interface in this sense is nothing more than a set of member functions that the client can call to access that object implementation. Those member functions are exposed outside the object implementor application such that clients, local or remote, can call those functions.
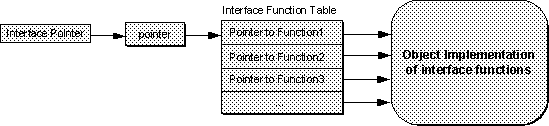
The client maintains a pointer to the interface which is, in actuality, a pointer to a pointer to an array of pointers to the object's implementations of the interface member functions. That's a lot of pointers; to clarify matters, the structure is illustrated in Figure 4-1.
By convention the pointer to the interface function table is called
the
pVtbl
pointer.
The table itself is generally referred
to with the name
vtbl
for ``virtual function table.''
On a given implementation platform, a given method in a given interface (a particular IID, that is) has a fixed calling convention; this is decoupled from the implementation of the interface. In principle, this decision can be made on a method by method basis, though in practice on a given platform virtually all methods in all interfaces use the same calling convention.
In contrast, just for note, COM API functions (not interface members)
use the standard host system-call calling convention, which on both Microsoft
Win16 and Win32 is the
__far __pascal
sequence.
Finally, and quite significantly,
all strings passed through
all COM interfaces
(and, at least on Microsoft platforms, all COM
APIs)
are Unicode strings.
There simply is no other reasonable
way to
get interoperable
objects in the face of (i) location transparency, and (ii) a
high-efficiency object architecture
that doesn't in all cases intervene system-provided code between client and
server.
Further, this burden is in practice not large.
[Footnote 28]
When calling member functions, the caller must include an argument
which is the pointer to the object instance itself.
This is automatically
provided in C++ compilers and completely hidden from the caller.
The Microsoft
Object Mapping
[Footnote 28]
specifies that
this pointer is pushed very last, immediately before the return address.
The
location of this pointer is the reason that the
pIInterface
pointer appears at the
beginning
of the argument list
of the equivalent C function prototype: it means that the layout in the stack
of the parameters to the C function prototype is exactly that expected by
the member function implemented in C++, and so no re-ordering is required.
[Footnote 29]
Usually the pointer to the interface itself is the pointer to
the entire object structure (state variables, or whatever) and that structure
immediately follows
[Footnote 29]
the
pVtbl
pointer memory as shown in
Figure 4-2.
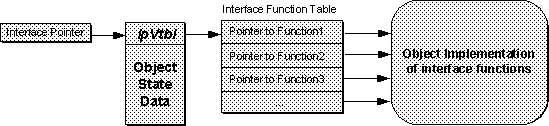
Since the
pVtbl
is received as the
this
pointer in the interface function, the implementor of that function
knows which object is being called--an object is, after all, some structure
and functions to manipulate that structure, and the interface definition here
supplies both.
In any case, this ``vtbl'' structure is called a
binary standard because
on the binary level, the structure is completely determined by the particular
interface being used and the platform on which it is being invoked.
It is
independent of the programming language or tool used to create it.
In other
words, a program can be written in C to generate this structure to match what
C++ does automatically.
For more details, see Section
Section 4.1.4
below.
You could even create this structure in assembly if so inclined.
Since
compilers for other languages eventually reduce source code to assembly (as
is the compiler itself) it is really a matter for compiler vendors to support
this structure for languages such as Pascal, COBOL, Smalltalk, etc.
Thus COM
clients, objects, and servers can be written in any languages with appropriate
compiler support.
Note that it is technically legal for the binary calling conventions
for a given interface to vary according the particular implementation platform
in question, though this flexibility should be exercised by COM system implementors
only with very careful attention to source portability issues.
It is the case,
for example, that on the Macintosh, the
pVtbl
pointer does
not point to the first function in the
vtbl, but rather
to a dummy pointer slot (which is ignored) immediately before the first function;
all the function pointers are thus offset by an index of one in the
vtbl.
An interface implementor is free to use the memory before and beyond
the ``as-specified-by-the-standard''
vtbl
for whatever
purpose he may wish; others cannot assume anything about such memory.
Every interface has a name that serves as the programmatic compile-time type in code that uses that interface (either as a client or as an object implementor). The convention is to name each interface with a capital ``I'' followed by some descriptive label that indicates what functionality the interface encompasses. For example, IUnknown is the label of the interface that represents the functionality of an object when all else about that object is unknown.
These programmatic types are defined in header files provided by the designer of the interface through use of the Interface Description Language (IDL, see next section). For C++, an interface is defined as an abstract base, that is, a structure containing nothing but ``pure virtual'' member functions. This specification uses C++ notation to express the declaration of an interface. For example, the IUnknown interface is declared as:
interface IUnknown()
{
virtual HRESULT QueryInterface(IID& iid, void** ppv) =0;
virtual ULONG AddRef(void) =0;
virtual ULONG Release(void) =0;
};
where ``virtual'' and ``=0''
describe
the attribute of a ``pure virtual'' function and the
interface
keyword is defined as:
#define interface struct
The programmatic name and definition of an interface defines a type
such that an application can declare a pointer to an interface using standard
C++ syntax as in
IUnknown *.
In addition, this specification as a notation makes some use of the C++ reference mechanism in parameter passing, for example:
QueryInterface(const IID& iid, void**ppv);
Usually ``const <type>&'' is written as ``REF<type>'' as in
REFIID
for convenience.
As you might
expect, this example would appear in a C version of the interface as a parameter
of type:
const IID * const
Input parameters passed by reference will themselves be
const, as shown here.
In-out or out- parameters will not.
[Footnote 30]
The use of the
interface
keyword is more a
documentation technique than any requirement for implementation.
An interface,
as a binary standard, is definable in any programming language as shown in
the previous section.
This specification's use of C++ syntax is just a convenience.
[Footnote 30]
Also, for ease of reading, this specification
generally omits parameter types in code fragments such as this but does document
those parameters and types fully with each member function.
Types do, of course,
appear in header files with interfaces.
It is very important to note that the programmatic name for an interface
is only a
compile-time
type used in application source
code.
Each interface must also have a
run-time
identifier.
This identifier enables a caller to query (via
QueryInterface())
an object for a desired interface.
Interface identifiers are GUIDs, that is,
globally-unique 16 byte
values,
of type IID.
The person who defines the interface allocates and assigns the
IID as with any other
GUID,
and he informs others of his
choice at the same time he informs them of the interface member functions,
semantics, etc.
Use of a GUID for this purpose guarantees that the IID will
be unique in all programs, on all machines, for all time, the run-time identifier
for a given interface will in fact have the same 16 byte value.
Programmers who define interfaces convey the interface identifier to
implementors or clients of that interface along with the other information
about the interface (in the form of header files, accompanying semantic documentation,
etc.).
To make application source code independent of the representation of
particular interface identifiers, it is standard practice that the header
file defines a constant for each IID where the symbol is the name of the interface
prefixed with
``IID_''
such that the name can be derived
algorithmically.
For example, the interface
IUnknown()
has an identifier called
IID_IUnknown.
For brevity in this specification, this definition will not be repeated with each interface, though of course it is present in the COM implementation.
The Interface Description Language (IDL) is based on The Open Group's Distributed Computing Environment (DCE) specification for describing interfaces, operations, and attributes to define remote procedure calls. COM extends the IDL to support distributed objects.
A designer can define a new custom interface by writing an interface definition file. The interface definition file uses the IDL to describe data types and member functions of an interface. The interface definition file contains the information that defines the actual contract between the client application and server object. The interface contract specifies three things:
Language binding--defines the programming model exposed to the application program using a particular programming language.
Application binary interface--specifies how consumers and providers of the interface interoperate on a particular target platform.
Network interface--defines how client applications access remote server objects via the network.
After completing the interface definition file, the programmer runs the IDL compiler to generate the interface header and the source code necessary to build the interface proxy and interface stub that the interface definition file describes. The interface header file is made available so client applications can use the interface. The interface proxy and interface stub are used to construct the proxy and stub DLLs. The DLL containing the interface proxy must be distributed with all client applications that use the new interface. The DLL containing the interface stub must be distributed with all server objects that provide the new interface.
It is important to note that the IDL is a tool that makes the job of defining interfaces easier for the programmer, and is one of possibly many such tools. It is not the key to COM interoperability. COM compliance does not require that the IDL compiler be used. However, as IDL is broadly understood and used, it provides a convenient means by which interface specifications can be conveyed to other programmers.
This specification documents COM interfaces using C++ syntax as a notation but (again) does not mean COM requires that programmers use C++, or any other particular language. COM is based on a binary interoperability standard, rather than a language interoperability standard. Any language supporting ``structure'' or ``record'' types containing double-indirected access to a table of function pointers is suitable.
However, this is not to say all languages are created equal. It is certainly true that since the binary vtbl standard is exactly what most C++ compilers generate on PC and many RISC platforms, C++ is a convenient language to use over a language such as C.
That being said, COM can declare interface declarations for both C++ and C (and for other languages if the COM implementor desires). The C++ definition of an interface, which in general is of the form:
interface ISomeInterface
{
virtual RET_T MemberFunction(ARG1_T arg1, ARG2_T arg2 /*, etc */);
[Other member functions]
...
};
then the corresponding C declaration of that interface looks like
typedef struct ISomeInterface
{
ISomeInterfaceVtbl * pVtbl;
} ISomeInterface;
typedef struct ISomeInterfaceVtbl ISomeInterfaceVtbl;
struct ISomeInterfaceVtbl
{
RET_T (*MemberFunction)(ISomeInterface * this, ARG1_T arg1,
ARG2_T arg2 /*, etc */);
[Other member functions]
} ;
This example also illustrates the algorithm for determining the signature of C form of an interface function given the corresponding C++ form of the interface function:
Use the same argument list as that of the member function, but add an initial parameter which is the pointer to the interface. This initial parameter is a pointer to a C type of the same name as the interface.
Define a structure type which is a table of function pointers corresponding to the vtbl layout of the interface. The name of this structure type should be the name of the interface followed by ``Vtbl.'' Members in this structure have the same names as the member functions of the interface.
The C form of interfaces, when instantiated, generates exactly the same binary structure as a C++ interface does when some C++ class inherits the function signatures (but no implementation) from an interface and overrides each virtual function.
These structures show why C++ is more convenient for the object implementor
because C++ will automatically generate the vtbl and the object structure
pointing to it in the course of instantiating an object.
A C object implementor
must define and object structure with the
pVtbl
field first,
explicitly allocate both object structure and interface Vtbl structure, explicitly
fill in the fields of the Vtbl structure, and explicitly point the
pVtbl
field in the object structure to the Vtbl structure.
Filling
the Vtbl structure need only occur once in an application which then simplifies
later object allocations.
In any case, once the C program has done this explicit
work the binary structure is indistinguishable from what C++ would generate.
On the client side of the picture there is also a small difference between
using C and C++.
Suppose the client application has a pointer to an
ISomeInterface
on some object in the variable
psome.
If the client is compiled using C++, then the following line of code would
call a member function in the interface:
psome->MemberFunction(arg1, arg2, /* other parameters */);
A C++ compiler, upon noting that the type of
psome
is an
ISomeInterface *
will know to actually perform the
double indirection through the hidden
pVtbl
pointer and
will remember to push the
psome
pointer itself on the stack
so the implementation of
MemberFunction
knows which object
to work with.
This is, in fact, what C++ compilers do for any member function
call; C++ programmers just never see it.
What C++ actually does is be expressed in C as follows:
psome->lpVtbl->MemberFunction(psome, arg1, arg2, /* other parameters */);
This is, in fact, how a client written in C would make the same call. These two lines of code show why C++ is more convenient--there is simply less typing and therefore fewer chances to make mistakes. The resulting source code is somewhat cleaner as well. The key point to remember, however, is that how the client calls an interface member depends solely on the language used to implement the client and is completely unrelated to the language used to implement the object. The code shown above to call an interface function is the code necessary to work with the interface binary standard and not the object itself.
The double indirection of the vtbl structure has an additional, indeed enormous, benefit: the pointers in the table of function pointers do not need to point directly to the real implementation in the real object. This is the heart of Location Transparency.
It is true that in the in-process server case, where the object is loaded directly into the client process, the function pointers in the table are, in fact, the actual pointers to the actual implementation. So a function call from the client to an interface member directly transfers execution control to the interface member function.
However, this cannot possibly work for local, let alone remote, object, because pointers to memory are absolutely not sharable between processes. What must still happen to achieve transparency is that the client continues to call interface member functions as if it were calling the actual implementation. In other words, the client uniformly transfers control to some object's member function by making the call.
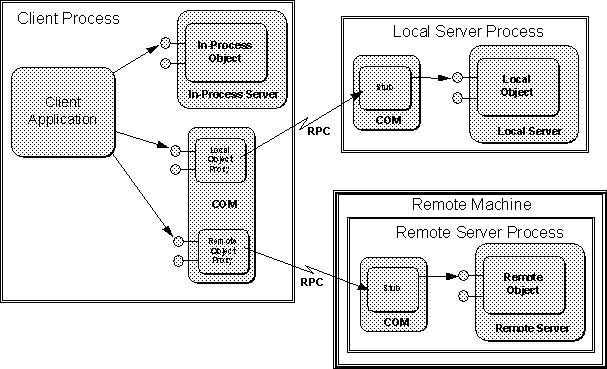
So what member function actually executes? The answer is that the interface member called is implemented by a proxy object that is always an in-process object that acts on behalf of the object being called. This proxy object knows that the actual object is running in a local or remote server and so it must somehow make a remote procedure call, through a standard RPC mechanism, to that object as shown in Figure 4-3.
The proxy object packages up the function parameters in some data packets and generates an RPC call to the local or remote object. That packet is picked up by a stub object in the server's process, on the local or a remote machine, which unpacks the parameters and makes the call to the real implementation of the member function. When that function returns, the stub packages up any out-parameters and the return value, sends it back to the proxy, which unpacks them and returns them to the original client. For exact details on how the proxy-stub and RPC mechanisms work, see Chapter 9.
[Footnote 31]
The bottom line is that client and server always talk to each
other as if everything was in-process.
All calls from the client and all calls
to the server do at some point, in fact, happen in-process.
But because the
vtblstructure allows some agent, like COM, to intercept all function
calls and all returns from functions, that agent can redirect those calls
to an RPC call as necessary.
All of this is completely transparent to the
client and server, hence Location Transparency.
[Footnote 31]
As mentioned earlier in this document, the GUID, from which are also
obtained CLSID, IIDs, and any other needed
unique identifier, is a 128-bit, or 16-byte, value.
The term GUID as used
in this specification is completely synonymous and interchangeable with the
term ``UUID'' as used by the DCE RPC architecture; they are indeed one and
the same notion.
In binary
terms, a GUID is a data structure defined as follows, where
DWORD
is 32-bits,
WORD
is 16-bits, and
BYTE
is 8-bits:
typedef struct GUID {
DWORD Data1;
WORD Data2;
WORD Data3;
BYTE Data4[8];
} GUID;
This structure provides applications with some way of addressing the parts of a GUID for debugging purposes, if necessary. This information is also needed when GUIDs are transmitted between machines of different byte orders.
For the most part, applications never manipulate GUIDs directly--they are almost always manipulated either as a constant, such as with interface identifiers, or as a variable of which the absolute value is unimportant. For example, a client might enumerate all object classes registered on the system and display a list of those classes to an end user. That user selects a class from the list which the client then maps to an absolute CLSID value. The client does not care what that value is--it simply knows that it uniquely identifies the object that the user selected.
The GUID design allows for coexistence of several different allocation technologies, but the one by far most commonly used incorporates a 48-bit machine unique identifier together with the current UTC time and some persistent backing store to guard against retrograde clock motion. It is in theory capable of allocating GUIDs at a rate of 10,000,000 per second per machine for the next 3240 years, enough for most purposes.
[Footnote 32] For further information regarding GUID allocation technologies, see pp585-592 of [CAE RPC]. [Footnote 32]
This specification has already mentioned the
IUnknown()
interface many times.
It is the fundamental interface in COM that contains
basic operations of not only all objects, but all interfaces as well: reference
counting and
QueryInterface().
All interfaces in COM are
polymorphic with
IUnknown(), that is, if you look at the
first three functions in any interface you see
QueryInterface(),
AddRef(), and
Release().
In other words,
IUnknown()
is the base interface from which all other interfaces
inherit.
Any single object usually only requires a single implementation of the
IUnknown()
member functions.
This means that by virtue of implementing
any interface on an object you completely implement the
IUnknown()
functions.
You do not generally need to explicitly inherit from
nor implement
IUnknownas its own interface: when queried
for it, simply typecast another interface pointer into an
IUnknown*
which is entirely legal with polymorphism.
In some specific situations, more notably in creating an object that
supports aggregation, you may need to implement one set of
IUnknown()
functions
for all interfaces as well as a stand-alone
IUnknown
interface.
The reasons and techniques for this are described in Section
Section 8.8.
In any case, any object implementor will implement
IUnknown()
functions, and we are now in a position to look at them in their
precise terms.
Objects accessed through interfaces use a reference counting mechanism to ensure that the lifetime of the object includes the lifetime of references to it. This mechanism is adopted so that independent components can obtain and release access to a single object, and not have to coordinate with each other over the lifetime management. In a sense, the object provides this management, so long as the client components conform to the rules. Within a single component that is completely under the control of a single development organization, clearly that organization can adopt whatever strategy it chooses. The following rules are about how to manage and communicate interface instances between components, and are a reasonable starting point for a policy within a component.
Note that the reference counting paradigm applies only to pointers to interfaces; pointers to data are not referenced counted.
It is important to be very clear on exactly when it is necessary to
call
AddRef()
and
Release()
through
an interface pointer.
By its nature, pointer management is a cooperative effort
between separate pieces of code, which must all therefore cooperate in order
that the overall management of the pointer be correct.
The following discussion
should hopefully clarify the rules as to when
AddRef()
and
Release()
need to be called in order that this may
happen.
Some special reference counting rules apply to objects which are aggregated;
see the discussion of aggregation in
Chapter 8.
The conceptual model is the following: interface pointers are thought of as living in pointer variables, which for the present discussion will include variables in memory locations and in internal processor registers, and will include both programmer- and compiler-generated variables. In short, it includes all internal computation state that holds an interface pointer. Assignment to or initialization of a pointer variable involves creating a new copy of an already existing pointer: where there was one copy of the pointer in some variable (the value used in the assignment/initialization), there is now two. An assignment to a pointer variable destroys the pointer copy presently in the variable, as does the destruction of the variable itself (that is, the scope in which the variable is found, such as the stack frame, is destroyed).
Rule 1:
AddRef()
must be called
for every new copy of an interface pointer, and
Release()
called every destruction of an interface pointer except where subsequent rules
explicitly permit otherwise.
[Footnote 33] This is the default case. In short, unless special knowledge permits otherwise, the worst case must be assumed. The exceptions to Rule 1 all involve knowledge of the relationships of the lifetimes of two or more copies of an interface pointer. In general, they fall into two categories. [Footnote 33]
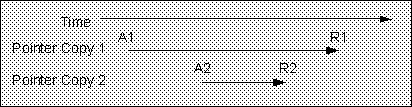
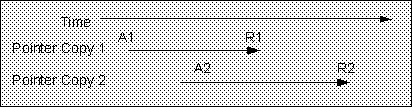
In Category 1 situations, the
AddRef()
A2 and the
Release()
R2 can be omitted, while in Category 2, A2 and R1 can be
eliminated.
Rule 2: Special knowledge on the part of a piece
of code of the relationships of the beginnings and the endings of the lifetimes
of two or more copies of an interface pointer can allow
AddRef/Release
pairs to be omitted.
The following rules call out specific common cases of Rule 2. The first two of these rules are particularly important, as they are especially common.
Rule 2a:
In-parameters to functions.
The copy of an interface pointer which is passed as an actual parameter to
a function has a lifetime which is nested in that of the pointer used to initialize
the value.
The actual parameter therefore need not be separately reference
counted.
Rule 2b:
Out-parameters from functions,
including return values.This is a Category 2 situation.
In order
to set the out parameter, the
function itself by Rule 1 must have a stable copy of the interface
pointer.
On exit, the responsibility for releasing the pointer is transferred
from the callee to the caller.
The out-parameter thus need not be separately
reference counted.
Rule 2c:
Local variables.
A
function implementation clearly has omniscient knowledge of the lifetimes
of each of the pointer variables allocated on the stack frame.
It can therefore
use this knowledge to omit redundant
AddRef/Release
pairs.
[Footnote 34]
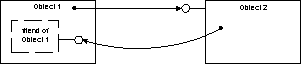
Rule 2d:
Backpointers.
Some data structures are of the nature of containing two components, A and
B, each with a pointer to the other.
If the lifetime of one component (A)
is known to contain the lifetime of the other (B), then the pointer from the
second component back to the first (from B to A) need not be reference counted.
Often, avoiding the cycle that would otherwise be created is important in
maintaining the appropriate deallocation behavior.
However, such non-reference
counted pointers should be used
with extreme caution.In
particular, as the remoting infrastructure cannot know about the semantic
relationship in use here, such backpointers cannot be remote references.
In
almost all cases, an alternative design of having the backpointer refer to
a second ``friend'' object of the first rather than the object itself (thus
avoiding the circularity) is a superior design.
The following figure illustrates
this concept.
[Footnote 34]
The following rules call out common non-exceptions to Rule 1.
Rule 1a:
In-Out-parameters to functions.
The caller must
AddRef()
the actual parameter,
since it will be
Released
by the callee when the out-value
is stored on top of it.
Rule 1b:
Fetching a global variable.
The local copy of the interface pointer fetched from an existing copy of the
pointer in a global variable must be independently reference counted since
called functions might destroy the copy in the global while the local copy
is still alive.
Rule 1c:
New pointers synthesized out of
``thin air.''
A function which synthesizes an interface pointer
using special internal knowledge rather than obtaining it from some other
source must do an initial
AddRef()
on the newly synthesized
pointer.
Important examples of such routines include instance creation routines,
implementations of
IUnknown::QueryInterface(), etc.
Rule 1d:
Returning a copy of an internally
stored pointer.
Once the pointer has been returned, the callee
has no idea how its lifetime relates to that of the internally stored copy
of the pointer.
Thus, the callee must call
AddRef()
on
the pointer copy before returning it.
Finally, when implementing or using reference counted objects, a technique
sometimes termed ``artificial reference counts'' sometimes proves useful.
Suppose
you're writing the code in method
Foo
in some interface
IInterface.
If in the implementation of
Foo
you
invoke functions which have even the remotest chance of decrementing your
reference count, then such function may cause you to release before it returns
to
Foo.
The subsequent code in
Foo
will
crash.
[Footnote 35]
A robust way to protect yourself from this is to insert an
AddRef()
at the beginning of
Foo
which is paired
with a
Release()
just before
Foo
returns:
void IInterface::Foo(void) {
this
[Footnote 35]->AddRef();
/*
* Body of Foo, as before, except short-circuit returns
* need to be changed.
*/
this->Release();
return;
}
These ``artificial'' reference counts guarantee object stability while processing is done.
It is often useful for a client of an object to examine the object's
type information.
Given the object's CLSID, a client can locate the object's
type library using registry entries, and then can scan the type library for
the
coclass
entry in the library matching the CLSID.
However, not all objects have a CLSID, although they still need to provide type information. In addition, it is convenient for a client to have a way to simply ask an object for its type information instead of going through all the tedium to extract the same information from registry entries.
This capability is important when dealing with outgoing interfaces on
connectable objects.
See Using
IProvideClassInfo()
in
Chapter 14
for more information on how connectable
objects provide this capability.
In these cases, a client can query the object for any of the
IProvideClassInfo[x]
interfaces.
If these interfaces exist, the client calls
IProvideClassInfo[x]::GetClassInfo
to get the type information
for the interface.
By implementing
IProvideClassInfo[x], an object specifies that it can provide type information for
its entire class, that is, what it would describe in its
coclass
section of its type library, if it has one.
The
GetClassInfo
method returns an
ITypeInfo()
pointer corresponding
to the object's
coclass
information.
Through this
ITypeInfo()
pointer, the client can examine all the object's incoming
and outgoing interface definitions.
The object can also provide
IProvideClassInfo2().
The
IProvideClassInfo2()
interface is a simple extension
to
IProvideClassInfo()
that makes it quick and easy to
retrieve an object's outgoing interface identifiers for its default event
set.
IProvideClassInfo2()
is derived from
IProvideClassInfo().
[Footnote 36] The COM technology known as Connectable Objects (also called ``connection points'') supports a generic ability for any object, called in this context a ``connectable'' object, to express these capabilities:
The existence of ``outgoing'' interfaces [Footnote 36], such as event sets
The ability to enumerate the IIDs of the outgoing interfaces
The ability to connect and disconnect ``sinks'' to the object for those outgoing IIDs
The ability to enumerate the connections that exist to a particular outgoing interface.
Support for these capabilities involves four interfaces:
IConnectionPointContainer(),
IEnumConnectionPoints(),
IConnectionPoint(), and
IEnumConnections().
A
``connectable object'' implements
IConnectionPointContainer()
to indicate existence of outgoing interfaces.
Through this interface a client
can enumerate connection points for each outgoing IID (via an enumerator with
IEnumConnectionPoints()) and can obtain an
IConnectionPoint()
interface to a connection point for each IID.
Through a connection
point a client starts or terminates an advisory loop with the connectable
object and the client's own sink.
The connection point can also enumerate
the connections it knows about through an enumerator with
IEnumConnections().
See
Chapter 14
for a complete
specification of the connection point interfaces.
Objects can come in all shapes and sizes and applications will implement objects for various purposes with or without assigning the class a CLSID. COM servers implement objects for the sake of serving them to clients. In some cases, such as data change notification, a client itself will implement a classless object to essentially provide callback functions for the server object.
In all cases there is only one requirement for all objects: implement
at least the
IUnknown()
interface.
An object is not a COM
object unless it implements at least one interface which at minimum is
IUnknown().
Not all objects even need a unique identifier, that is,
a CLSID.
In fact,
only
those objects that wish to allow
COM to locate and launch their implementations really need a CLSID.
All other
objects do not.
IUnknown()
implemented by itself can be useful for
objects that simply represent the existence of some resource and control that
resource's lifetime without providing any other means of manipulating that
resource.
By and large, however, most interesting objects will want to provide
more services, that is, additional interfaces through which to manipulate
the object.
This all depends on the purpose of the object and the context
in which clients (or whatever other agents) use it.
The object may wish to
provide some data exchange capabilities by implementing
IDataObject(), or may wish to indicate the contract through which it can serialize
its information by implementing one of the
IPersist()
flavors
of interfaces.
If the object is a moniker, it will implement an interface
called
IMoniker()
that we'll see in
Chapter 16.
Objects that are used specifically for handling remote procedure calls implement
a number of specialized interfaces themselves as we'll see in
Chapter 9.
The bottom line is that you decide what functionality the object should have and implement the interface that represents that functionality. In some cases there are no standard interfaces that contain the desired functionality in which case you will want to design a custom interface. You may need to provide for remoting that interface as described in Chapter 9.
[Footnote 37]
The following chapters that discuss COM clients and servers use
as an example an object class designed to render ASCII text information from
text stored in files.
This object class is called ``TextRender''
and it has a CLSID of
{12345678-ABCD-1234-5678-9ABCDEF00000}
[Footnote 37]
defined as the symbol
CLSID_TextRender
in some include file.
Note again that an object class does not
have to have an associated CLSID.
This example has one so we can use it to
demonstrate COM clients and servers in
Chapter 7
and
Chapter 8.
[Footnote 38]
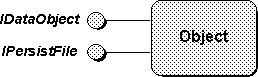
The
TextRender
object can read and write text
to and from a file, and so implements the
IPersistFile()
interface to support those operations.
An object can be initialized (see Section
Section 7.2) with the contents of a file through
IPersistFile::Load().
The object class also supports rendering the
text data into straight text as well as graphically as metafiles and bitmaps.
Rendering capabilities are handled through the
IDataObject()
interface, and
IDataObject::SetData()
when given text forms
a second initializing function.
[Footnote 38]
The operation of
TextRender
objects is illustrated in
Figure 4-7.
Section Section 8.8 will show how we might implement this object when another object that provides some the desired functionality is available for reuse. But for now, we want to see how to implement this object on its own.
There are two different strategies for implementing interfaces on an object: multiple inheritance and interface containment. Which method works best for you depends first of all on your language of choice (languages that don't have an inheritance notion cannot support multiple inheritance, obviously) but if you are implementing an object in C++, which is a common occurrence, your choice depends on the object design itself.
Multiple inheritance works best for most objects. Declaring an object in this manner might appear as follows:
classCTextRender(): publicIDataObject(), publicIPersistFile(){ private: ULONG m_cRef; //Reference Count char * m_pszText; //Pointer to allocated text ULONG m_cchText; //Number of characters in m_pszText //Other internal member functions here public: [Constructor, Destructor] /* * We must override all interface member functions we * inherit to create an instantiatable class. */ //IUnknown members shared betweenIDataObject()andIPersistFile()HRESULT QueryInterface(REFIID iid, void ** ppv); ULONG AddRef(void); ULONG Release(void); //IDataObject Members overrides HRESULT GetData(FORAMTETC *pFE, STGMEDIUM *pSTM); [Other members] ... //IPersistFile Member overrides HRESULT Load(char * pszFile, DWORD grfMode); [Other members] ... };
This object class inherits from the interfaces it wishes to implement,
declares whatever variables are necessary for maintaining the object state,
and overrides all the member functions of all inherited interfaces, remembering
to include the
IUnknown()
members that are present in all
other interfaces.
The implementation of the single
QueryInterface()
function of this object would use typecasts to return pointers
to different vtbl pointers:
HRESULT CTextRender::QueryInterface(REFIID iid, void ** ppv) {
*ppv=NULL;
//This code assumes an overloaded == operator for GUIDs exists
if (IID_IUnknown==iid)
*ppv=(void *)(IUnknown() *)this;
if (IID_IPersitFile==iid)
*ppv=(void *)(IPersistFile() *)this;
if (IID_IDataObject==iid)
*ppv=(void *)(IDataObject() *)this;
if (NULL==*ppv)
return E_NOINTERFACE; //iid not supported.
// Any call to anyone's AddRef() is our own, so we can just call that directly
AddRef();
return NOERROR;
}
This technique has the advantage that all the implementation of all
interfaces is gathered together in the same object and all functions have
quick and direct access to all the other members of this object.
In addition,
there only needs to be one implementation of the
IUnknown()
members.
However, when we deal with aggregation in
Chapter 8
we
will see how an object
might need a separate implementation of
IUnknown()
by itself.
There are at times reasons why you may not want to use multiple inheritance
for an object implementation.
First, you may not be using C++.
That aside,
you may want to individually track reference counts on each interface separate
from the overall object for debugging or for resource management purposes--reference
counting is from a client perspective an interface-specific operation.
This
can uncover problems in a client you might also be developing, exposing situations
where the client is calling
AddRef()
through one interface
but matching it with a
Release()
call through a different
interface.
The third reason that you would use a different method of implementation
is when you have two interfaces with the same member function names with possibly
identical function signatures or when you want to avoid function overloading.
For example, if you wanted to implement
IPersistFile(),
IPersistStorage(), and
IPersistStream()
on an
object, you would have to write overloaded functions for the Load and Save
members of each which might get confusing.
Worse, if two interface designers
should happen to define interfaces that have like-named methods with like
parameter lists but incompatible semantics, such overloading isn't even possible:
two separate functions need to be implemented, but C++ unifies the two method
definitions.
Note that as in general interfaces may be defined by independent
parties that do not communicate with each other, such situations are inevitable.
The other implementation method is to use ``interface implementations''
which are separate C++ objects that each inherit from and implement one interface.
The real object itself singly inherits from
IUnknown()
and maintains (or contains) pointers to each interface implementation that
it creates on initialization.
This keeps all the interfaces separate and distinct.
An example of code that uses the containment policy follows:
class CImpIPersistFile : publicIPersistFile(){ private: ULONG m_cRef; //Interface reference count for debugging //``Backpointer'' to the actual object. classCTextRender()* m_pObj; public: [Constructor, Destructor] //IUnknown members forIPersistFile()HRESULT QueryInterface(REFIID iid, void ** ppv); ULONG AddRef(void); ULONG Release(void); //IPersistFile Member overrides HRESULT Load(char * pszFile, DWORD grfMode); [Other members] ... } class CImpIDataObject : publicIDataObject()private: ULONG m_cRef; //Interface reference count for debugging //``Backpointer'' to the actual object. classCTextRender()* m_pObj; public: [Constructor, Destructor] //IUnknown members forIDataObject()HRESULT QueryInterface(REFIID iid, void ** ppv); ULONG AddRef(void); ULONG Release(void); //IPersistFile Member overrides HRESULT GetData(FORMATETC *pFE,STGMEDIUM *pSTM); [Other members] ... } classCTextRender(): publicIUnknown(){ friend class CImpIDataObject; friend class CImpIPersistFile; private: ULONG m_cRef; //Reference Count char * m_pszText; //Pointer to allocated text ULONG m_cchText; //Number of characters in m_pszText //Contained interface implementations CImpIPersistFile * m_pImpIPersistFile; CImpIDataObject * m_pImpIDataObject; //Other internal member functions here public: [Constructor, Destructor] HRESULT QueryInterface(REFIID iid, void ** ppv); ULONG AddRef(void); ULONG Release(void); };
In this technique, each interface implementation must maintain a backpointer
to the real object in order to access that object's variables (normally this
is passed in the interface implementation constructor).
This may require a
friend relationship (in C++) between the object classes; alternatively, these
friend classes can be implemented as nested classes in
CTextRender().
Notice that the
IUnknown()
member functions of each
interface implementation do not need to do anything more than delegate directly
to the
IUnknown()
functions implemented on the
CTextRender()
object.
The implementation of
QueryInterface()
on the main object would appear as follows:
HRESULT CTextRender::QueryInterface(REFIID iid, void ** ppv)
{
*ppv=NULL;
//This code assumes an overloaded == operator for GUIDs exists
if (IID_IUnknown==iid)
*ppv=(void *)(IUnknown() *)this;
if (IID_IPersitFile==iid)
*ppv=(void *)(IPersistFile() *)m_pImpIPersistFile;
if (IID_IDataObject==iid)
*ppv=(void *)(IDataObject() *)m_pImpIDataObject;
if (NULL==*ppv)
return E_NOINTERFACE; //iid not supported.
//Call AddRef() through the returned interface
((IUnknown() *)ppv)->AddRef();
return NOERROR;
}
This sort of delegation structure makes it very easy to redirect each
interface's
IUnknown()
members to some other
IUnknown(), which is necessary in supporting aggregation as explained
in
Chapter 8.
But overall the implementation is not much different
than multiple inheritance and both methods work equally well.
Containment
of interface implementation is more easily translatable into C where classes
simply become equivalent structures, if for any reason such readability is
desirable (such as making the source code more comprehensible to C programmers
who do not know C++ and do not understand multiple inheritance).
In the end
it really all depends upon your preferences and has no significant impact
on performance or development.
The
IUnknown()
interface lets clients get pointers
to other interfaces on a given object through the
QueryInterface()
method, and manage the existence of the object through the
IUnknown::AddRef()
and
IUnknown::Release()
methods.
All other COM interfaces are inherited, directly or indirectly, from
IUnknown().
Therefore, the three methods in
IUnknown()
are the first entries in the VTable for every interface.
You must implement
IUnknown()
as part of every interface.
If you are using C++ multiple inheritance to implement multiple interfaces,
the various interfaces can share one implementation of
IUnknown().
If you are using nested classes to implement multiple interfaces,
you must implement
IUnknown()
once for each interface you
implement.
Use
IUnknown()
methods to switch between interfaces
on an object, add references, and release objects.
IUnknown Methods
|
Description
|
QueryInterface()
|
Returns pointers to supported interfaces. |
AddRef()
|
Increments reference count. |
Release()
|
Decrements reference count. |
IUnknown::AddRef()IUnknown::AddRef()
method increments the reference
count for an interface on
an object.
It should be called for every new copy of a pointer to an interface
on a given
object.
#include <unknwn.h>
ULONG AddRef((
void
);
Objects use a reference counting mechanism to ensure that the lifetime
of the
object includes the lifetime of references to it.
You use
IUnknown::AddRef()
to stabilize a copy of an interface
pointer.
It can
also be called when the life of a cloned pointer must extend beyond the
lifetime of the original pointer.
The cloned pointer must be released by
calling
IUnknown::Release().
Objects must be able to maintain (231)-1
outstanding pointer
references.
Therefore, the internal reference counter that
IUnknown::AddRef()
maintains must be a 32-bit unsigned
integer.
Call this function for every new copy of an interface pointer that you
make.
For example, if you are passing a copy of a pointer back from a function,
you must call
IUnknown::AddRef()
on that pointer.
You must
also call
IUnknown::AddRef()
on a pointer before passing it as an
in-out parameter
to a function; the function will call
IUnknown::Release()
before copying
the out-value on top of it.
Returns an integer from 1 to n, the value of the new reference count. This information is meant to be used for diagnostic/testing purposes only, because, in certain situations, the value may be unstable.
IUnknown::QueryInterface()IUnknown::AddRef()
on the pointer it returns.
#include <unknwn.h>
HRESULT QueryInterface((
REFIID iid,
void ** ppvObject
);
The
QueryInterface()
method gives a client access
to other interfaces on
an object.
For any one object, a specific query for the
IUnknown()
interface
on any of the object's interfaces must always return the same pointer value.
This allows a client to determine whether two pointers point to the same
component by calling
QueryInterface()
on both and comparing
the results.
It is specifically not the case that queries for interfaces (even the same
interface through the same pointer) must return the same pointer value.
There are four requirements for implementations of
QueryInterface()
(In
these cases, ``must succeed'' means ``must succeed barring catastrophic failure.''):
The set of interfaces accessible on an object through
IUnknown::QueryInterface()
must be static, not dynamic.
This means that if
a call to
QueryInterface()
for a pointer to a specified
interface succeeds
the first time, it must succeed again, and if it fails the first time, it
must
fail on all subsequent queries.
It must be symmetric--if a client holds a pointer to an interface on an object, and queries for that interface, the call must succeed.
It must be reflexive--if a client holding a pointer to one interface queries successfully for another, a query through the obtained pointer for the first interface must succeed.
It must be transitive--if a client holding a pointer to one interface queries successfully for a second, and through that pointer queries successfully for a third interface, a query for the first interface through the pointer for the third interface must succeed.
[in] Identifier of the interface being requested.
[out] Indirectly points to the interface specified in
iid.
If the object does not support the interface specified in
iid,
*ppvObject
is set
to
NULL.
S_OK
if the interface is supported,
E_NOINTERFACE
if not.
IUnknown::Release()
#include <unknwn.h>
ULONG Release((
void
);
If
IUnknown::AddRef()
has been called on this object's
interface
n
times and this is the
n+1th
call to
IUnknown::Release(), the implementation of
IUnknown::AddRef()
must cause the interface pointer to free itself.
When the released pointer is the only existing reference to an object (whether
the object supports single or multiple interfaces), the implementation must
free the object.
Aggregation of objects restricts the ability to recover interface pointers.
Call this function when you no longer need to use an interface pointer.
If you are writing a function that takes an in-out parameter, call
IUnknown::Release()
on the pointer you are passing in before copying
the out-value on top of it.
Returns the resulting value of the reference count, which is used for diagnostic/testing purposes only. If you need to know that resources have been freed, use an interface with higher-level semantics.
The
IProvideClassInfo()
interface provides a single
method for accessing the type information for an object's coclass entry in
its type library.
Implement this interface on any object that can provide type information
for its entire class, that is, the
coclass
entry in the
type library.
Use this interface to access the
coclass
type information
for an object.
|
Description
|
QueryInterface()
|
Returns pointers to supported interfaces. |
AddRef()
|
Increments reference count. |
Release()
|
Decrements reference count. |
|
Description
|
GetClassInfo
|
Returns the
ITypeInfo()
interface for
the object's coclass type information. |
IProvideClassInfo::GetClassInfo()ITypeInfo()
interface
for the object's type information.
The type information for an object corresponds
to the object's
coclass
entry in a type library.
#include <ocidl.h>
HRESULT GetClassInfo(
ITypeInfo ** ppTI
);
The caller is responsible for calling
ITypeInfo::Release()
when the returned interface pointer is no longer needed.
This method must call
ITypeInfo::AddRef()
before
returning.
If the
object loads the type information from a type library, the type library itself
will call
AddRef()
in creating the pointer.
Because the caller cannot specify a locale identifier (LCID) when calling
this
method, this method must assume the neutral language, that is,
LANGID_NEUTRAL,
and use this value to determine what locale-specific type information to
return.
This method must be implemented;
E_NOTIMPL
is not
an acceptable return value.
[out] Indirect pointer to object's type information.
The caller
is
responsible for calling
ITypeInfo::Release()
on the returned
pointer
if this method returns successfully.
This method supports the standard return values
E_OUTOFMEMORY
and
E_UNEXPECTED, as well as the following:
S_OKThe type information was successfully returned.
E_POINTERThe address in
ppTI
is not valid.
For
example,
it may be
NULL.
The
IProvideClassInfo2()
interface is a simple extension
to
IProvideClassInfo()
for the purpose of making it quick and easy to retrieve an object's outgoing
interface
IID for its default event set.
The mechanism, the added
GetGUID()
method, is extensible
for other types of GUIDs as well.
An object implements this interface to provide type information for its outgoing interfaces.
Call the method in this interface to obtain type information on an object's outgoing interfaces.
IUnknown Methods
|
Description
|
QueryInterface()
|
Returns pointers to supported interfaces. |
AddRef()
|
Increments reference count. |
Release()
|
Decrements reference count. |
IProvideClassInfo
Method
|
Description
|
GetClassInfo
|
Returns the
ITypeInfo()
interface for
the object's
coclass
type information. |
|
Description
|
GetGUID
|
Returns the GUID for the object's outgoing IID for its default event set. |
IProvideClassInfo2::GetGUID()GUIDKIND.
Additional flags can be defined at
a later time and will be recognized by an
IProvideClassInfo2()
implementation.
#include <ocidl.h>
HRESULT GetGUID(
DWORD dwGuidKind,
GUID * pGUID
);
E_NOTIMPL
is not a valid return code since it would
be pointless to
implement this interface without implementing this method.
E_INVALIDARG
is not valid when
dwGuidKind
is
GUIDKIND_DEFAULT_SOURCE_DISP_IID.
[in] Specifies the GUID desired on return.
This parameter
takes a value
from the
GUIDKIND
enumeration.
[out] Pointer to the caller's variable in which to store the GUID associated with dwGuidKind.
S_OKThe GUID was successfully returned in *pGUID.
E_POINTERThe address in
pGUID
is not valid (such
as
NULL).
E_UNEXPECTEDAn unknown error occurred.
E_INVALIDARGThe dwGuidKind value does not correspond to a supported GUID kind.
The
GUIDKIND
enumeration values are flags used to
specify the kind of
information requested from an object in the
IProvideClassInfo2().
typedef enum tagGUIDKIND
{
GUIDKIND_DEFAULT_SOURCE_DISP_IID = 1,
} GUIDKIND;
GUIDKIND_DEFAULT_SOURCE_DISP_IIDThe interface identifier (IID) of the object's outgoing
dispinterface,
labeled [source, default].
The outgoing interface in question must be derived
from
IDispatch().
IProvideClassInfo2()