The directory is a collection of information about a set of objects.
Objects are referenced in entries of the directory service. Entries
that are structured recursively in the system are called directories.
Information in directory service entries can be used for purposes such as
describing resources, location of the referenced resources, and for discovery
of operations on objects.
While it is conceivable that a directory service may be built on a general purpose database, the directory service is not conceptually such a database. The distinct characteristics of the directory service information model are best described by the following assumptions:
This document, which is the specification of the directory service information model, assumes the existence of the above generic characteristics. However, the specification may be applied to a wide variety of services, ranging from general purpose directory services to very specialised resource managers. Information storage in logical databases is common to all of these, but this specification does not specify the properties (such as insertion and retrieval speed, partitioning, replication) of these information bases. The definition of these properties is subject to service-specific specifications.
The directory service specifications define the possible operations on directory entries. However, the most rudimentary common operations, supported by every directory service, are read, modify, create and delete (on entries and attributes).
A name is a string of characters that refers to an object. Directory entities are identified by names. A name resolves a directory entry unambiguously, but does not provide for uniqueness. Multiple names can reference the same entry, and names can be aliases or soft links. An alias expresses an alternative name of an object, representing a possibly different hierarchical relationship.
The rules and conventions for the DCE-defined compound names are specified in
Components may represent a single physical directory or a leaf object;
they may be typed or untyped; or they may represent complex structures
such as attribute-based schemes. The present document only specifies
syntax and semantic rules for components in the global and cell name
spaces, as outlined in
The uniqueness of a given directory entry may also be expressed by an
identifier. Identifiers are unique in a given context. Contexts are
determined by the directory service and the type of identifier used. This
document specifies two types of identifiers: the OSI Object Identifier
(OID), and the Universal Unique Identifier (UUID).
OIDs (object identifier) are obtained from a hierarchy of allocation authorities, the highest being the International Organisation for Standardization (ISO) and the International Telegraph and Telephone Consultative Committee (CCITT). The printable format of object identifiers is a string of . (dot) separated digits (see also the ASN.1 standard).
The UUID (universal unique identifier) is a fixed size identifier which is guaranteed to be unique across both space and time. A further specification of the UUID can be found in the DCE Remote Procedure Call specification.
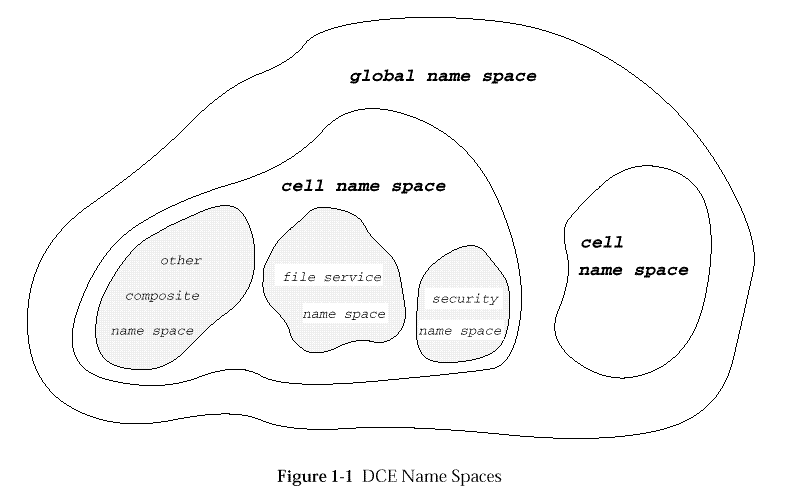
The DCE directory information model consists of a set of composite name
spaces. Composite name spaces are linked together in a hierarchical order.
This document specifies two types of composite name spaces: the global
name space and the cell name space (see
Cell name spaces, then, are either subordinates of the global
name space or of other cell name spaces. The root and attributes
of the top-level cell name space are catalogued in the global name space.
The root and attributes of child cells are catalogued in the parent
cell name space. Either parent cell name spaces or child cell name
spaces can be superordinates for other composite name spaces (see
The entities in both the global and the cell name spaces are hierarchically structured, and together comprise an inverse tree of nodes. These name spaces represent an acyclic directed graph: each entity has exactly one parent at any moment, and no entity is a descendent of its own descendents. This architecture does not impose the structural rules applied to other composite name spaces.
The syntax and semantics of the global name space are in accordance with the standard specifications of these directory services. The conformance requirements are specified in this document.
The cell name space defines three different types of entries1:
Directories can be empty, not containing any references to subordinate entries.
Directory entries do not have parent pointers to soft link entries (the directory name to which a parent pointer refers is a fully-qualified global name).
To prevent cycles in the tree structure of the cell name space, a directory must not be a child of any of its descendents.
The contents of every cell name space entry consist of a set of attributes and their associated values.
Attributes are of two types:
From the point of view of usage, attributes can generally be divided into two categories:
The set of these categories of attributes, and their applicability to distinct entries (directory, object, soft link), is service and implementation-specific.
An attribute is identified by an attribute identifier (sometimes referred to as attribute name), which distinguishes it from other attributes. An attribute of a given name can have only one attribute value syntax (data type); it is not possible for a single-valued attribute and a set-valued attribute to have the same name at the same time. Every attribute name has an OID (Object Identifier) associated with it to ensure uniqueness among attributes.
Name spaces are linked by next naming system pointers. Next naming system pointers accomplish the concept of obtaining the "next name space" reference.
The protocols used to resolve the next name space reference pointers are not specified in this document (though it is anticipated that such protocols will be supported in the future).
The canonical string representation of DCE names does not make
a syntactical distinction between atomic name and compound name
separators for the cell name space (both use / (slash) as the
separator; see
To avoid these ambiguities in a composite name, it is recommended that next
naming system pointers always be object (leaf) entries in the cell
name space, which explicitly associates a name to the name space pointer.
These explicit next naming system pointers are called junctions.
This specification only supports junctions in the cell name space.
As defined in
If the rightmost component of a name that resides in the cell name space is not the rightmost component of that composite name, the resolved entry represents a junction. The content of the residual compound names of the composite name is opaque to the cell name space directory service.
Cell name space junctions to subordinate name spaces are catalogued (that is, have a name) in the cell name space. Pointers to and information about the resource manager of a subordinate composite name space are registered in application-specific attributes of the junction entry.
The junction entry represents both the entry in the cell name space and the object of the subordinate name space that this junction is bound to. This bound object is usually the root of that subordinate name space.
This document does not specify how the cell name space junction entry and the bound object can both be unambiguously accessed. Applications may provide programming interfaces that disambiguate the access to these entities that are referred to by the same name. The ACL Editor, for instance, defines a flag in the sec_acl_bind () interface that allows applications to determine the target of the operation (the ACL of the cell name space entry or the ACL of the protected object of a server-supported name space) - see the DCE Security Services specification.
A DCE cell is an administrative and security domain within the cell name space. Servers of the Cell Directory Service (CDS) and security authorities are instantiated on a cell-wide basis.
A cell is typically a group of users, systems and resources that are
centred around a common purpose and which share common DCE services.
A minimum cell configuration includes one CDS, one Security Service
and one Time Service.
The membership of a cell is determined on a per host basis. How a host obtains information about its cell identity is implementation-specific; for example, the cell name may be stored in a local (host-specific) configuration file. The local cell is the cell defining the environment of the initial user's login session.
This document does not specify the particular semantics and syntax
rules for composite name spaces other than the global and the cell
name space. However, the DCE Security Services specification specifies the security name space,
and the DCE File Services specification specifies the file service name space (also
called filespace). Both name spaces are subordinates of the
cell name space, and are integrated through junctions.
Within each cell, the actual names for these junctions are not determined by the architecture; they are indirectly identified in the /.:/cell-profile profile entry as having the name associated with the UUID of the junction. However, the recommended names are /.:/sec for the security name space, and /.:/fs for the file service name space.
Other name service or resource manager implementations may be integrated into the DCE name space, in accordance with the rules outlined in this specification.
Names defined by this syntax consist of strings of characters
(elements of a character set). The minimal set of valid characters
is defined in the Portable Character Set (PCS) for the
DCE directory information system.
The PCS for directory services defines the semantics of names, rather than the actual visual or encoded characters. For example, it specifies that a character with the semantic of backslash (that is, the \ character) must be supported, although in some fonts the backslash glyph may have been replaced with another glyph. Note that a similarity in visual appearance between two glyphs does not necessarily mean that they are in fact the same semantic character.
The syntax applied when interpreting a name is dependent on whether a component refers to an entry in the global name space, the cell name space, or another composite name space. The common characteristics of the syntax are specified as follows:
The characters / (slash) and \ (backslash) have special properties, and are
called the metacharacters of the syntax. Additional distinct
metacharacters for both the global and the cell name space are defined in
respective sections of this document. Their special properties can be
cancelled by preceding them with a \ (backslash), an operation called
escaping. The sequence of characters consisting of a \ (backslash)
followed by an ordinary character (that is, by a non-metacharacter) is
reserved, and may be specified in subsequent versions of the following
syntax.
The notations used are as follows:
The DCE name syntax is as follows:
PCS ::= { Portable Character Set }
SimpleChar ::= { Subset of symbols from Portable Character Set,
intersection of characters supported by
GDS, DNS and CDS -
a to z, A to Z, 0 to 9, "-" }
AlphaChar ::= { a to z, A to Z }
NumChar ::= 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9
WildChar ::= ? | *
EscapeChar ::= \
ComponentSep ::= /
DotSep ::= .
Quote ::= " | '
GlobalContext ::= <ComponentSep>+ "..."
CellContext ::= <ComponentSep>+ ".:"
FileContext ::= <ComponentSep>+ ":"
DNSChar ::= <SimpleChar>
DNSAtomicName ::= <DNSChar>+
DNSComponent ::= <DNSAtomicName> {<DotSep> <DNSAtomicName>}+
DNSCompoundName ::= <DNSComponent>
GDSAVASep ::= =
GDSMultiAVASep ::= ,
GDSChar ::= <SimpleChar> | <DotSep>
| " " | ` | ( | ) | + | : | ?
GDSAttrType ::= {<AlphaChar> {<AlphaChar> | <NumChar>}*}
| {<NumChar>+ {<DotSep> <NumChar>+}*}
GDSAttrValue ::= <GDSChar>+
| {<GDSChar>* <EscapeChar> <PCS> <GDSChar>*}+
| <Quote> <PCS>+ <Quote>
GDSAVA ::= <GDSAttrType> <GDSAVASep> <GDSAttrValue>
GDSAtomicName ::= <GDSAVA> {<GDSMultiAVASep> <GDSAVA>}*
GDSComponent ::= <GDSAtomicName>
GDSCompoundName ::= <GDSComponent> {<ComponentSep>+
<GDSComponent>}*
GlobalCompoundName ::= <DNSCompoundName> | <GDSCompoundName>
GlobalCompositeName ::= <GlobalContext> <ComponentSep>+
<GlobalCompoundName> | <GlobalContext>
<ComponentSep>*
CDSChar ::= <GDSChar> | <GDSMultiAVASep> | ! | # | $ | %
| & | ; | < | > | [ | ] | ^ | _ | { | }
| "|" | ~ | *
CDSAtomicName ::= {<CDSChar> | <GDSAVASep>}+
| {{<CDSChar> | <GDSAVASep>}* <EscapeChar> <PCS>
{<CDSChar> | <GDSAVASep>}*}+
| <Quote> <PCS>+ <Quote>
CDSFirstComponent ::= <CDSChar>+
| {<CDSChar>* <EscapeChar> <PCS> <CDSChar>*}+
| <Quote> <PCS>+ <Quote>
CDSComponent ::= <CDSAtomicName> | <CDSFirstComponent>
CDSCompoundName ::= <CDSFirstComponent>
{<ComponentSep>+ <CDSAtomicName>}*
CellCompositeName ::= <CellContext> <ComponentSep>+ <CDSCompoundName>
AtomicName ::= <SimpleChar>+
| {<SimpleChar>* <EscapeChar> <PCS>
<SimpleChar>*}+
| <Quote> <PCS>+ <Quote>
CompoundName ::= <AtomicName> {<ComponentSep>+ <AtomicName>}*
FullName ::= <GlobalCompositeName>
{<ComponentSep>+ <CDSCompoundName>}*
| <GlobalCompositeName>
<ComponentSep>+ <CDSCompoundName>
{<ComponentSep>+ <CompoundName>}*
CellRelativeName ::= <CDSCompoundName>
{<ComponentSep>+ <CompoundName>}*
FileName ::= <FileContext> <ComponentSep>+ <CompoundName>
This section defines the policies that are applied to
composite names in DCE.
A DCE composite name is structured as a left-to-right ordered set of compound names, and a compound name is structured as a left-to-right ordered set of components. This ordering is intended to correspond to the top-to-bottom (parent/child, superordinate/subordinate, more-significant/less-significant, big-endian/little-endian) lineage of the named object.
These compound names represent entries in their associated name spaces.
Multiple compound names and components of compound names are separated
by / (slash) characters (BNF element <ComponentSep>).
Initial contexts are special cases of reserved component names. They are logical entities describing the name context; they do not represent actual entries in the directory services. The initial contexts are separated from the remainder of a composite name by a / (slash). The three defined initial contexts are:
A fully-qualified global name (BNF element <FullName>) is a DCE composite name with the global root at the top (left). Hence, the fully-qualified global name is a single path in a hierarchically structured rooted tree of name spaces. The name of the global root is represented by the character string /.... Fully-qualified global names must begin with the substring /....
In names specified from the global root, the name for the cell root is always placed to the left of the rest of the cell name, as a prefix to the composite name (BNF elements <CellCompositeName> and <CellRelativeName>).
Similarly to the cell root, the file context is a shorthand form for the cell relative name of the local distributed file service. The name of the file context is /:, which resolves to /.:/<string> (where the recommended name for <string> is fs).
The name syntax defines the rules for names that are to be presented to the
name service interfaces. Before a name is processed by a name service, and
before any of the matching rules specified in
Canonicalisation is performed according to the following rules:
The , (comma) and = (equal sign) characters are metacharacters in the
global name space syntax. As with the other valid metacharacter (that is,
the / (slash) character), these may be escaped by a preceding \ (backslash)
character. Escaping the backslash character itself (that is, having multiple
contiguous occurrences of \) within the global compound name is reserved
for future use, and is not allowed by the current version of the specification.
If the first component of the global compound name (the descendent of the global root /...) is not identified as an X.500 name (that is, it does not contain a = (equal sign)), and if it contains at least one . (dot) character, it is considered to be a DNS name. Names that are not identified as being either X.500 or DNS are not specified (BNF element <GlobalCompositeName>). Implementations may reject these as unsupported.
An X.500 global compound name (BNF element <GDSCompoundName>) may consist of arbitrarily many components. Every name component represents a relative distinguished name (RDN) according to the X.500 rules.
Every subcomponent (BNF element <GDSComponent>) must contain exactly
one = (equal sign) character. The substring preceding the = is called the
type, and the substring following is called the value. Types
and values are non-empty character strings, containing no unescaped
metacharacters, and may be arbitrarily long. Since types and values cannot
be empty, multiple successive = (equal sign) characters are not allowed.
Similarly, components cannot end with an equal sign. In other words, within
a component, the number of unescaped equal signs matches exactly the number
of comma characters plus 1.
Two global compound names which match each other according to the following rules are interpreted to always name the same object3:
The global compound name in DNS consists of exactly one component, which follows the global root prefix. The full DNS name, formed in accordance with its syntax rules (that is, consisting of domains separated by . (dot) characters, in little-endian ordering, case insensitive, and so on), is represented in this single component (BNF elements <DNSCompoundName> and <GlobalCompoundName>, separated by a / (slash) character).
A global DNS name (BNF element <DNSComponent>) referencing a cell name space must contain at least one . (dot) character (that is, must be more than one level deep), and may consist of multiple domain names, each separated by a . (dot) character.
Two global compound names which match one another according to the following rule are interpreted to always name the same object:
The * (asterisk) and ? (question mark) characters are metacharacters (BNF element <WildChar>) for the cell name space syntax. Any valid metacharacter may be escaped by preceding it with a \ (backslash) character.
A component consists of a character string representing the (untyped) atomic name of an entry. The ordering of components (left-to-right) represents the hierarchy (top-to-bottom) of the cell name space organisation (BNF elements <CDSComponent> and <CDSCompoundName>).
The first component (BNF element <CDSFirstComponent>) in the cell compound name must not contain the = (equal sign) character, unless it is escaped by a preceding \ (backslash) metacharacter.
Two cell compound names which match one another according to the following rules are interpreted to always name the same object:
In all cases, the cell context (/.:) resolves to the fully-qualified
global name of the current cell, whether that cell is a parent
cell (registered in the global name space) or a child cell (registered
in the cell name space of the parent cell). Thus, when resolved
from within a child cell, the cell context (/.:) refers to the root
of the child not to the root of the parent.
To conform to this document, implementations must meet the following requirements:
Please note that the html version of this specification may contain formatting aberrations. The definitive version is available as an electronic publication on CD-ROM from The Open Group.
| Contents | Next section | Index |