5. Existing Ecosystems Thinking and Practice
“Let our advance worrying become advance thinking and planning.” — Winston Churchill
Now that the basics of how we might begin to address the challenge of hyper-enterprise systems have been covered, it is time to summarize what has already been done to establish practice in this approximate area.
5.1. Social Machines
Here, we essentially find two categories of capability, with the first being somewhat more academic than the other. This is the study of social machines [124], which sets out to understand how group-level IT systems involving human communication (like those found on social media) apply the technology inherent to their immediate surroundings. This is akin to the swarm-type intelligence seen in a colony of ants or a murmuration of starlings, only this time supercharged by the digital compute capabilities brought by every participant involved.
This is distributed computing at its most potent, yet, unbelievably, no explicit hierarchy of control or centrality of management is present or needed. Instead, the crowd simply decides en masse as consensus emerges, and this is what gives social machines their power.
Although this might sound like science fiction, it most definitely is not. If you were to look at how governments were overthrown during the Arab Spring,[1] for instance, you will see an example of social machines at their best. This is shown well in an amazing YouTube™ video [125] by André Panisson, which brings the power of social machines starkly to life. In it, you will see an animated graph of Twitter conversations bubbling over as dissatisfaction against the then Egyptian government reaches its peak. What is striking in this video is that, although clusters of interest are clear around a few nodes (representing key social influencers or revolution ringleaders in this case) in the graph, none show up as any point of obvious focus. In other words, no single point of instigation stands out, which is what frustrated the authorities in their attempts to quell the uprising, and ultimately led to the government’s downfall in 2011.

This type of evolving consensus amongst social groups is now well understood and should not be underestimated as we become interested in Ecosystems Architecture. That is because all IT systems exist in one way or another to serve human need. Technology can never exist purely to serve technology, as it were, although that might not always be clear from surface inspection. No, at the root of all that drives every single IT system will be found some human want, whether that be to lessen a workload, generate profit, pass on news, or whatever. IT systems exist to serve us and not the other way around. For that reason, if a shift in human need occurs, it will sooner or later change the demand for IT, the technical requirements in hand and the nature of the solutions we as IT architects are expected to build and maintain. Furthermore, given that we are inherently a social species, the likelihood is that that change in demand will come from shifting consensus, rather than lightning strikes of individual ingenuity, creativity, or compulsion. As with the events of the Arab Spring, the group may well decide, rather than any individual, authority, or organization. Obviously, there are, and will be, exceptions to that rule, but as general guidance, history speaks to its related wisdom.
This is the unfolding world in which we live and work. It is essentially the backdrop to the whole of human existence, and that includes the domains of commerce, politics, religion, and so on. For the first time in human history then, with the Arab Spring, we had amassed sufficiently advanced statistical techniques, professional competence, and adequate computing support to help analyze the social mechanics in play when its various rebellions broke out. In truth, however, academics and practice leaders had been working on the ideas behind those mechanics for some time. What they saw then, was an unusually speedy alignment of opinion played out across the Web’s relatively new social platforms. For the first time, they allowed the connected consciousness of whole populi to be recorded and analyzed in detail. That essentially allowed us to bottle the genie and convince it to give up its spells. In that way we now mostly know how the environmental conditions and human need worked together to disrupt and drive out change. No wonder then that world-class academic institutes, like Media Lab at MIT [127] are becoming increasingly interested. There, they are driving research to “develop data science methods — based primarily on natural language processing, network science, and machine learning — to map and analyze communication and interaction in human networks, and to design tools and field experiments to investigate new forms of social connectivity”.
Likewise, several universities in the UK and US are also deeply interested in the idea of social machines. For instance, the SOCIAM program [128] [129] [130] [131] [132] is spread across Southampton, Edinburgh, and Oxford universities and has “set out to explore how existing and emerging social media platforms are changing the relationship between people and computers”.
All of this is great for the theory behind Ecosystems Architecture, but unfortunately, it is not all good news. For all that the ideas behind social machines can help us understand the wherewithal behind hyper-enterprise change, they add little or nothing when it come to the practicalities of actual IT delivery.
This is where our second example of existing thinking/practice comes in.
5.2. Gaia-X
Having come this far in the discussion, some things should be clear about hyper-enterprise architectures. Sure, both they and their surrounding environments change over time; sure, they can be large and complex; and sure, they can demand some pretty abstract thinking to understand them properly. But how might that help when it comes to making the IT involved actually work?
For instance, it is one thing to understand the need to update an interface between two nodes in an ecosystem, as, for whatever reason, one or both of those nodes undergoes change. It is also fine to understand that similar nodes might lie within reach — meaning that either or both ends of the integrated connection might be technically replaced to achieve the update required. But how might you actually go about the work necessary to make that happen in a reasonable way. That is, in the face of all relevant constraints and considerations? For instance, it might feel all right to think of replacing a legacy system with a more contemporary equivalent, like, say, a containerized service deployed on the latest whizzy cloud. But what if that system talks using EBCDIC-based[2] EDI[3] flat files, whereas its replacement via some dialect of ASCII-based[4] JSON squirted out through some esoteric REST API?[5] Is that feasible? Probably, but at what cost and with how much delay? These and a myriad of other practical questions must be answered before any practical progress can be made.
As IT architects, we de-risk situations involving challenges like this by talking in terms of standards, patterns, methodologies, methods, and so on. These stoically set out to communicate guidelines in terms of best practice and/or accepted norms, and in ways that can be easily understood and adopted. In essence, they try to establish safe and common ground based on what we know to be tried, tested, and true. This is often strengthened through the support of independent standards bodies consisting of recognized experts and the like. Similarly, it is not unheard of for bodies to spring up outside the professional standards community, with specific aims to level the playing field, as and when major shifts in technology or usage patterns occur. With that in mind, the Gaia-X [133] association was established in the summer of 2019 to overcome the interoperability challenges associated with real-world hyper-enterprise IT systems. Gaia-X brings together industry, politics, government, research, academic, technical, and scientific leaders from Europe and beyond to collaborate on the next generation of trusted data infrastructures. It therefore represents:
“…a European initiative that aims to create a secure and trustworthy data infrastructure for Europe, which will facilitate the exchange and sharing of data between companies and individuals. It was set up as a joint effort by the European Union and the German and French governments, and with the goal of creating a secure and sovereign data infrastructure for Europe that is based on European values and principles. The initiative was launched in 2019, and since then, it has grown to include more than 300 members from different sectors, including industry, academia, and government.”
The base values that Gaia-X seeks to promote include:
“…transparency, openness, and interoperability, while also ensuring that data remains under the control of the owner.”
Gaia-X’s goal is therefore to “establish an ecosystem, whereby data is shared and made available in a trustworthy environment” and to give “control back to the users by retaining sovereignty over their data.” This will, in Gaia-X’s words “not be a cloud. It is a federated system linking many cloud service providers and users together in a transparent environment that will drive the European data economy of tomorrow.” It therefore aims to help establish decentralized IT architectures based on shared European values and by specifically focusing on the advantages associated with data-sharing infrastructure and the idea of data as a common shareable resource [135] [136].
The federated data infrastructure and data-sharing frameworks developed by Gaia-X have already been applied to several vertical ecosystems [137] across sectors including automotive, energy, and agriculture [138], and although in its current form it focuses on Europe’s data economy, its reference architecture [139] and principles are broadly location-independent. It can, therefore, be applied to cater for global participation by using compatible federated protocols and identities.
That said, Gaia-X’s original ambitions have not yet been fulfilled [140] [141], and progress appears to have reached a trough of disillusionment [142]. Still, Gaia-X has helped move the needle on Ecosystems Architecture in Europe by establishing consensus within several, economic, and political communities. Its ongoing struggles no doubt point to a fundamental characteristic of ecosystems, however, in that they generally do not respond well to direction from any single source — no matter how official or justified that direction or its origin. To say that another way, “just causes generally do not flourish in a sea of opinions”. As discussed already, consensus, and therefore commitment en mass, generally emerges from the masses, rather than through direct intervention. Consequently, the odds of any mandated interoperability program succeeding in an ecosystem context may be average at best. But then, that is always the challenge with any start-up standards initiative. Even so, several prima facie examples can be found which suggest that leading by example can be a good thing. And it turns out that the inclusion of new technology in the mix can be of decided benefit.
Take, for instance, the case of the QWERTY keyboard. Although its layout is ubiquitous today, it is by no means the most efficient design for human typing. In fact, in 1873 an engineer named Christopher Scholes designed its layout specifically to slow typists down, given that the typewriting machines of the day tended to jam when typists typed too fast. But the Remington Sewing Machine Company mass-produced a typewriter using the QWERTY system, which meant that lots of typists began to learn its layout, which meant that other typewriter companies began to offer QWERTY versions of their own machines, which meant that still more typists began to learn it, and so on and so on. Through this process of positive reinforcement, the QWERTY keyboard layout is now used by millions. Early market entry and positive feedback have therefore catapulted it to be the standard for all its flaws and weaknesses.
To reinforce this point, consider the Betamax™ versus VHS™ competition in the videotape market of the 1970s and 80s. Even in 1979, it was clear that the VHS format was well on its way to cornering the market, despite the fact that many experts had originally rated it to be technologically inferior to Betamax. How could this have happened? Simply because the VHS vendors were lucky enough to gain a slightly bigger market share in the beginning, which gave them an enormous advantage in spite of the technological differences. Video stores hated having to stock everything in two formats and consumers hated the idea of being stuck with obsolete VCRs, so everyone had a big incentive to go along with the market leader. That pushed up the VHS market lead even more and the small initial difference grew rapidly. This is again a case of increasing returns and a fine example of how the propensity to use certain types of technology can lock in users.
5.3. Semantic Web-Enabled Software Engineering
Moving on, it turns out that the idea of formally describing large, complex, self-organizing IT systems in an effort to engineer within them, is not a new thing.
Back in the mid-1990s, just around the time when the World Wide Web was about to hit mass adoption, a group of engineers intent on helping its progress spotted a problem. That charge was led by the computer scientist Ramanathan Guha [143] who argued, given that the Web was being run on computers, would it not make sense for those computers to understand the content they were serving as well? In other words, would it not be great if the Web was made machine-readable? That would help increase levels of automation, not least in the increasingly important area of advanced search.
At the time, this was a revelation. The world’s search engines were only just starting to stand up and progress in Natural Language Processing research was slow. To enhance the Web’s architecture and enable computers to do more useful work just made sense. Out of that came the W3C [144] Semantic Web [98] [99], or “Web of Data” initiative. Its central idea was to add metadata to Web pages and other online resources and in a standardized format, so that machines could understand what the pages were about and how that related to other information elsewhere on the Web. This was primarily to make it easier for computers to “reason” about the content, and to link related information together. The Semantic Web, therefore, uses a variety of technologies and standards, including the Resource Description Framework (RDF) [145], the Web Ontology Language (OWL) [146], and the SPARQL [147] query language. These allow developers to create rich, structured data sets that can be easily shared and queried by other applications.
As part of the Semantic Web work, the W3C started a Best Practices and Deployment Working Group [148] in 2004, with the aim to provide hands-on support for developers of Semantic Web applications. That then spun out a subsidiary task force [149] specifically asked to investigate potential synergies between the Semantic Web and domains more traditionally associated with software engineering. In practice, that amounted to a fait accompli, as its members already knew that technologies like RDF could be used to catalog and describe software-focused assets, like program code, data stores, and so on. Likewise, they knew that the same technologies could be repurposed to catalog and describe IT architectures at both systems and enterprise levels.
To do this was relatively simple. RDF and OWL are derivatives of the eXtensible Markup Language (XML®) [150], and so are built from the ground up to document collections of structured assets or ideas. That makes them graph-based by definition, meaning that XML is based on the idea of denoted nodes linked by denoted connections. Therefore, XML is eminently suitable for describing all forms of connected systems, be they data-based, software-based, architecture-based, or even chicken-n-waffle-based!
The highfalutin way to say this is to state that semantic web technologies are ontologically focused, but hopefully you get the point. That is, that the semantic web offers an equivalent framework to that of graphs encoded using eigenvectors. Overall, it is a different encoding method, but with the same approximate end effect. Not only that, but it is possible to translate between the two with little or no loss in translation. In that way, architects can seamlessly move from the precision offered by the mathematics of vector algebra, across into the practicalities of a strongly grammar-based language, as found in XML derivatives. What is more, as those derivatives are machine-readable and potentially machine-understandable, it is a relatively trivial task to automatically generate program code from the XML specifications in hand. In that way, using semantic-web technologies provides intermediate translation mechanisms that allow systems, systems-of-systems, and ecosystems-based architectures to be accurately specified then transformed into working solutions, give or take a few minor practicalities along the way.
So, with regard to our earlier example of an interface between two ecosystems nodes needing an update, so long as that change is specified in enough detail, and equivalent detail is also available to describe both the participating nodes and their connection, in an increasing world of advanced AI it should not be insurmountable to quickly generate replacement code upon request.
5.4. GenAI and Intermediate Modeling Languages
As an interesting aside, it is worth noting that RDF and OWL are both just text-based modeling languages and, given that many popular GenAI models are also text-based, they can be instructed to provide output using the syntax of either language. For example, a GenAI instance can be prompted to:
“Output all the following text using the sytnax of the Web Ontology Language OWL. Confirm you understand”.
Then prompted with the following text:
“Interface A interacts with Interface B using REST exchanges and a packet size of 128KB”.
This will instruct the GenAI to produce the output shown in OWL Format Code.
# Define the classes for Interface A and Interface B :A rdf:type owl:Class. :B rdf:type owl:Class. # Define the interaction relationship :A interactsWith :B. # Define the type of interaction (REST) :AInteraction rdf:type owl:Class. :BInteraction rdf:type owl:Class. :A interactsWith :AInteraction. :B interactsWith :BInteraction. # Define the packet size using an annotation property :packetSize rdf:type owl:AnnotationProperty. :AInteraction :packetSize "128KB"^^xsd:string. # Define the type of exchange (REST) :restExchange rdf:type owl:Class. :AInteraction rdf:type :restExchange. :BInteraction rdf:type :restExchange.
Other text-based modeling languages can also be used to control output syntax. For example, Mermaid JavaScript™ [151] and Plant UML [152] both support text-based modeling languages that can be used to generate architectural schematics. It is therefore not only reasonable, but eminently practical to perhaps think of generating such schematics automatically using GenAI.
For instance, by first providing the prompt:
“Output all the following requests as PlantUML code. Confirm if you understand”.
Then instructing:
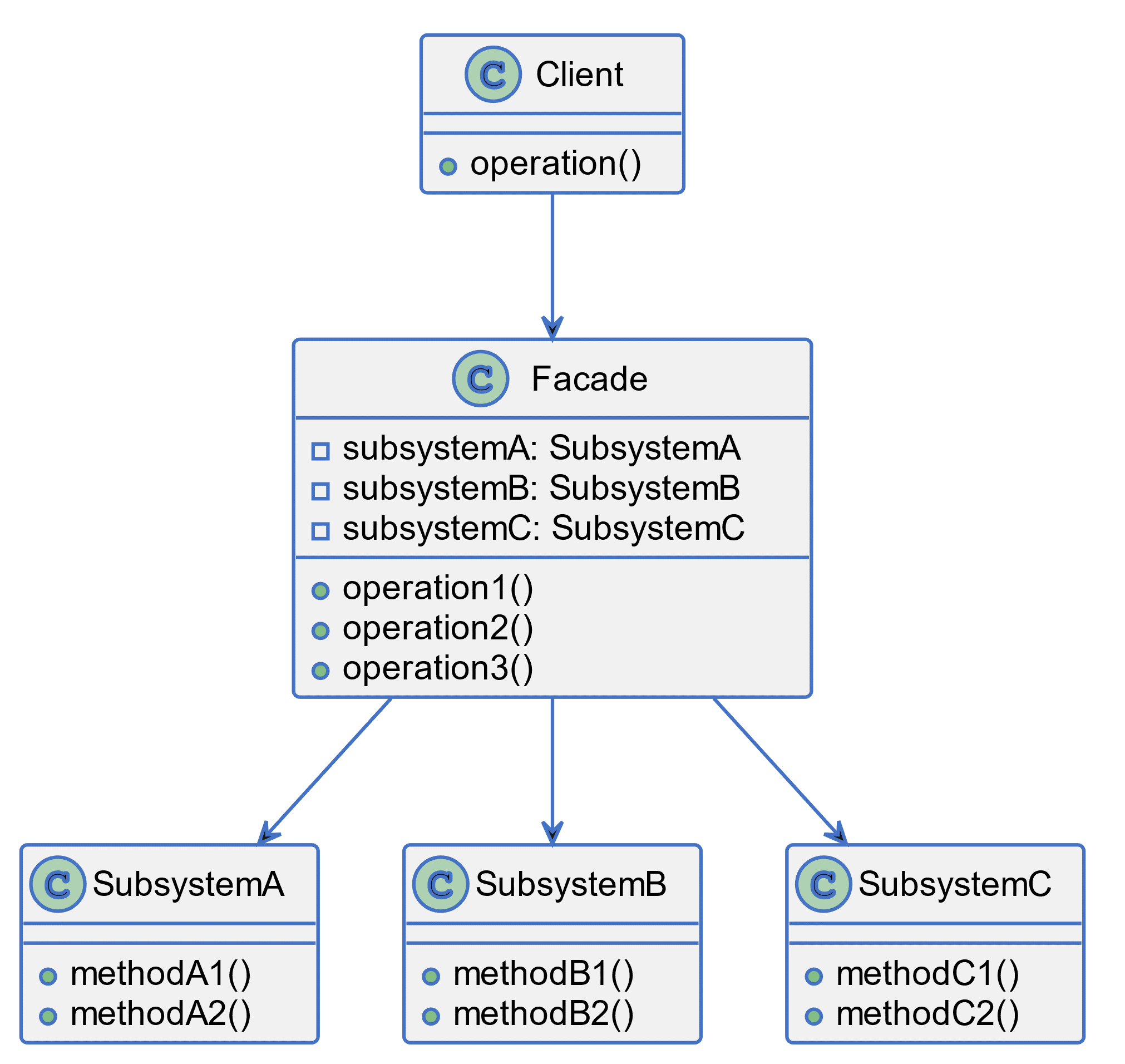
“Create a class diagram to show the essential characteristics of a facade software pattern”.
Which will output the code shown in PlantUML Code.
Plantuml
@startuml FacadePattern
class Client {
+ operation()
}
class SubsystemA {
+ methodA1()
+ methodA2()
}
class SubsystemB {
+ methodB1()
+ methodB2()
}
class SubsystemC {
+ methodC1()
+ methodC2()
}
class Facade {
- subsystemA: SubsystemA
- subsystemB: SubsystemB
- subsystemC: SubsystemC
+ operation1()
+ operation2()
+ operation3()
}
Client --> Facade
Facade --> SubsystemA
Facade --> SubsystemB
Facade --> SubsystemC
@enduml
This code can then be fed into a PlantUML editor like PlantText [153] to produce the schematic shown in Figure 26.
5.5. Quantum Semantics and Applied Quantum Computing
Now, one final curveball.
It is all well and good that we have managed to find a route from an abstract understanding of hyper-enterprise systems down to ways to automate their construction and maintenance, but some very basic properties of these systems stand a very real chance of getting in the way. All along, for instance, we have stressed the idea that hyper-Enterprise Architectures can be large and complex. Humongous might even be a better word. So, those familiar with the tools and techniques we have been advocating might also understand that they are fine when dealing with small problems, but humongous is a whole other thing. XML for example, in theory provides an infinitely extensible framework for description and/or specification. Likewise, there is no theoretical upper limit to the size of systems that it can describe. However, and it is a big however, XML is a particularly verbose language that can take a lot of computing to process effectively. That, therefore, creates a practical upper limit to what can and cannot be handled. Furthermore, it must be asked why all the trouble of describing a quantum-like approach to specification, then advocating an intermediate step of translating via an XML derivative. Surely that is like mixing oil with water, right? Why use a chisel to do the job of a screwdriver? Might it not be possible to use the same paradigm throughout, perhaps sidestepping any practical limitations brought by the potential scale of the problem being addressed?
Well, the answer is potentially “yes”, but it is still very much early days.
Given that all the ways forward advocated in this document have been strongly based on graphs and graph theory, might it not be possible to represent and process such graphs directly using a quantum approach to computing? That, in essence, means modeling a target problem space and its nascent architecture directly using quantum computers and the qubits that they contain.
The short answer is potentially “yes”,[6] but before understanding why, the workings of quantum computers need to be briefly summarized.
You will no doubt know that the fundamental unit of information storage in a traditional digital computer is the bit. As such, each bit behaves like a tiny switch and is only ever referenced when it is purely on or purely off. There is no middle ground. Classical computer bits are therefore tiny binary switches that measure microns across, but nonetheless likely comprise many thousands of atoms. In practical engineering terms then, even the smallest physical bit could, if you so wished, be inspected under a microscope. Quantum computers work differently, however. Instead of using classical bits, they use quantum bits or qubits, which are made from single atoms or photons of light. That not only means that these devices are tiny, and so cannot be inspected directly at the human scale, but they work in some counter-intuitive ways, dictated by the laws of quantum mechanics.
At this point, we need to mix in some basic chemistry. Hopefully, you will remember that atoms comprise of a tiny nucleus, surrounded by a spinning cloud of electrons, and that in certain circumstances the number of electrons present can leave an atom with an electronic charge. Such charged atoms are what we call ions and, in the most common model of quantum computing, they provide the stuff from which qubits are made.
Now, it turns out that the electrons in an ion are particularly hard to pin down, but there are ways of persuading them to help align their parent atom in very useful ways. This is rather like taking an eight-ball from a pool table and carefully rotating it so that the number eight faces up or down, front or back and so forth. Cleverly, this kind of precise rotation and the ion’s resulting orientation correlates with the idea of on or off, 0 or 1 in a classical bit. And because icons can be rotated in three dimensions, that means that, by default, qubits can hold six values, rather than just the two in a standard classical bit.
This is a game-changer in itself, but it is not quite the full story. Because electrons are devilishly hard to pin down, it is never a simple matter of just asking an ion to align itself as you would like. Instead, ions like to misbehave, as quantum mechanics itself mandates. That means that some of the time a qubit will switch properly and sometimes it will not, therefore making reading and writing qubits a bit of a gamble.
In a more formal way, that means that qubits are probabilistic and require multiple attempts to persuade them to behave as we would like. This nets out into the fact that you cannot just read the value of a qubit once and expect the answer to be correct. Instead, you have to read it multiple times and average out the result. This might seem like a clumsy way to go about things, but actually, we know how to do it well now and modern quantum computers are getting better all the time in the ways that they get qubits to perform.
All that aside, there are a couple of other features of qubits, and quantum computers in general, that are particularly exciting when applied to Ecosystems Architecture.
The first is that, although standard engineering practice and a good deal of theoretical physics suggest that qubits must align precisely up or down, front or back, right or left, that does not necessarily mean that that always has to be the case. For instance, using deliberate contortion tricks, likely involving error correction techniques, we could possibly ask a qubit to orientate five degrees right of vertical up. Indeed, we could ask a qubit to align in an infinite number of orientations if we were granted enough engineering precision.
In information engineering terms, this is truly significant. From that vantage point, a classical bit can be said to hold a vocabulary of two settings or symbols, as in the values 0 and 1. Likewise, a classical qubit can be seen to hold a vocabulary size of six. In that way, it could be said that a classical bit uses the binary base system, whereas classical qubits work according to the higher order number systems, like the senary (heximal) [154] base system. In a similar way then, if we were able to coerce a qubit to align in any one of 256 ways, it would work according to base-256.
Now, what is interesting here is that when thinking in terms of base-256, you do not necessarily have to imagine a number line consisting of 256 discrete number values. Instead, you can associate each entry in that base with a different system of symbols. So, instead of considering base-256 as being a numeric vocabulary, it is just as valid to consider it as representing a character-based system, like, say the ASCII character set [155]. But why stop there? We could practically think of qubits working according to base-1000, base-10000 or whatever, in which case each symbol could act as an index, rather than a character or a number. What that therefore means is that we could encode an effective referencing system at the atomic level, and if that system had enough capacity, we could store an index to describe any of the nodes present in an ecosystem and/or its associate architecture.
That covers node documentation, but what about the connections between nodes? How might we represent an abstract graph model across a number of qubits?
Again, it turns out that quantum mechanics comes to the rescue with a property known as quantum entanglement.
Quantum entanglement is therefore a phenomenon where two or more atomic particles become connected in a way that their properties are correlated, even when they are physically separated from each other. This correlation exists regardless of the distance between the particles and can be instantaneously observed when one of the entangled particles is measured, affecting the other particle’s properties simultaneously.
To say that differently, we can, in theory, plug qubits together much like we do nodes in an abstract graph, and in that way potentially model hyper-Enterprise Architectures across meshes of qubits.
Needless to say, in making this statement, just as with qubit orientation, quantum entanglement need not just be fully engaged or not, and the same way as described above, you can theoretically encode a use full referencing system via degrees of entanglement.
All of this amounts to the emerging field now known as Quantum Semantics [156] [157], and although the practical details of how it might be implemented still need to be worked through, the theory involved is remarkably sound. It also indirectly speaks to one particular advantage brought by quantum computing over classical variants.
When a problem space is large and all its constituent elements must be considered, there are generally only two ways to go about that. The first requires that each element is inspected in turn, sequentially and via a continual loop. This, of course, carries the drawback of perhaps being time-consuming to the point of obstruction. Parallel inspection, therefore, provides an alternative and is where all elements are inspected at once. But this approach also has its limitations, in that parallel execution demands a lot of computing power, and often specific types of machine, to do the work necessary.
This class of challenge covers what computer scientists refer to as being np[7] complete problems, in that associated tasks can be accomplished in a measurable, but not necessarily practical, period. np hard problems, therefore, represent a class of np complete problems that are known to take a lot of time to compute and will therefore likely drain a lot of computing resource. On that basis then, addressing the needs of hyper-enterprise systems could highly likely be called out as an np hard challenge, which is not exactly ideal. Not ideal, that is, for classical forms of computing, but not so much for quantum variants, as it happens.
Through a property of quantum mechanics known as quantum collapse, it is possible to undertake the equivalent of high-scale parallel processing using a fraction of the computing resources needed when classical computers are used. In this technique, it is possible to represent all possible outcomes of a problem within a quantum computer, then take a guess as to what the most appropriate answer might be. Rather than returning with the specifics of that choice, the machine will tell if your guess was right or wrong.
All told, therefore, the promise of quantum computing and quantum information feels ideally placed to help assist to a world of Ecosystems Architecture. The next few years will see both fields mature to the point of realistic adoption and real-world application. Whereas now, we are at a stage little more advanced than when classical computers needed programming with assembler, progress on everything quantum is moving apace.
5.6. Feet Back on the Ground
This is, of course, all well and good. But there are many more areas and ideas to explore, and not all can be covered in a single book like this. Nevertheless, we can signpost that this type of thinking indeed holds potential for several well established, ongoing IT challenges.
The following list highlights just two interesting, and hopefully obvious, examples:
-
Organizations Looking to Decentralize Internally and Externally
This may be in response to market opportunities, internal or external pressures, or other reasons. Regardless, circumstances may require ecosystems to be created and/or adapted both within and around the enterprise — thereby entailing that business functions or whole organizations become essential to several ecosystems and at a number of levels. This presents a multi-faceted challenge requiring that individual ecosystems work well and without significant cross-boundary (interoperability) interference.
Traditionally, Enterprise Architecture primarily looked at internal interoperability — perhaps wrongly. Multi-level decentralization changes that focus. -
Organizations Looking to Recentralize
Rather perversely, organizations that have allowed or even encouraged a proliferation of internal silos also need to consider bringing an ecosystems perspective into play. This will help ensure that they do not exclusively become inward-facing, thereby restricting opportunities for collaboration, expansion, and so on.