2. Digital infrastructure
2.1. Introduction

As mentioned in the Part introduction, you cannot start developing a product until you decide what you will build it with. (You may have a difficult time writing an app for a mobile phone if you choose the COBOL programming language!) You also need to understand something of how computers are operated, enough so that you can make decisions on how your system will run. Most startups choose to run IT services on infrastructure owned by a cloud computing provider, but there are other options. Certainly, as you scale up, you’ll need to be more and more sophisticated in your understanding of your underlying IT services.
Configuring your base platform is one of the most important capabilities you will need to develop. You’ll never stop doing it. The basis of modern configuration management is version control, which we cover here.
This is one of the more technical chapters. Supplementary reading may be required for those completely unfamiliar with computing. See Assumptions of the Reader for notes on the book’s approach. [1]
2.1.1. Chapter summary
-
Introduction
-
Chapter summary
-
Learning objectives
-
-
Infrastructure overview
-
What is infrastructure?
-
Basic IT infrastructure concepts
-
-
Choosing infrastructure
-
From “physical” compute to cloud
-
Virtualization
-
Why is virtualization important?
-
Virtualization versus cloud
-
Containers and looking ahead
-
-
Infrastructure as code
-
A simple infrastructure as code example
-
-
Configuration management: the basics
-
What is version control?
-
Package management
-
Deployment management
-
-
Topics in IT infrastructure
-
Configuration management, version control, and metadata
-
-
Conclusion
-
Discussion questions
-
Research & practice
-
Further reading
-
2.1.2. Learning objectives
-
Understand fundamental principles of operating computers as infrastructure for a service
-
Understand cloud as a computing option
-
Understand basic principles of “infrastructure as code”
-
Understand the importance and basic practices of version control and why it applies to infrastructure management
2.2. Infrastructure overview
|
Note
|
If you are familiar with computers and networks, you may wish to skip ahead to Choosing infrastructure. |
In the previous chapter, you were introduced to the concept of a "moment of truth" , and in the final exercises, asked to think of a product idea. Some part of that product requires writing software, or at least configuring some IT system. (IT being defined as in Chapter 1). You presumably have some resources (time and money). It’s Monday morning, you have cleared all distractions, shut down your Twitter and Facebook feeds, and are ready to start building.
Not so fast.
Before you can start writing code, you need to decide how and where it will run. This means you need some kind of a platform -— some computing resources, most likely networked, where you can build your product and eventually expose it to the world. It’s hard to build before you decide on your materials and tools. You need to decide what language programming language you are going to write in, what framework you are going to use, and how those resources will result in an operational system capable of rendering IT services. You are probably swimming in a sea of advice and options regarding your technical choices. In previous decades, books such as this might have gone into the specifics of particular platforms: mainframe versus minicomputers, COBOL versusFORTRAN, Windows versusUNIX systems, etc.
At this writing, JavaScript is a leading choice of programming language, in conjunction with various frameworks and NoSQL options (e.g.,the MEAN stack, for MongoDB, Express, Angular, and Node.js), but millions of developers are still writing Java and .Net, and Ruby and Python have significant followings. Linux is arguably the leading platform, but commercial UNIX and Microsoft platforms are still strong. And, periodically it’s reported that the majority of the world’s transactions still run on COBOL-based systems.
However, in the past few years, some powerful infrastructure concepts have solidified that are independent of particular platforms:
-
“Cloud"-based technology services
-
Automation and “infrastructure as code”
-
The centrality of source control
-
The importance of package management
-
Policy-based infrastructure management
(We’ll get to test-driven development, pipeline automation & DevOps in the next chapter).
This might seem like a detour — you are in a hurry to start writing code! But industry practice is clear. You check your code into source control from Day One. You define your server configurations as recipes, manifests, or at least shell scripts, and check those definitions into source control as well. You keep track of what you have downloaded from the Internet and what version of stuff you are using, through package management (which uses different tools than source control). Always downloading the “latest” package from its upstream creator might seem like the way to stay current, but it will kill you when stuff works on one server but not on another.
So, you need to understand a few things and make a few decisions that you will be living with for a while, and will not be easily changed.
2.2.1. What is infrastructure?
Infrastructure is a tricky word. Google defines it thus:
The basic physical and organizational structures and facilities (e.g., buildings, roads, and power supplies) needed for the operation of a society or enterprise.
In general, it connotes the stuff behind the scenes, the things you need but don’t want to spend a lot of time thinking about. We will spend a lot of time examining what we mean by “infrastructure” in this book, as it is fundamental to understanding the “business of IT.” This book defines “IT infrastructure” recursively as “the set of IT concerns that are of particular interest to IT.”
-
An application or business service is consumed by people who are NOT primarily concerned with IT. For example, a customer-facing online banking service is consumed by end users.
-
An IT infrastructure service is a service consumed by other IT-centric teams and capabilities. For example, a database or a load balancing service is consumed by other IT teams.
IT infrastructure is one form of infrastructure. Other kinds of infrastructure might include mechanical, electrical, and plant (ME & P) investments . IT infrastructure, like IT itself, is defined by its fundamental dependence on information and computing theory.
2.2.2. Basic IT infrastructure concepts
There are many books (some in the Further Reading section for this chapter) on all aspects of IT infrastructure, which is a broad and deep topic. Our discussion of it here has to be high level, as appropriate for a survey course. We’ve established what we mean by IT generally. Pragmatically, there are three major physical aspects to “IT infrastructure” relevant to the practitioner:
-
Computing cycles (sometimes called just “compute”)
-
Memory & storage (or “storage”)
-
Networking & communications (or “network”)
We will discuss a variety of subsidiary concerns and concepts, but those are the big three.
Compute is the resource that performs the rapid, clock-driven digital logic that transforms data inputs to outputs.
|
Tip
|
For a beginner-level introduction to the world of digital logic at its most fundamental, see Code, by Charles Petzold. |
If we have a picture of our friend, and we use a digital filter to adjust the brightness, that is an application of compute power. The picture is made up of “pixels” (see Picture enlarged to show pixels[2]]) which are nothing but numbers representing the color of some tiny square of the picture. Each of those numbers needs to be evaluated and the brightness adjusted. There may be millions in a single image.

For example, let’s say that the pixel values range from 1 to 10, with 1 being the darkest and 10 being the lightest (in reality, the range is much larger). To brighten a picture, we might tell the computer:
-
Look at a pixel
-
If it is between 0 and 3 add 2
-
If it is between 4 and 6 add 1
-
Move to a new pixel
-
Repeat the above 4 lines until all pixels are done
At a more realistic level, the process might be executed as a batch on a workstation, for hundreds or thousands of photos at a time.
Computers process instructions at the level of “true” and “false,” represented as binary “1s” and “0s.” Because humans cannot easily understand binary data and processing, higher-level abstractions of machine code and programming languages are used.
It’s critical to understand that computers, traditionally understood, can only operate in precise, "either-or" ways. Computers are often used to automate business processes, but in order to do so, the process needs to be carefully defined, with no ambiguity. Either the customer has bought the item, or they have not. Either they live in Minnesota, or Wisconsin. Complications and nuances, intuitive understandings, judgment calls -— in general, computers can’t do any of this, unless and until you program them to -— at which point the logic is no longer intuitive or a judgment call. (Deep learning systems based on neural networks, and similar artificial intelligence, are beyond our discussion here -— and in any event, are still based on these binary fundamentals).
|
Important
|
The irony is that, as we will discuss repeatedly in this book, the process by which these deterministic digital systems are developed is itself a process requiring all those "soft" components that computers can’t automate. |
Computer processing is not free. Moving data from one point to another — the fundamental transmission of information — requires matter and energy, and is bound up in physical reality and the laws of thermodynamics. The same applies for changing the state of data, which usually involves moving it somewhere, operating on it, and returning it to its original location. In the real world, even running the simplest calculation has physical and therefore economic cost, and so we must pay for computing.
|
Important
|
If these concepts are strange to you, spend some time with the suggested Wikipedia articles, or otherwise researching the topics. Wikipedia in the area of fundamental computer concepts is generally accurate. |

Storage But where did the picture come from? The data comprising the pixels needs to be stored somewhere (see Disks in a storage array [3]). Sometimes you will hear the technical term “persisted.” The combined set of pixels and their precise values can be termed the “state” of the photograph; the digital logic of the filter alters the state, and also needs to save this new state somewhere (otherwise it will be lost).
Many technologies have been used for digital storage. Increasingly, the IT professional need not be concerned with the physical infrastructure used for storing data. As we will cover in the next section, storage increasingly is experienced as a virtual resource, accessed through executing programmed logic on cloud platforms. “Underneath the covers” the cloud provider might be using various forms of storage, from RAM to solid state drives to tapes, but the end user is, ideally, shielded from the implementation details (part of the definition of a service).
However, it is important to understand that in general, storage follows a hierarchy. Just as we might “store” a document by holding it in our hands, setting it on a desktop, filing it in a cabinet, or archiving it in a banker’s box in an offsite warehouse, so computer storage also has different levels of speed and accessibility:
-
On-chip registers and cache
-
Random-access memory (RAM), aka “main memory”
-
Online mass storage, often “disk”
-
Offline mass storage, e.g., “tape”
If this is unfamiliar, see Wikipedia or research on your own; you should have a basic grasp of this issue.
Network We can change the state of some data, or store it. We also need to move it. This is the basic concern of networking, to transmit data (or information) from one location to another. If you use your cell phone to look up your bank balance, there is a network involved (see Network cabling in a rack[4]) -— otherwise, how did the data get from the bank’s computer in New Jersey to your cell phone in Minnesota? We see evidence of networking every day; you may be familiar with coaxial cables for cable TV, or telephone lines strung from pole to pole in many areas. However, like storage, there is also a hierarchy of networking:
-
Intra-chip pathways
-
Motherboard and backplane circuits

And like storage and compute, networking as a service increasingly is independent of implementation. The developer uses programmatic tools to define expected information transmission, and (again ideally) need not be concerned with the specific networking technologies or architectures serving their needs.
2.3. Choosing infrastructure
|
Note
|
The following is written as if you are a decision-maker in the early stages of conceiving a product. If you are an individual contributor in a large enterprise, or even a newcomer to an established product team, these decisions will likely have been made for you. But at some point, someone had to go through this decision process, before anything could be developed. |

There is ferocious turbulence in the IT infrastructure market. Cloud computing, containers, serverless computing, providers coming and going, various arguments over "which platform is better," and so forth. As an entrepreneur, you need to understand what technical trends are important to you. Furthermore, you will need to make some level of commitment to your technical architecture. And at some point you WILL be asked, “You’re still using that old technology?” As a startup, you have a couple initial decisions to make regarding infrastructure and tools:
-
What is my vision for bringing my product to the world?
-
What toolset should I use to forward this vision?
As a startup, it would seem likely that you would use a commodity cloud provider. This text is based on this assumption (physical IT asset management will be discussed in Sections 3 and 4). Is there any reason why the public cloud would not work for you? For example, if you want to develop on a LAMP stack, you need a cloud provider that will support you in this. While most are very flexible, you will need to consider the specific support levels they are offering; a provider that supports the platform (and not just the operating system) might be more valuable, but there may be higher costs and other trade-offs.
There is a near-infinite amount of material, debate, discussion, books, blogs, lists, and so forth concerning choice of language and platform. Exploring this area is not the purpose of this book. However, this book has certain assumptions:
-
Your system will be built, at least in part, with some form of programming language which is human-readable and compiled or interpreted into binary instructions.
-
Your system will run on general-purpose digital computers using well known technologies.
-
Your computing environment is networked in a standard way.
-
You use the concept of a software pipeline, in which new functionality is developed in a scope distinct from what is currently offered as your product/service.
-
New functionality moves through the pipeline at significant volumes and velocity and you are concerned with optimizing this overall flow [5].
|
Important
|
Dynamic, automated infrastructure (as provided by cloud suppliers) enables rapid iterations and scaling. Iterative development and rapid scaling, while possible, was often more difficult with earlier, less automated technical platforms. |
There is a long tradition in IT management of saying “How can you be thinking about infrastructure before you have gone deeply into requirements?”
Let’s be clear, in defining a product (Chapter 1) you already have started to think about "requirements," although we have not yet started to use that term. (We’ll define it in Chapter 3). The idea that all requirements need to be understood in detail before considering technical platform is, in general, an outmoded concept that made more sense when hardware was more specialized and only available as expensive, organization-owned assets. With the emergence of cloud providers able to sell computing services, companies no longer need to commit to large capital outlays. And digital product professionals realize that requirements are never fully “understood” up front (more on this in the next chapter). Your MVP is an initial statement of requirements from which you should be able to infer at least initial toolset and platform requirements. Here to get you started are the major players as of this writing:
| Stack 1 (Enterprise Java) | Stack 2 (Microsoft) | Stack 3 (LAMP) | Stack 4 (MEAN) |
|---|---|---|---|
Java |
C# |
PHP |
JavaScript, Express & Angular |
Oracle DB |
MS SQL Server |
MySQL |
MongoDB |
Websphere |
.Net |
Apache Web Server |
Node.js |
Commercial UNIX systems |
Microsoft Windows |
Red Hat Linux |
Ubuntu Linux |
Ruby on Rails is another frequently-encountered platform. If you are building a data or analytics-centric product, R and Python are popular. There is a good reason, however, why you should not spend too much time “analyzing” before you make platform decisions. The reality is that you cannot know all of the factors necessary to make a perfect decision, and in fact the way you will learn them is by moving forward and testing out various approaches. So, choose Ruby on Rails, or LAMP, or MEAN, and a hosting provider who supports them, and start. You can easily stand up environments for comparison using cloud services, or even with lightweight virtualization (Vagrant or Docker) on your own personal laptop. Do not fall into analysis paralysis. But be critical of everything especially in your first few weeks of development. Ask yourself:
-
Can I see myself doing things this way for the next year?
-
Will I be able to train people in this platform?
-
Will this scale to a bigger code base? Higher performance? Faster throughput of new features?
If you become uncomfortable with the answers, you should consider alternatives.
2.4. From “physical” compute to cloud
According to the National Institute for Standards and Technology, cloud is:
Before cloud, people generally bought computers of varying sizes and power ratings to deliver the IT value they sought. With cloud services, the same compute capacity can be rented or leased by the minute or hour, and accessed over the Internet.
There is much to learn about cloud computing. In this section, we will discuss the following aspects:
-
Virtualization basics
-
Virtualization, managed services, and cloud
-
The various kinds of cloud services
-
Future trends
2.4.1. Virtualization
Virtualization, for the purposes of this section, starts with the idea of a computer within a computer. (It has applicability to storage and networking as well but we will skip that for now). In order to understand this, we need to understand a little bit about operating systems and how they relate to the physical computer.

Assume a simple, physical computer such as a laptop (see Laptop computer, [6]). When the laptop is first turned on, the OS loads; the OS is itself software, but is able to directly control the computer’s physical resources: its CPU, memory, screen, and any interfaces such as WiFi, USB, and Bluetooth. The operating system (in a traditional approach) then is used to run “applications” such as Web browsers, media players, word processors, spreadsheets, and the like. Many such programs can also be run as applications within the browser, but the browser still needs to be run as an application.
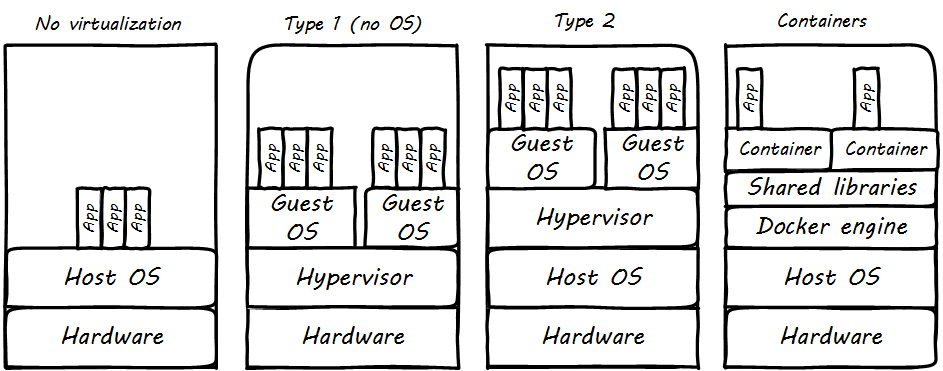
In the simplest form of virtualization, a specialized application known as a hypervisor is loaded like any other application. The purpose of this hypervisor is to emulate the hardware computer in software. Once the hypervisor is running, it can emulate any number of “virtual” computers, each of which can have its own operating system (see Virtualization is computers within a computer). The hypervisor mediates the "virtual machine" (VM) access to the actual, physical hardware of the laptop; the VM can take input from the USB port, and output to the Bluetooth interface, just like the master OS that launched when the laptop was turned on.
There are two different kinds of hypervisors. The example we just discussed was an example of a Type 2 hypervisor, which runs on top of a host OS. In a Type 1 hypervisor, a master host OS is not used; the hypervisor runs on the “bare metal” of the computer and in turn “hosts” multiple VMs.
|
Note
|
You can experiment with a hypervisor by downloading Virtualbox (on Windows, Mac OS, or Linux) and using Vagrant to download and initialize a Linux virtual machine. You’ll probably want at least 4 gigabytes of RAM on your laptop and a gigabyte of free disk space, at the bare minimum. |
Paravirtualization, e.g., containers, is another form of virtualization found in the marketplace. In a paravirtualized environment, a core OS is able to abstract hardware resources for multiple virtual guest environments without having to virtualize hardware for each guest. The benefit of this type of virtualization is increased Input/Output (I/O) efficiency and performance for each of the guest environments.
However, while hypervisors can support a diverse array of virtual machines with different OSs on a single computing node, guest environments in a paravirtualized system generally share a single OS. See Virtualization types for an overview of all the types.
|
Note
|
Virtualization was predicted in the earliest theories that led to the development of computers. Turing and Church realized that any general-purpose computer could emulate any other. Virtual systems have existed in some form since at latest 1967 — only 20 years after the first fully functional computers. And yes, you can run computers within computers within computers with virtualization. Not all products support this, and they get slower and slower the more levels you create, but the logic still works. |
2.4.2. Why is virtualization important?
Virtualization attracted business attention as a means to consolidate computing workloads. For years, companies would purchase servers to run applications of various sizes, and in many cases the computers were badly underutilized. Because of configuration issues and (arguably) an overabundance of caution, average utilization in a pre-virtualization data center might average 10-20%. That’s up to 90% of the computer’s capacity being wasted (see Inefficient utilization).
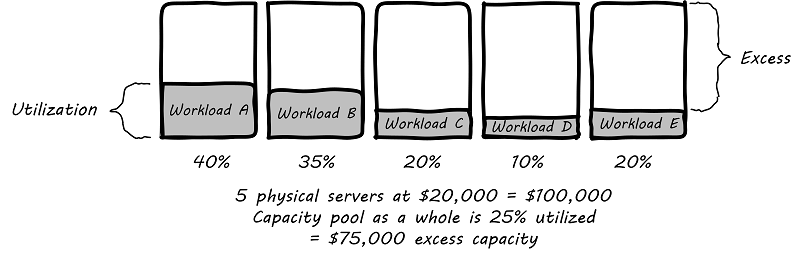
The above figure is a simplification. Computing and storage infrastructure supporting each application stack in the business were sized to support each workload. For example, a payroll server might run on a different infrastructure configuration than a data warehouse server. Large enterprises needed to support hundreds of different infrastructure configurations, increasing maintenance and support costs.
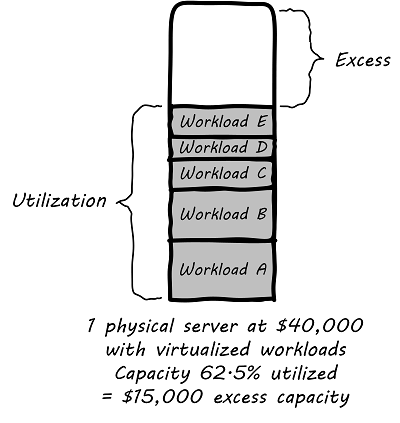
The adoption of virtualization allowed businesses to compress multiple application workloads onto a smaller number of physical servers (see Efficiency through virtualization).
|
Note
|
For illustration only. A utilization of 62.5% might actually be a bit too high for comfort, depending on the variability and criticality of the workloads. |
In most virtualized architectures, the physical servers supporting workloads share a consistent configuration, which made it easy to add and remove resources from the environment. The VMs may still vary greatly in configuration, but the fact of virtualization makes managing that easier — the VMs can be easily copied and moved, and increasingly can be defined as a form of code (see next section).
Virtualization thus introduced a new design pattern into the enterprise where computing and storage infrastructure became commoditized building blocks supporting an ever-increasing array of services. But what about where the application is large and virtualization is mostly overhead? Virtualization still may make sense in terms of management consistency and ease of system recovery.
2.4.3. Virtualization, managed services, and cloud
Companies have always sought alternatives to owning their own computers. There is a long tradition of managed services, where applications are built out by a customer and then their management is outsourced to a third party. Using fractions of mainframe “time-sharing” systems is a practice that dates back decades. However, such relationships took effort to set up and manage, and might even require bringing physical tapes to the third party (sometimes called a “service bureau.”) Fixed price commitments were usually high (the customer had to guarantee to spend X dollars). Such relationships left much to be desired in terms of responsiveness to change.
As computers became cheaper, companies increasingly acquired their own data centers, investing large amounts of capital in high-technology spaces with extensive power and cooling infrastructure. This was the trend through the late 1980s to about 2010, when cloud computing started to provide a realistic alternative with true “pay as you go” pricing, analogous to electric metering.

The idea of running IT completely as a utility service goes back at least to 1965 and the publication of The Challenge of the Computer Utility, by Douglas Parkhill (see Initial statement of cloud computing). While the conceptual idea of cloud and utility computing was foreseeable 50 years ago, it took many years of hard-won IT evolution to support the vision. Reliable hardware of exponentially increasing performance, robust open-source software, Internet backbones of massive speed and capacity, and many other factors converged towards this end.
However, people store data — often private — on computers. In order to deliver compute as a utility, it is essential to segregate each customer’s workload from all others. This is called multi-tenancy. In multi-tenancy, multiple customers share physical resources that provide the illusion of being dedicated.
|
Note
|
The phone system has been multi-tenant ever since they got rid of party lines. A party line was a shared line where anyone on it could hear every other person. |
In order to run compute as a utility, multi-tenancy was essential. This is different from electricity (but similar to the phone system). As noted elsewhere, one watt of electric power is like any other and there is less concern for leakage or unexpected interactions. People’s bank balances are not encoded somehow into the power generation and distribution infrastructure.
Virtualization is necessary, but not sufficient for cloud. True cloud services are highly automated, and most cloud analysts will insist that if VMs cannot be created and configured in a completely automated fashion, the service is not true cloud. This is currently where many in-house “private” cloud efforts struggle; they may have virtualization, but struggle to make it fully self-service.
Cloud services have refined into at least three major models:
-
Infrastructure as a service
-
Platform as a service
-
Software as a service
There are cloud services beyond those listed above (e.g.,Storage as a Service). Various platform services have become extensive on providers such as Amazon, which offers load balancing, development pipelines, various kinds of storage, and much more.
|
Note
|
Traditional managed services are sometimes called “your mess for less.” With cloud, you have to “clean it up first.” |
2.4.4. Containers and looking ahead
At this writing, two major developments in cloud computing are prominent:
-
The combination of cloud computing with paravirtualization, including technologies such as Docker
-
Containers are lighter weight than VMs
-
Virtualized Guest OS: Seconds to instantiate
-
Container: Milliseconds (!)
-
-
Containers must be the same OS as host
-
-
AWS Lambda, “a compute service that runs your code in response to events and automatically manages the compute resources for you, making it easy to build applications that respond quickly to new information.” More broadly, the name “serverless” has been applied to this style of computing.
It’s recommended you at least scan the links provided.
2.5. Infrastructure as code
So, what is infrastructure as code?
As cloud infrastructures have scaled, there has been an increasing need to configure many servers identically. Auto-scaling (adding more servers in response to increasing load) has become a widely used strategy as well. Both call for increased automation in the provisioning of IT infrastructure. It is simply not possible for a human being to be hands on at all times in configuring and enabling such infrastructures, so automation is called for.
In years past, infrastructure administrators relied on the ad hoc issuance of commands either at an operations console or via a GUI-based application. Shell scripts might be used for various repetitive processes, but administrators by tradition and culture were empowered to issue arbitrary commands to alter the state of the running system directly.
Infrastructure as code is an approach to infrastructure automation based on practices from software development. It emphasizes consistent, repeatable routines for provisioning and changing systems and their configuration. Changes are made to definitions and then rolled out to systems through unattended processes that include thorough validation. The premise is that modern tooling can treat infrastructure as if it were software and data. This allows people to apply software development tools such as Version Control Systems (VCS), automated testing libraries, and deployment orchestration to manage infrastructure. It also opens the door to exploit development practices such as Test-Driven Development (TDD), Continuous Integration (CI), and Continuous Delivery (CD) [191].
Infrastructure as Code: Managing Servers in the Cloud
2.5.1. Why infrastructure as code?
The following passage from The Phoenix Project (by Gene Kim, Kevin Behr, and George Spafford) captures some of the issues. The speaker is Wes, the infrastructure manager, who is discussing a troubleshooting scenario:
“Several months ago, we were three hours into a Sev 1 outage, and we bent over backward not to escalate to Brent. But eventually, we got to a point where we were just out of ideas, and we were starting to make things worse. So, we put Brent on the problem.” He shakes his head, recalling the memory, “He sat down at the keyboard, and it’s like he went into this trance. Ten minutes later, the problem is fixed. Everyone is happy and relieved that the system came back up. But then someone asked, ‘How did you do it?’ And I swear to God, Brent just looked back at him blankly and said, ‘I have no idea. I just did it.’” [153 p. 116].
Obviously, “close your eyes and go into a trance” is not a repeatable process. It is not a procedure or operation that can be archived and distributed across multiple servers. So, shell scripts or more advanced forms of automation are written and increasingly, all actual server configuration is based on such pre-developed specification. It is becoming more and more rare for a systems administrator to actually “log in” to a server and execute configuration-changing commands in an ad hoc manner (as Brent).
In fact, because virtualization is becoming so powerful, servers increasingly are destroyed and rebuilt at the first sign of any trouble. In this way, it is certain that the server’s configuration is as intended. This again is a relatively new practice.
Previously, because of the expense and complexity of bare-metal servers, and the cost of having them offline, great pains were taken to fix troubled servers. Systems administrators would spend hours or days troubleshooting obscure configuration problems, such as residual settings left by removed software. Certain servers might start to develop “personalities.” Industry practice has changed dramatically here since around 2010. See the "Cattle not pets?" sidebar.
2.5.2. A simple infrastructure as code example
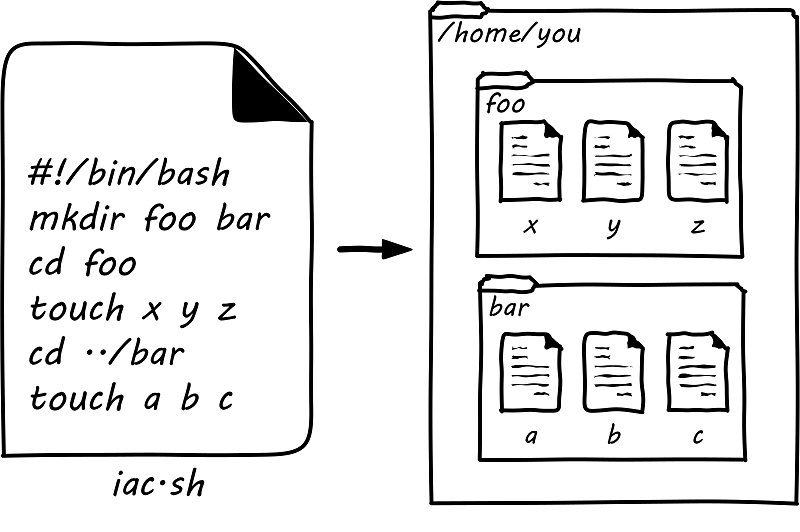
Note: the below part is illustrative only, and is not intended as a lab. The associated lab for this book goes into depth on these topics.
In presenting infrastructure as code at its simplest, we will start with the concept of a shell script. While this is not a deep Linux book (there are many others out there, starting with the excellent O’Reilly lineup), some basic technical literacy is assumed in this book. Consider the following set of commands:
$ mkdir foo bar $ cd foo $ touch x y z $ cd ../bar $ touch a b c
What does this do? It tells the computer:
-
Create (
mkdir) two directories, one named foo and one named bar -
Move (
cd) to the one named foo -
Create (
touch) three files, named x, y, and z -
Move to the directory named bar
-
Create three blank files, named a, b, and c
If you find yourself (with the appropriate permissions) at a UNIX or Linux command prompt, and run those commands, you will wind up with a configuration that could be visualized as in Simple directory/file structure script. (If you don’t understand this, you should probably spend a couple hours with a Linux tutorial).
Configuration, you ask? Something this trivial? Yes, directory and file layouts count as configuration and in some cases are critical. Now, what if we take that same set of commands, and put them in a text file thus:
#!/bin/bash mkdir foo bar cd foo touch x y z cd ../bar touch a b c
We might name that file iac.sh, set its permissions correctly, and run it (so that the computer executes all the commands for us, rather than us running them one at a time at the console). If we did so in an empty directory, we’d again wind up with that same configuration. (If we did it in a directory already containing foo and bar directories, we’d get errors. More on this to come).
|
Note
|
The state of the art in infrastructure configuration is not to use shell scripts at all but rather policy-based infrastructure management approaches, which we discuss subsequently. |
This may be familiar material to some of you, including the fact that beyond creating directories and files we can use shell scripts to create and destroy virtual servers, install and remove software, set up and delete users, check on the status of running processes, and much more.
Sophisticated infrastructure as code techniques are an essential part of modern site reliability engineering practices such as those used by Google. Auto-scaling, self-healing systems, and fast deployments of new features all require that infrastructure be represented as code for maximum speed and reliability of creation. For further information and practical examples, see Infrastructure as Code by Kief Morris [191].
Let’s return to our iac.sh file. It’s valuable. It documents our intentions for how this configuration should look. We can reliably run it on thousands of machines, and it will always give us two directories and six files. In terms of the previous section, we might choose to run it on every new server we create. We want to establish it as a known resource in our technical ecosystem. This is where version control and the broader concept of configuration management come in.
In earlier times, servers (that is, computers managed on a distributed network) were usually configured without virtualization. They arrived (carefully packed on pallets) from the manufacturer unconfigured, and would be painstakingly “built” by the systems administrator: the OS would be compiled and installed, key software packages (such as Java) installed, and then the organization’s customer software installed.
At best, the systems administrators, or server engineers, might have written guidelines, or perhaps some shell scripts, that would be run on the server to configure it in a semi-consistent way. But that documentation would often be out of date, the scripts would be unique to a given administrator, and there would be great reluctance to “rebuild the box” — that is, to delete everything on it and do a “clean re-install.” Instead, if there were problems, the administrator would try to fix the server by going in and adjusting particular settings (typically by changing configuration files and restarting services), or deleting software packages and re-installing them.
The problem with this is that modern computing systems are so complex that deleting software can be difficult. For example, if the un-install process fails in some way, the server can be left in a compromised state. Similarly, one-time configuration adjustments made to one server means that it may be inconsistent with similar devices, and this can cause problems. For example, if the first systems administrator is on vacation, their substitute may expect the server to be configured in a certain way and make adjustments that have unexpected effects. Or the first systems administrator themselves may forget, exactly, what it is they did. Through such practices, servers would start to develop personalities, because their configurations were inconsistent.
As people started to work more and more with virtualization, they realized it was easier to rebuild virtual servers from scratch, rather than trying to fix them. Automated configuration management tools helped by promoting a consistent process for rebuilding. Randy Bias, noting this, put forth the provocative idea that “servers are cattle, not pets” [29]. That is, when a pet is sick, one takes it to the vet, but a sick cow might simply be put to death.
A more compassionate image might be to say that “servers are fleet vehicles, not collectible cars” (see Collectible car versus fleet vehicles [7]) The cattle metaphor also overlooks the fact that large animal veterinarians are routinely employed in the cattle industry.

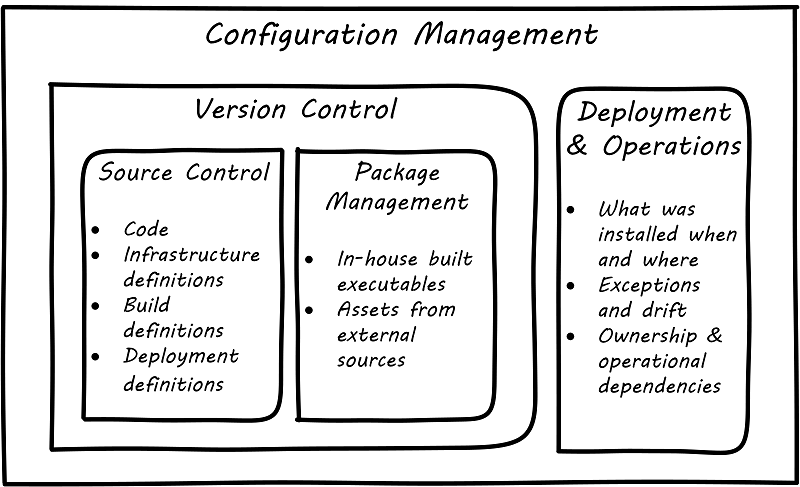
2.6. Configuration management: the basics
Configuration management is, and has always been, a critically important practice in digital systems. How it is performed has evolved over time. At this stage in our journey, we are a one or two people startup, working with digital artifacts such as our iac.sh example discussed in the previous section.
One or two people can achieve an impressive amount with modern digital platforms. But, the work is complex. Tracking and controlling your work products as they evolve through change after change is important from day one of your efforts. It’s not something you want to put off to “later when I have time.” This applies to computer code, configurations, and increasingly, documentation, which is often written in a lightweight markup language like Markdown or Asciidoc. In terms of infrastructure, configuration management requires three capabilities:
-
The ability to backup or archive a system’s operational state (in general, not including the data it is processing — that is a different concern). Taking the backup should not require taking the system down.
-
The ability to compare two versions of the system’s state and identify differences.
-
The ability to restore the system to a previously archived operational state.
In this section, we will discuss the following topics:
-
Version control
-
Source control
-
Package management
-
Deployment management
-
Configuration management
and their relationships.
2.6.1. What is version control?
In software development, version control is the foundation of every other Agile technical practice. Without version control, there is no build, no TDD, no continuous integration [11 p. 6013].
Web Operations: Keeping the Data On Time
The Agile Alliance indicates “version control” as one of the four foundational areas of Agile [8], along with the team, iterative development, and incremental development. Why is this? Version control is critical for any kind of system with complex, changing content, especially when many people are working on that content. Version control provides the capability of seeing the exact sequence of a complex system’s evolution and isolating any particular moment in its history or providing detailed analysis on how two versions differ. With version control, we can understand what changed and when – which is essential to coping with complexity.
While version control was always deemed important for software artifacts, it has only recently become the preferred paradigm for managing infrastructure state as well. Because of this, version control is possibly the first IT management system you should acquire and implement (perhaps as a cloud service, such as Github).
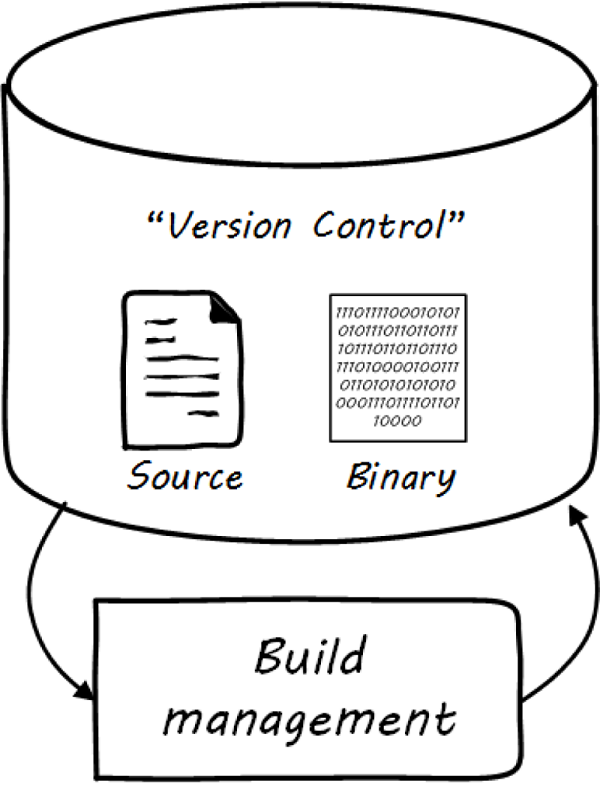
Version control in recent years increasingly distinguishes between source control and package management (see Types of version control and Configuration management and its components below): the management of binary files, as distinct from human-understandable symbolic files. It is also important to understand what versions are installed on what computers; this can be termed “deployment management.” (With the advent of containers, this is a particularly fast changing area).
Version control works like an advanced file system with a memory. (Actual file systems that do this are called versioning file systems). It can remember all the changes you make to its contents, tell you the differences between any two versions, and also bring back the version you had at any point in time. Version control is important — but how important? Survey research presented in the annual State of DevOps report indicates that version control is one of the most critical practices associated with high performing IT organizations [38]. Nicole Forsgren [94] summarizes the practice of version control as:
-
Our application code is in a version control system
-
Our system configurations are in a version control system
-
Our application configurations are in a version control system
-
Our scripts for automating build and configuration are in a version control system
Source control
Digital systems start with text files, e.g., those encoded in ASCII or Unicode. Text editors create source code, scripts, and configuration files. These will be transformed in defined ways (e.g.,by compilers and build tools) but the human understandable end of the process is mostly based on text files. In the previous section, we described a simple script that altered the state of a computer system. We care very much about when such a text file changes. One wrong character can completely alter the behavior of a large, complex system. Therefore, our configuration management approach must track to that level of detail.
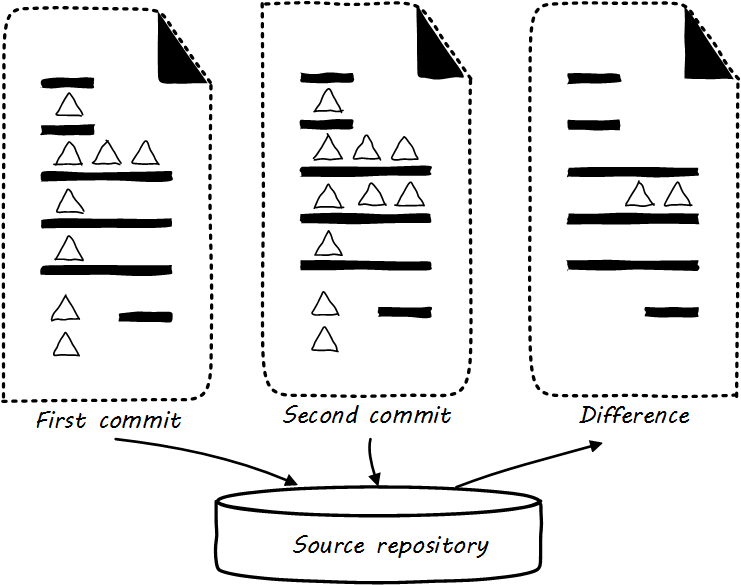
Source control is at its most powerful when dealing with textual data. It is less useful in dealing with binary data, such as image files. Text files can be analyzed for their differences in an easy to understand way (see Source control). If I change “abc” to “abd,” then it is clear that the third character has been changed from “c” to “d.” On the other hand, if I take a picture (e.g.,as a *.png file) and alter one pixel, and compare the resulting before and after binary files in terms of their data, it would be more difficult to understand what had changed. I might be able to tell that they are two different files easily, but they would look very similar, and the difference in the binary data might be difficult to understand.
Here is a detailed demonstration, using the command line in Ubuntu Linux. (Don’t worry, we will explain what is going on).
|
Note
|
In the below sequence, what you see after the "$” sign is what is being typed. If there is no "$” sign, it is what the system is saying in response. |
First, we create a directory (similar to the iac.sh example script):
~$ mkdir tmpgit
Then, we navigate to it:
~$ cd tmpgit/
And activate git source control:
~/tmpgit$ git init Initialized empty Git repository in /home/char/tmpgit/.git/
We create a simple program:
~/tmpgit$ echo 'print “hello world!";' > tmp.py
And run it:
~/tmpgit$ python tmp.py hello world!
We stage it for source control:
~/tmpgit$ git add . tmp.py
And commit it:
~/tmpgit$ git commit -m “first commit” [master (root-commit) cabdbe3] first commit 1 file changed, 1 insertion(+) create mode 100644 tmp.py
The file is now under version control. We can change our working copy and run it:
~/tmpgit$ echo 'print “hello universe!";' > tmp.py ~/tmpgit$ python tmp.py hello universe!
When the “echo” command is run with just one ">” it replaces the data in the target file completely. So we have completely replaced “hello world!” with “hello universe!”
And — most critically — we can see what we have changed!
~/tmpgit$ git diff diff --git a/tmp.py b/tmp.py index 0ecbd83..a203522 100644 --— a/tmp.py +++ b/tmp.py @@ -1 +1 @@ -print “hello world!"; +print “hello universe!";
Notice the "-” (minus) sign before the statement 'print “hello world!";' -— that means that line has been deleted. The "+” (plus) sign before 'print “hello universe!";' means that line has been added.
We can restore the original file (note that this eradicates the working change we made!)
char@elsa:~/tmpgit$ git checkout . char@elsa:~/tmpgit$ python tmp.py hello world!
If you have access to a computer, try it! (You will need to install git, and if you are on Windows you should use WSL, the Windows Subsystem for Linux).
In comparison, the following are two 10x10 gray-scale bitmap images being edited in the Gimp image editor. They are about as simple as you can get. Notice (in Two bitmaps) that they are slightly different.
If we save these in the Portable Network Graphics (*.png) format, we can see they are different sizes (242 k _versus_239k). But if we open them in a binary editor it is very difficult to understand how they differ (compare First file binary data with Second file binary data).
Even if we analyzed the differences, we would need to know much about the .png format in order to understand how the two images differ. We can still track both versions of these files, of course, with the proper version control. But again, binary data is not ideal for source control tools like git.
The “commit” concept
Although implementation details may differ, all version control systems have some concept of “commit.” As stated in Version Control with Git [173]:
In Git, a commit is used to record changes to a repository … Every Git commit represents a single, atomic changeset with respect to the previous state. Regardless of the number of directories, files, lines, or bytes that change with a commit … either all changes apply, or none do. [emphasis added]
|
Note
|
Why “atomic"? The word atomic derives from the ancient Latin language, and means “indivisible.” An atomic set of changes is either entirely applied, or entirely rejected. Atomicity is an important concept in computing and transaction processing, in particular. If our user tries to move money from her savings to her checking account, two operations are required: (1) reduce savings and (2) increase checking. Either both need to succeed, or both need to fail. That is the classic definition of an “atomic” transaction. Version control commits should be atomic. |
The concept of a version or source control “commit” is a rich foundation for IT management and governance. It both represents the state of the computing system as well as providing evidence of the human activity affecting it. As we will see in Chapter 3, the “commit” identifier is directly referenced by build activity, which in turn is referenced by the release activity, which is typically visible across the IT value chain.
Also, the concept of an atomic “commit” is essential to the concept of a “branch” -— the creation of an experimental version, completely separate from the main version, so that various alterations can be tried without compromising the overall system stability. Starting at the point of a “commit,” the branched version also becomes evidence of human activity around a potential future for the system. In some environments, the branch is automatically created with the assignment of a requirement or story -— again, more on this to come in chapter 3. In other environments, the very concept of branching is avoided.
2.6.2. Package management
Implement version control for all production artifacts. [215]
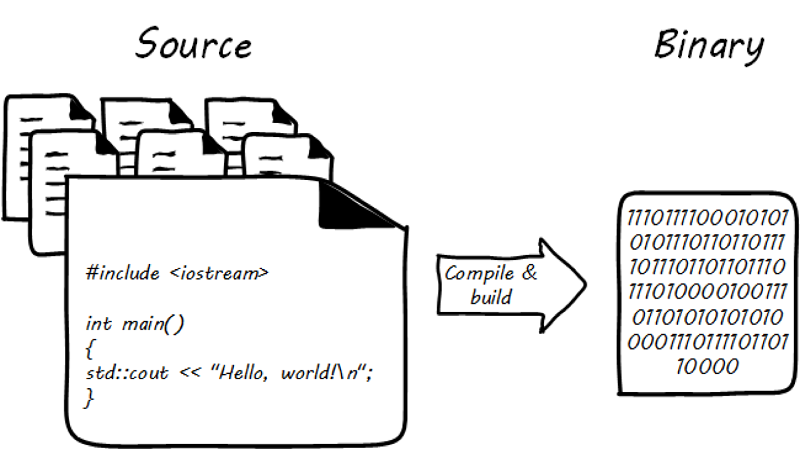
Much if not most software, once created as some kind of text-based artifact suitable for source control, must be compiled and further organized into deployable assets, often called “packages” (see Building software).
In some organizations, it was once common for compiled binaries to be stored in the same repositories as source code (see Common version control). However, this is no longer considered a best practice. Source and package management are now viewed as two separate things (see Source versus package repos). Source repositories should be reserved for text-based artifacts whose differences can be made visible in a human-understandable way. Package repositories in contrast are for binary artifacts that can be deployed.
Package repositories also can serve as a proxy to the external world of downloadable software. That is, they are a cache, an intermediate store of the software provided by various external or “upstream” sources. For example, developers may be told to download the approved Ruby on Rails version from the local package repository, rather than going to get the latest version, which may not be suitable for the environment.
Package repositories furthermore are used to enable collaboration between teams working on large systems. Teams can check in their built components into the package repository for other teams to download. This is more efficient than everyone always building all parts of the application from the source repository.
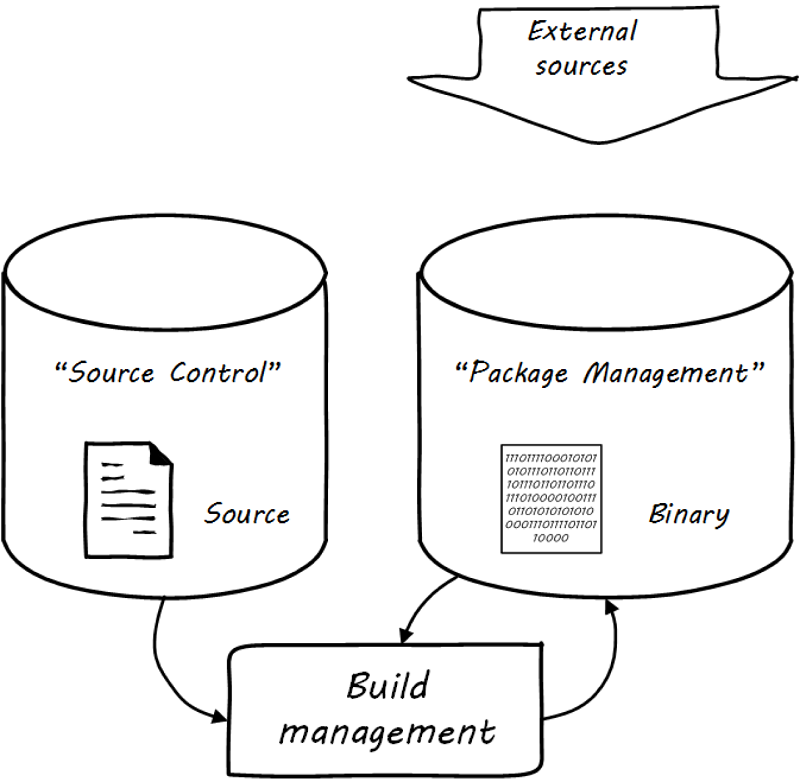
The boundary between source and package is not hard and fast, however. One sometimes sees binary files in source repositories, such as images used in an application. Also, when interpreted languages (such as JavaScript) are “packaged,” they still appear in the package as text files, perhaps compressed or otherwise incorporated into some larger containing structure.
2.6.3. Deployment management
Version control is an important part of the overall concept of configuration management. But configuration management also covers the matter of how artifacts under version control are combined with other IT resources (such as VMs) to deliver services. Configuration management and its components elaborates on Types of version control to depict the relationships.
Deployment basics
Resources in version control in general are not yet active in any value-adding sense. In order for them to deliver experiences, they must be combined with computing resources: servers (physical or virtual), storage, nettworking, and the rest, whether owned by the organization or leased as cloud services. The process of doing so is called deployment. Version control manages the state of the artifacts; meanwhile, deployment management (as another configuration management practice) manages the combination of those artifacts with the needed resources for value delivery.
Imperative and declarative
Before we turned to source control, we looked at a simple script that changed the configuration of a computer. It did so in an imperative fashion. Imperative and declarative are two important terms from computer science.
In an imperative approach, we tell the computer specifically how we want to accomplish a task, e.g.:
-
Create a directory
-
Create some files
-
Create another directory
-
Create more files
Many traditional programming languages take an imperative approach. A script such as our iac.sh example is executed line by line, i.e., it is imperative. In configuring infrastructure, scripting is in general considered “imperative,” but state of the art infrastructure automation frameworks are built using a “declarative,” policy-based approach, in which the object is to define the desired end state of the resource, not the steps needed to get there. With such an approach, instead of defining a set of steps, we simply define the proper configuration as a target, saying (in essence) that “this computer should always have a directory structure thus; do what you need to do to make it so and keep it this way.”
More practically, declarative approaches are used to ensure that the proper versions of software are always present on a system and that configurations such as Internet ports and security settings do not vary from the intended specification.
This is a complex topic, and there are advantages and disadvantages to each approach. (See “When and Where Order Matters” by Mark Burgess for an advanced discussion [43]). But policy-based approaches seem to have the upper hand for now.
2.7. Topics in IT infrastructure
This and the following chapters in this book will end with a “topics” section, in which current and specialized developments will be discussed.
2.7.1. Configuration management, version control, and metadata
Version control, in particular, source control, is where we start to see the emergence of an architecture of IT management. It is in the source control system that we first start to see metadata emerge as an independent concern. Metadata is a tricky term, that tends to generate confusion. The term “meta” implies a concept that is somehow self-referential, and/or operating at a higher-level of abstraction. So,
-
The term meta-discussion is a discussion about the discussion
-
Meta-cognition is cognition about cognition
-
Metadata (aka metadata) is data about data
Some examples:
-
In traditional data management, metadata is the description of the data structures, especially from a business point of view. A database column might be named “CUST_L_NM,” but the business description or metadata would be “the last, family, or surname of the customer.”
-
In document management, the document metadata is the record of who created the document and when, when it was last updated, and so forth. Failure to properly sanitize document metadata has led to various privacy and data security-related issues.
-
In telephony, “data” is the actual call signal — the audio of the phone conversation, nowadays usually digitally encoded. Metadata, on the other hand, is all the information about the call: from whom to who, when, how long, and so forth.
In computer systems, metadata can be difficult to isolate. Sometimes, computing professionals will speak of a “metadata” layer that may define physical database structures, data extracts, business process behavior, even file locations. The trouble is, from a computer’s point of view, a processing instruction is an instruction, and the prefix “meta” has no real meaning.
Because of this, this book favors a principle that metadata is by definition non-runtime. It is documentation, usually represented as structured or semi-structured data, but not usually a primary processing input or output. It might be “digital exhaust” — log files are a form of metadata. It is not executable. If it’s executable (directly or indirectly), it’s digital logic or configuration, plain and simple.
So what about our infrastructure as code example? The artifact — the configuration file, the script — is NOT metadata, because it is executable. But the source repository commit IS metadata. It has no meaning for the script. The dependency is one-way — without the artifact, the commit ID is meaningless, but the artifact is completely ignorant of the commit. The commit may become an essential data point for human beings trying to make sense of the state of a resource defined by that artifact. However, as Loeliger notes in Version control with Git, the version control system:
…doesn’t care why files are changing. That is, the content of the changes doesn’t matter. As the developer, you might move a function from here to there and expect this to be handled as one unitary move. But you could, alternatively, commit the removal and then later commit the addition. Git doesn’t care. It has nothing to do with the semantics of what is in the files" [173].
In this microcosm, we see the origins of IT management. It is not always easy to apply this approach in practice. There can be edge cases. Documentation stored in version control needs to be seen as “executable” in the context of the business process. But, it also does not require or “know about” the commit. Ultimately, the concept of metadata provides a basis for distinguishing the management of IT from the actual application of IT.
2.8. Conclusion
Books and articles are written every week about some aspect of IT and digital infrastructure. We have only scratched the surface in our discussions of computing, network, and storage, and how they have become utility services in the guise of cloud. Software as a Service, Platform as a Service, Infrastructure as a Service -— each represents a different approach. For the most part, we will focus on infrastructure as a service in the remainder of this book, on the assumption that your digital product is unique enough to need the broad freedom this provides.
Digital infrastructure is a rich and complex topic, and a person can spend their career specializing in it. For this class, we always want to keep the key themes of Chapter 1 in mind: why do we want it? How does it provide for our needs, contribute to our enjoyment?
There are numerous sources available to you to learn Linux, Windows, scripting, policy-based configuration management of infrastructure, and source control. Competency with source control is essential to your career, and you should devote some serious time to it. You can find many references to source control on the Internet and in books such as Pro Git by Scott Chacon and Ben Straub [56]. Since source control is the most important foundational technology for professional IT -– whether in a garage start-up or in the largest organizations –— you need to have a deep familiarity with it.
We will discuss further infrastructure issues in Chapter 6, including designing systems for failure and availability.
2.8.1. Discussion questions
-
Consider your product idea from the previous chapter. Does it have any particular infrastructure needs you can identify, having read this chapter?
-
Your personal laptop or smartphone is infrastructure. What issues have you had with it? Have you had to change its configuration?
-
Would you prefer to build your product on an IaaS or PaaS platform (see the cloud models)? Is there an SaaS product that might be of service? (If so, what is your value-adding idea?)
-
Compare the costs of cloud to owning your own server. Assume you buy a server inexpensively on Ebay and put it in your garage. What other factors might you consider before doing this?
2.8.2. Research & practice
-
Research cloud providers and recommend on which you would prefer to build your new product on.
-
Interview someone who has worked in a data center as to what a “day in the life” is, and how it’s changed for them.
-
Install Vagrant and VirtualBox on your personal device and bring up a Linux VM. Run a Linux tutorial.
-
Configure a declarative infrastructure manager (Chef, Puppet, Ansible, or SaltStack) to control your Vagrant VMs. Use Git to control your configurations.
-
Install Docker and run a tutorial on it.
2.8.3. Further reading
Books
-
Thomas A. Limoncelli, Strata R. Chalup, Christina J. Hogan, The Practice of Cloud System Administration: Designing and Operating Large Distributed Systems, Volume 2
-
John Allspaw, Web Operations: Keeping the Data On Time
-
Kief Morris, Infrastructure as Code: Managing Servers in the Cloud
-
Ellen Siever, Stephen Figgins, Robert Love, Arnold Robbins, Aaron Weber, Linux in a Nutshell
-
Scott Chacon, Pro Git
-
Mark Burgess, Analytical Network and System Administration: Managing Human-Computer Systems (exceptionally deep and rigorous book by a trained physicist on using mathematical methods to understand computing infrastructure problems)
Articles