3. Application Delivery
3.1. Introduction
Now that we have some idea of IT value (and how we might turn it into a product), and have decided on some infrastructure, we can start building.
IT systems that directly create value for non-technical users are usually called “applications,” or sometimes “services.” As discussed in Chapter 1, they enable value experiences in areas as diverse as consumer banking, entertainment and hospitality, and personal transportation. In fact, it is difficult to think of any aspect of modern life untouched by applications. (This overall trend is sometimes called digital transformation [281]).
Applications are built from software, the development of which is a core concern for any IT-centric product strategy. Software development is a well established career, and a fast-moving field with new technologies, frameworks, and schools of thought emerging weekly, it seems. This chapter will cover applications and the software lifecycle, from requirements through construction, testing, building, and deployment of modern production environments. It also discusses earlier approaches to software development, the rise of the Agile movement, and its current manifestation in the practice of DevOps.
3.1.1. Chapter outline
-
Introduction
-
Learning objectives
-
Basics of applications and their development
-
Defining “application”
-
History of applications and application software
-
Applications and infrastructure: the old way
-
Applications and infrastructure today
-
-
From waterfall to Agile
-
The DevOps challenge
-
Describing system intent
-
Test-driven development and refactoring
-
Test-driven development
-
Refactoring
-
-
Continuous integration
-
Continuous deployment
-
Application development topics
-
Conclusion
-
Discussion questions
-
Research & practice
-
Further reading
-
3.1.2. Learning objectives
-
Understand history and importance of “application” concept
-
Define “Agile” in terms of software development
-
Identify key Agile practices
-
Identify the major components of an end-to-end DevOps delivery pipeline
3.2. Basics of applications and their development
3.2.1. Defining “application”
In keeping with our commitment to theory and first principles, we use an engineering definition of “application.” To an electrical engineer, a toaster or a light bulb is an “application” of electricity (hence the term “appliance”). Similarly, a customer relationship management system, or a Web video on-demand service, are “applications” of the computing infrastructure we studied in the last chapter.
3.2.2. History of applications and application software
Without applications, computers would be merely a curiosity. Electronic computers were first “applied” to military needs for codebreaking and artillery calculations. After World War II, ex-military officers like Edmund Berkeley at Prudential realized computers' potential if “applied” to problems like insurance record keeping [9]. At first, such systems required actual manual configuration (see The ENIAC -— “programmed” by cable reconfiguration. [1]), or painstaking programming in complex, tedious, and unforgiving low-level programming languages. As the value of computers became obvious, investment was made in making programming easier through more powerful languages.

The history of software is well documented. Low-level languages (binary and assembler) were increasingly replaced by higher-level languages such as FORTRAN, COBOL, and C. Proprietary machine/language combinations were replaced by open standards and compilers that could take one kind of source code and build it for different hardware platforms. Many languages followed, such as Java, Visual Basic, and JavaScript. Extensive middleware was developed to enable ease of programming, communication across networks, and standardize common functions.
Today, we have extensive frameworks like Apache Struts, Spring, and Ruby on Rails, along with interpreted languages that take much of the friction out of building and testing code. But even today, the objective remains to create a binary executable file or files that computer hardware can “execute,” that is, turn into a computing-based value experience, mediated through devices such as workstations, laptops, smartphones, and their constituent components.
3.2.3. Applications and infrastructure: the old way
In the first decades of computing, any significant application of computing power to a new problem typically required its own infrastructure, often designed specifically for the problem. While awareness existed that computers, in theory, could be “general-purpose,” in practice, this was not so easy. Military/aerospace needs differed from corporate information systems, which differed from scientific and technical uses. And major new applications required new compute capacity.
Take for example when a large organization in 1998 decided to replace its mainframe Human Resources system due to Y2K concerns. Such a system might need to support several thousand users around the world. At that time, PeopleSoft was a frequent choice of software. Implementing such a system was often led by consulting firms such as Deloitte or Andersen Consulting (where one of the authors worked). A typical PeopleSoft package implementation would include:
-
PeopleSoft software, including the PeopleTools framework and various modules written in the framework (e.g.,the well-regarded PeopleSoft HR system)
-
Oracle database software
-
AT&T “Tuxedo” transaction manager
-
Autosys job scheduler
-
HP-UX servers, perhaps 20 or so, comprising various “environments” including a production “cluster” consisting of application and database servers
-
EMC storage array
-
Various ancillary software and hardware: management utilities and scripts, backup, networking, etc.
-
Customization of the PeopleSoft HR module and reports by hired consultants, to meet the requirements of the acquiring organization
The software and hardware needed to be specified in keeping with requirements, and acquiring it took lengthy negotiations and logistics and installation processes. Such a project from inception to production might take 9 months (on the short side) to 18 or more months.
Hardware was dedicated and rarely re-used. The HP servers compatible with PeopleSoft might have few other applications if they became surplus. In fact, PeopleSoft would “certify” the infrastructure for compatibility. Upgrading the software might require also upgrading the hardware. In essence, this sort of effort had a strong component of systems engineering, as designing and optimizing the hardware component was a significant portion of the work.
3.2.4. Applications and infrastructure today
Today, matters are quite different, and yet echoes of the older model persist. As mentioned, ANY compute workloads are going to incur economic cost. However, capacity is being used more efficiently and can be provisioned on-demand. Currently, it is a significant application indeed that merits its own systems engineering.
|
Note
|
To “provision” in an IT sense means to make the needed resources or services available for a particular purpose or consumer. |
Instead, a variety of mechanisms (as covered in the previous chapter’s discussion of cloud systems) enable the sharing of compute capacity, the raw material of application development. The fungibility and agility of these mechanisms increase the velocity of creation and evolution of application software. For small and medium sized applications, the overwhelming trend is to virtualize and run on commodity hardware and operating systems. Even 15 years ago, non-trivial websites with database integration would be hosted by internal PaaS clusters at major enterprises (for example, Microsoft ASP, COM+, and SQL Server clusters could be managed as multi-tenant -— the author wrote systems on such a platform).
The general-purpose capabilities of virtualized public and private cloud today are robust. Assuming the organization has the financial capability to purchase computing capacity in anticipation of use, it can be instantly available when the need surfaces. Systems engineering at the hardware level is more and more independent of the application lifecycle; the trend is towards providing compute as a service, carefully specified in terms of performance, but NOT particular hardware. Hardware physically dedicated to a single application is rarer, and even the largest engineered systems are more standardized so that they may one day benefit from cloud approaches. Application architectures have also become much more powerful. Interfaces (interaction points for applications to exchange information with each other, generally in an automated way) are increasingly standardized. Applications are designed to scale dynamically with the workload and are more stable and reliable than in years past.
In the next section, we will discuss how the practices of application development have evolved to their current state.
3.3. From waterfall to Agile
This is not a book on software development per se, nor on Agile development. There are hundreds of books available on those topics. But, no assumption is made that the reader has any familiarity with these topics, so some basic history is called for. (If you have taken an introductory course in software engineering, this will likely be a review).
For example, when a new analyst would join the systems integrator Andersen Consulting (now Accenture) in 1998, they would be schooled in something called the Business Integration Method (BIM). The BIM was a classic expression of what is called “waterfall development."
What is waterfall development? It is a controversial question. Walker Royce, the original theorist who coined the term named it in order to critique it [230]. Military contracting and management consultancy practices, however, embraced it, as it provided an illusion of certainty. The fact that computer systems until recently included a substantial component of hardware systems engineering may also have contributed.
Waterfall development as a term has become associated with a number of practices. The original illustration was similar to Waterfall lifecycle footnote:[similar to [230]):
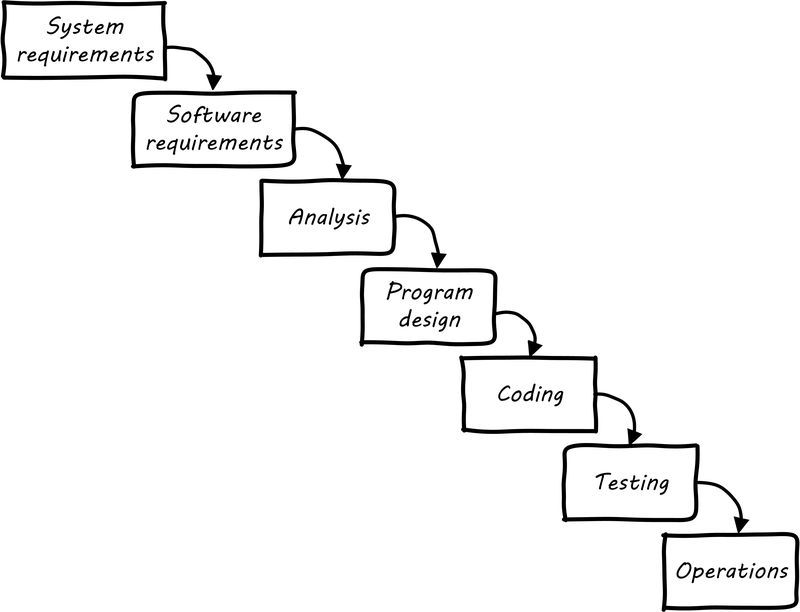
First, requirements need to be extensively captured and analyzed before the work of development can commence. So, the project team would develop enormous spreadsheets of requirements, spending weeks on making sure that they represented what “the customer” wanted. The objective was to get the customer’s signature. Any further alterations could be profitably billed as “change requests.”
The analysis phase was used to develop a more structured understanding of the requirements, e.g., conceptual and logical data models, process models, business rules, and so forth.
In the design phase, the actual technical platforms would be chosen; major subsystems determined with their connection points, initial capacity analysis (volumetrics) translated into system sizing, and so forth. (Perhaps hardware would not be ordered until this point, leading to issues with developers now being “ready,” but hardware not being available for weeks or months yet).
Only AFTER extensive requirements, analysis, and design would coding take place (implementation). Furthermore, there was a separation of duties between developers and testers. Developers would write code and testers would try to break it, filing bug reports that the developers would then need to respond to.
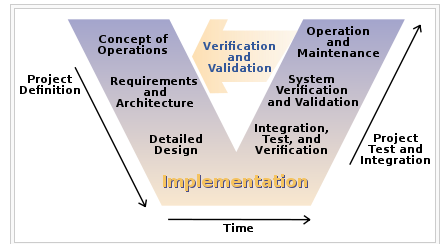
Another model sometimes encountered at this time was the V-model (see V-model [2]). This was intended to better represent the various levels of abstraction operating in the systems delivery activity. Requirements operate at various levels, from high-level business intent through detailed specifications. It is all too possible that a system is “successfully” implemented at lower levels of specification, but fails to satisfy the original higher-level intent.
The failures of these approaches at scale are by now well known. Large distributed teams would wrestle with thousands of requirements. The customer would “sign off” on multiple large binders, with widely varying degrees of understanding of what they were agreeing to. Documentation became an end in itself and did not meet its objectives of ensuring continuity if staff turned over. The development team would design and build extensive product implementations without checking the results with customers. They would also defer testing that various component parts would effectively interoperate until the very end of the project, when the time came to assemble the whole system.
Failure after failure of this approach is apparent in the historical record [107]. Recognition of such failures, dating from the 1960s, led to the perception of a “software crisis.” (However, many large systems were effectively constructed and operated during the “waterfall years," and there are reasonable criticisms of the concept of a “software crisis” [34]).
Successful development efforts existed back to the earliest days of computing (otherwise, we probably wouldn’t have computers, or at least not so many). Many of these successful efforts used prototypes and other means of building understanding and proving out approaches. But highly publicized failures continued, and a substantial movement against “waterfall” development started to take shape.
By the 1990s, a number of thought leaders in software development had noticed some common themes with what seemed to work and what didn’t. Kent Beck developed a methodology known as “eXtreme Programming” (XP) [19]. XP pioneered the concepts of iterative, fast-cycle development with ongoing stakeholder feedback, coupled with test-driven development, ongoing refactoring, pair programming, and other practices. (More on the specifics of these in the next section).
Various authors assembled in 2001 and developed the Agile Manifesto [6], which further emphasized an emergent set of values and practices:
The Manifesto authors further stated:
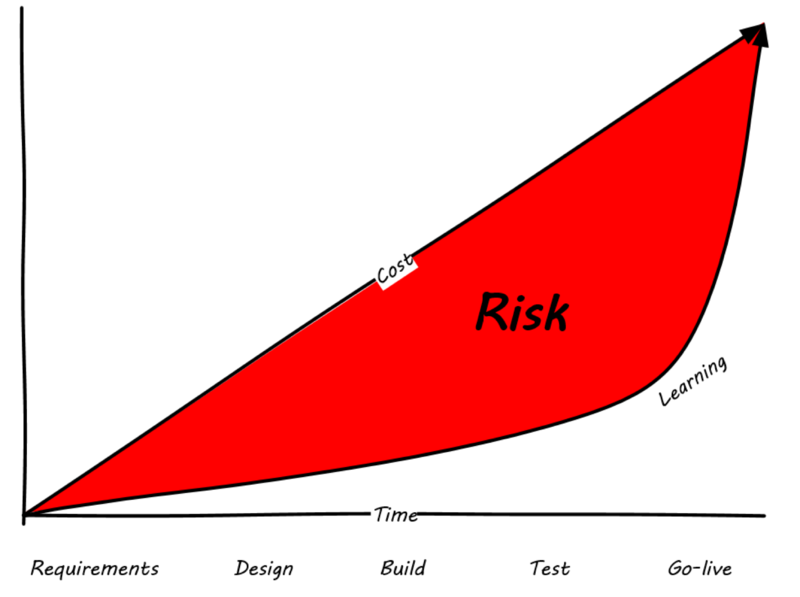
Agile methodologists emphasize that software development is a learning process. In general, learning (and the value derived from it) is not complete until the system is functioning to some degree of capability. As such, methods that postpone the actual, integrated verification of the system increase risk. Alistair Cockburn visualizes risk as the gap between the ongoing expenditure of funds and the lag in demonstrating valuable learning (see Waterfall risk [3]).
Because Agile approaches emphasize delivering smaller batches of complete functionality, this risk gap is minimized (Agile risk [4]).
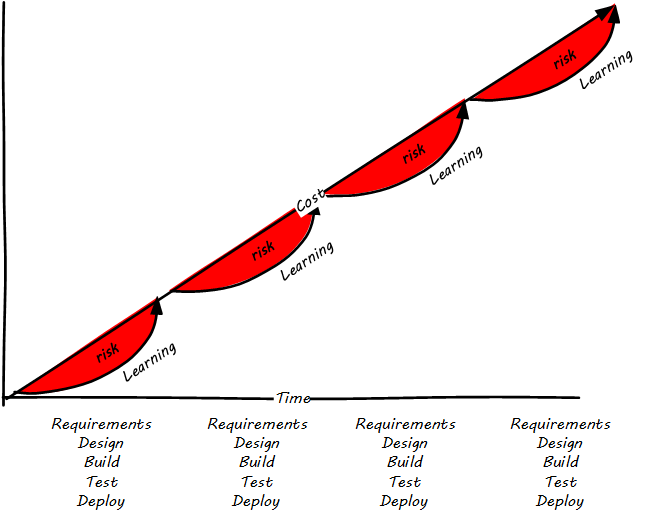
The Agile models for developing software aligned with the rise of cloud and Web-scale IT. As new customer-facing sites like Flickr, Amazon, Netflix, Etsy, and Facebook scaled to massive proportions, it became increasingly clear that waterfall approaches were incompatible with their needs. Because these systems were directly user-facing, delivering monetized value in fast-moving competitive marketplaces, they required a degree of responsiveness previously not seen in “back-office” IT or military-aerospace domains (the major forms that large scale system development had taken to date). We will talk more of product-centricity and the overall DevOps movement in the next section.
This new world did not think in terms of large requirements specifications. Capturing a requirement, analyzing and designing to it, implementing it, testing that implementation, and deploying the result to the end user for feedback became something that needed to happen at speed, with high repeatability. Requirements “backlogs” were (and are) never “done,” and increasingly were the subject of ongoing re-prioritization, without high-overhead project “change” barriers.
These user-facing, web-based systems integrate the software development lifecycle tightly with operational concerns. The sheer size and complexity of these systems required much more incremental and iterative approaches to delivery, as the system can never be taken offline for the “next major release” to be installed. New functionality is moved rapidly in small chunks into a user-facing, operational status, as opposed to previous models where vendors would develop software on an annual or longer version cycle, to be packaged onto media for resale to distant customers.
Contract software development never gained favor in the Silicon Valley web-scale community; developers and operators are typically part of the same economic organization. So, it was possible to start breaking down the walls between “development” and “operations,” and that is just what happened.
Large scale systems are complex and unpredictable. New features are never fully understood until they are deployed at scale to the real end user base. Therefore, large scale web properties also started to “test in production” (more on this in Chapter 6) in the sense that they would deploy new functionality to only some of their users. Rather than trying to increase testing to understand things before deployment better, these new firms accepted a seemingly higher-level of risk in exposing new functionality sooner. (Part of their belief is that it actually is lower risk because the impacts are never fully understood in any event).
We’ll return to Agile and its various dimensions throughout the rest of this book. See [167] for a much more thorough history.
3.4. The DevOps challenge
Consider this inquiry by Mary and Tom Poppendieck:
The implicit goal is that the organization should be able to change and deploy one line of code, from idea to production, and in fact, might want to do so on an ongoing basis. There is deep Lean/Agile theory behind this objective; a theory developed in reaction to the pattern of massive software failures that characterized IT in the first 50 years of its existence. (We’ll discuss some of the systems theory, including the concept of feedback, in the introduction to Part II and other aspects of Agile theory, including the ideas of Lean Product Development, in Parts II and III).
Achieving this goal is feasible but requires new approaches. Various practitioners have explored this problem, with great success. Key initial milestones included:
-
The establishment of “test-driven development” as a key best practice in creating software [19]
-
Duvall’s book “Continuous Integration” [86]
-
Allspaw & Hammonds’s seminal “10 Deploys a Day” presentation describing Etsy [10]
-
Humble & Farley’s “Continuous Delivery” [128]
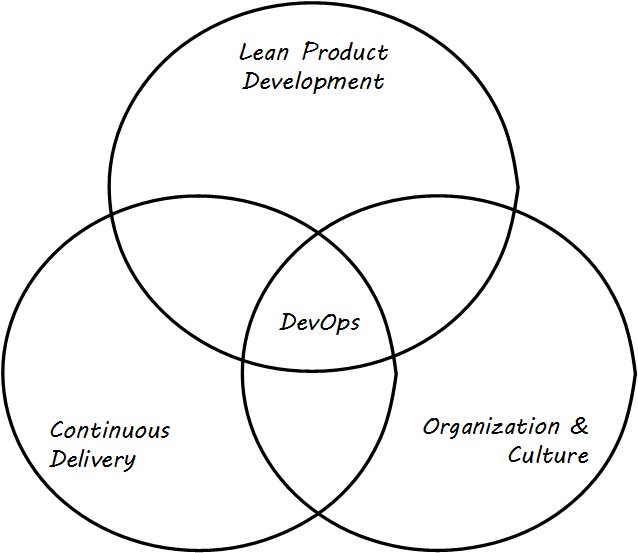
“DevOps” is a broad term, encompassing product management, continuous delivery, team behaviors, and culture (see DevOps definition). Some of these topics will not be covered until parts II and III in this book. At an execution level, the fundamental goal of moving smaller changes more quickly through the pipeline is a common theme. Other guiding principles include, “If it hurts, do it more frequently.” (This is in part a response to the poor practice, or antipattern, of deferring integration testing and deployment until those tasks are so big as to be unmanageable). There is a great deal written on the topic of DevOps currently; the Humble/Farley book is recommended as an introduction. Let’s go into a little detail on some essential Agile/DevOps practices.
-
Test-driven development
-
Ongoing refactoring
-
Continuous integration
-
Continuous deployment
In our scenario approach, at the end of the last chapter, you had determined a set of tools for creating your new IT-based product:
-
Development stack (language, framework, and associated enablers such as database and application server)
-
Cloud provider that supports your stack
-
Version control
-
Deployment capability
You’ll be creating text files of some sort, and almost certainly importing various additional libraries, packages, modules, etc., rather than solving problems others have already figured out.
|
Note
|
Development tools such as text editors and Integrated Development Environments (IDEs) are out of scope for this book, as they are often matters of personal choice and limited to developers’ desktops. |
The assumption in this chapter is that you are going to start IMMEDIATELY with a continuous delivery pipeline. You want to set this up before developing a single line of code. This is not something to “get around to later.” It’s not that difficult (see the online resources for further discussion and pointers to relevant open-source projects). What is meant by a continuous delivery pipeline? A simple continuous delivery toolchain presents a simplified, starting overview, based on the Calavera project developed for the IT Delivery course at the University of St. Thomas in St. Paul, Minnesota [27].
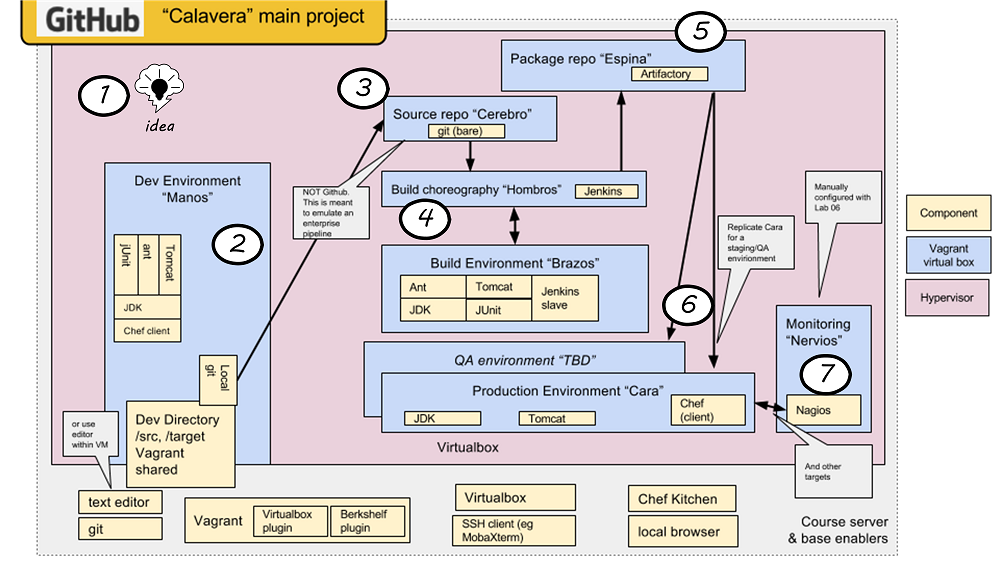
-
First, some potential for value is identified. It is refined through product management techniques into a feature — some specific set of functionality that when complete will enable the value proposition (i.e. as a moment of truth).
-
The feature is expressed as some set of IT work, today usually in small increments lasting between one and four weeks (this of course varies). Software development commences, e.g., the creation of Java components by developers who first write tests, and then write code that satisfies the test.
-
The developer is continually testing the software as the build progresses, and keeping a local source control repository up to date with their changes at all times. When a level of satisfaction is reached with the software, it is submitted to a centralized source repository.
-
When the repository detects the new “check-in,” it contacts the build choreography manager, which launches a dedicated environment to build and test the new code. The environment is likely configured using "infrastructure as code" techniques; in this way, it can be created automatically and quickly.
-
If the code passes all tests, the compiled and built binary executables may then be “checked in” to a package management repository.
-
From the package repository, the code may then be deployed to various environments, for further testing and ultimately to “production,” where it can enable the consumer’s value experiences.
-
Finally, the production system is monitored for availability and performance.
We will discuss DevOps in terms of team behaviors and culture later in the book. For now, we stay closer to the tactical and technical concerns of continuous delivery. Let’s go into more detail on the major phases.
3.5. Describing system intent
So, you’ve got an idea for a product value experience, and you have tools for creating it and infrastructure for running it. It’s time to start building a shippable product. As we will cover in more detail in the next chapter, the product development process starts with a concept of requirements (whether we call it a story, use case, or scenario is not important). Requirements are numerous and evolving, and we’re going to take some time looking at the process of converting them into IT-based functionality. There is history here back to the earliest days of computing.
In order to design and build a digital product, you need to express what you need the product to do. The conceptual tool used to do this is called Requirement. The literal word “Requirement” has fallen out of favor with the rise of Agile [208], and has a number of synonyms and variations:
-
Use case
-
User story
-
Non-functional requirement
-
Epic
-
Architectural epic
-
Architectural requirement
While these may differ in terms of focus and scope, the basic concept is the same — the requirement, however named, expresses some intent or constraint the system must fulfill. This intent calls for work to be performed.
User Story Mapping is a well known approach [208] with origins in the Scrum community. Here is an example from [67]:
“As a shopper, I can select how I want items shipped based on the actual costs of shipping to my address so that I can make the best decision.”
The basic format is,
As a < type of user >, I want < goal >, so that < some value >.
The story concept is flexible and can be aggregated and decomposed in various ways, as we will discuss in Chapter 4. Our interest here is in the basic stimulus for application development work that it represents.
You don’t need an extensively automated system at this stage to capture requirements, but you need something. It could be a spreadsheet, or a shared word processing document, or sticky notes on a white board (we’ll talk about Kanban in the next section). The important thing is to start somewhere, with team agreement as to what the approach is, so you can move forward collaboratively.
We will discuss approaches for “discovering” user stories and product features in Chapter 4, where Product Management is formalized. For now, as an early startup of one or two people, it is sufficient that you have some basic ability to characterize your system intent -— more formalized techniques come later.
3.6. Test-driven development and refactoring
Testing software and systems is a critically important part of digital product development. The earliest concepts of waterfall development called for it explicitly, and “software tester” as a role and “software quality assurance” as a practice have long histories. Evolutionary approaches to software have a potential major issue with software testing:
As a consequence of the introduction of new bugs, program maintenance requires far more system testing per statement written than any other programming. Theoretically, after each fix one must run the entire bank of test cases previously run against the system, to ensure that it has not been damaged in an obscure way. In practice, such regression testing must indeed approximate this theoretical ideal, and it is very costly.
Mythical Man-Month
This issue was and is well known to thought leaders in Agile software development. The key response has been the concept of automated testing so that any change in the software can be immediately validated before more development along those lines continues. One pioneering tool was JUnit:
The reason JUnit is important … is that the presence of this tiny tool has been essential to a fundamental shift for many programmers. A shift where testing has moved to a front and central part of programming. People have advocated it before, but JUnit made it happen more than anything else.
http://martinfowler.com/books/meszaros.html
From the reality that regression testing was “very costly” (as stated by Brooks in the above quote), the emergence of tools like JUnit (coupled with increasing computer power and availability) changed the face of software development, allowing the ongoing evolution of software systems in ways not previously possible.
3.6.1. Test-driven development
In test-driven development, the idea essence is to write code that tests itself, and in fact to write the test before writing any code. This is done through the creation of test harnesses and the tight association of tests with requirements. The logical culmination of test-driven development was expressed by Kent Beck in eXtreme Programming: write the test first [19]. Thus:
-
Given a “user story” (i.e., system intent) and figure out a test that will demonstrate its successful implementation.
-
Write this test using the established testing framework
-
Write the code that fulfills the test
Some readers may be thinking, “I know how to write a little code, but what is this about using code to write a test?”
While we avoid much in-depth examination of source code in this book, using some simplified Java will help. Here is an example drawn from the original Calavera project, the basis for the companion labs to this book.
|
Important
|
Just read through the example carefully. You do not need to know Java. |
Let’s say we want a function that will take a string of characters (e.g.,a sentence) and wrap it in some HTML “Heading 1” tags. We will name the class “H1Class” and (by convention) we will start by developing a class called TestH1Class.
We write the test first:
public class TestClass1 {
private H1Class a; //
@Before
public void setUp() throws Exception {
this.a = new H1Class(“TestWebMessage”);
}
@Test
public void testTrue() {
assertEquals(“string correctly generated",
"<h1>TestWebMessage</h1>",
this.a.webMessage());// string built correctly
}
}
The code above basically states,
We run the test (e.g.,through JUnit and Ant, which we won’t detail here). It will fail. Then, we write the class:
public class H1Class {
String strMsg;
public String webMessage()
{
return "<h1>” + strMsg + "</h1>";
}
}
|
Important
|
These are simplified examples. |
When we run the test harness correctly (e.g.,using a build tool such as Ant or Maven), the test class will perform the following actions:
-
Create an instance of the class H1Class, based on a string “TestWebMessage”.
-
Confirm that the returned string is “<h1>TestWebMessage</h1>”.
If that string is not correctly generated, or the class cannot be created, or any other error occurs, the test fails and this is then reported via error results at the console, or (in the case of automated build) will be detected by the build manager and displayed as the build outcome. Other languages use different approaches from that shown here, but every serious platform at this point supports test-driven development.
The associated course lab provides a simple but complete example of a test-driven development environment, based on lightweight virtualization.
3.6.2. Refactoring
Refactoring is a controlled technique for improving the design of an existing code base. Its essence is applying a series of small behavior-preserving transformations, each of which is “too small to be worth doing." However, the cumulative effect of each of these transformations is quite significant. By doing them in small steps, you reduce the risk of introducing errors. You also avoid having the system broken while you are carrying out the restructuring — which allows you to refactor a system over an extended period of time gradually.
Refactoring -— http://refactoring.com/
Test-driven development enables the next major practice, that of refactoring. Refactoring is how you address technical debt. What is technical debt? Technical debt is a term coined by Ward Cunningham and is now defined by Wikipedia as
… the eventual consequences of poor system design, software architecture, or software development within a code base. The debt can be thought of as work that needs to be done before a particular job can be considered complete or proper. If the debt is not repaid, then it will keep on accumulating interest, making it hard to implement changes later on … Analogous to monetary debt, technical debt is not necessarily a bad thing, and sometimes technical debt is required to move projects forward. [284]
Test-driven development ensures that the system’s functionality remains consistent, while refactoring provides a means to address technical debt as part of ongoing development activities. Prioritizing the relative investment of repaying technical debt versus developing new functionality will be examined in future sections, but at least you now know the tools and concepts.
We discuss technical debt further in Chapter 12.
3.7. Continuous integration
3.7.1. Version control, again: branching and merging
Oddly enough, it seems that when you run into a painful activity, a good tip is to do it more often.
Foreword to Paul Duvall's Continuous Integration
As systems engineering approaches transform to cloud and infrastructure as code, a large and increasing percentage of IT work takes the form of altering text files and tracking their versions. We have seen this in the previous chapter, with artifacts such as scripts being created to drive the provisioning and configuring of computing resources. Approaches which encourage ongoing development and evolution are increasingly recognized as less risky since systems do not respond well to big “batches” of change. An important concept is that of “continuous integration,” popularized by Paul Duvall in his book of the same name [86].
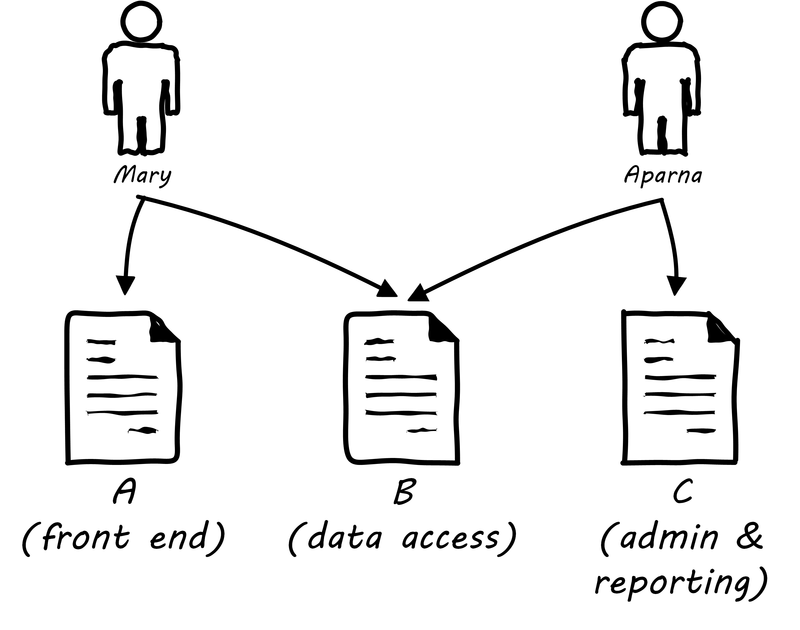
In order to understand why continuous integration is important, it is necessary to discuss further the concept of source control and how it is employed in real-world settings. Imagine Mary has been working for some time with her partner Aparna in their startup (or on a small team) and they have three code modules (see Two developers, one file). Mary is writing the web front end (file A), Aparna is writing the administrative tools and reporting (file C), and they both partner on the data access layer (file B). The conflict, of course, arises on file B that they both need to work on. A and C are mostly independent of each other, but changes to any part of B can have an impact on both their modules.
If changes are frequently needed to B, and yet they cannot split it into logically separate modules, they have a problem; they cannot both work on the same file at the same time. They are each concerned that the other does not introduce changes into B that “break” the code in their own modules A and C.
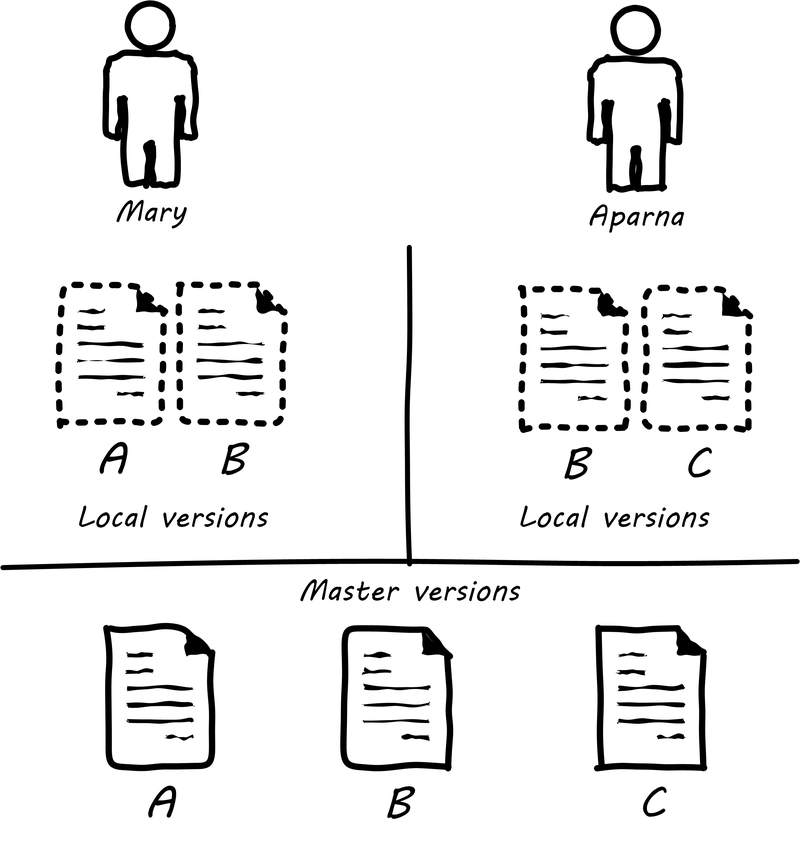
In smaller environments, or under older practices, perhaps there is no conflict, or perhaps they can agree to take turns. But even if they are taking turns, Mary still needs to test her code in A to make sure it’s not been broken by changes Aparna made in B. And what if they really both need to work on B (see File B being worked on by two people) at the same time?
Now, because they took this book’s advice and didn’t start developing until they had version control in place, each of them works on a “local” copy of the file (see illustration “File B being worked on by two people”).
That way, they can move ahead on their local workstations. But when the time comes to combine both of your work, they may find themselves in “merge hell.” They may have chosen very different approaches to solving the same problem, and code may need massive revision to settle on one code base. For example, in the accompanying illustration, Mary’s changes to B are represented by triangles and Aparna’s are represented by circles. They each had a local version on their workstation for far too long, without talking to each other.
|
Note
|
Breaking a system apart by “layer” (e.g.,front end versus data access) does not scale well. Microservices approaches encourage keeping data access and business logic together in functionally cohesive units. More on this in future chapters. But in this example, both developers are on the same small team. It is not always possible (or worth it) to divide work to keep two people from ever needing to change the same thing. |
In the diagrams, we represent the changes graphically; of course, with real code, the different graphics represent different development approaches each person took. For example, Mary had certain needs for how errors were handled, while Aparna had different needs.
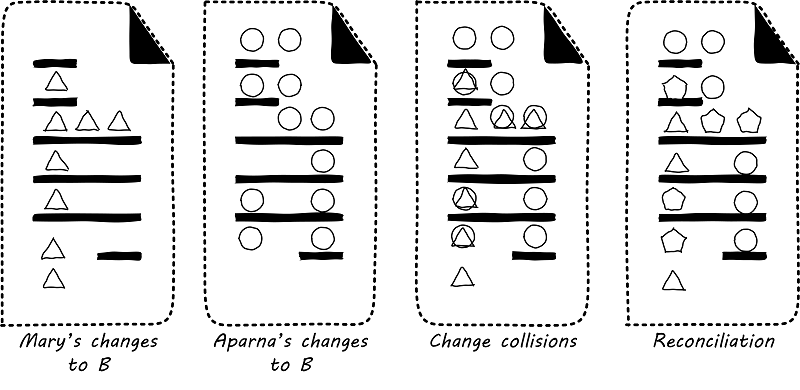
In Merge hell, where triangles and circles overlap, Mary and Aparna painstakingly have to go through and put in a consolidated error handling approach, so that the code supports both of their needs. The problem, of course, is there are now three ways errors are being handled in the code. This is not good, but they did not have time to go back and fix all the cases. This is a classic example of technical debt.
Suppose instead that they had been checking in every day. They can identify the first collision quickly (see Catching errors quickly is valuable), and have a conversation about what the best error handling approach is. This saves them both the rework of fixing the collisions, and the technical debt they might have otherwise accepted:
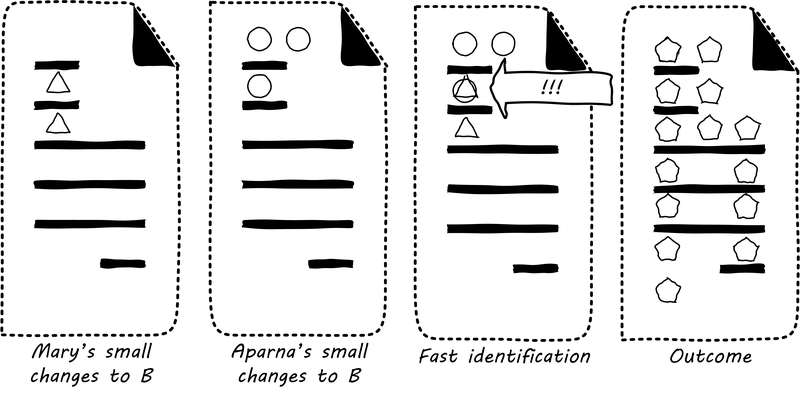
These problems have driven the evolution of software configuration management for decades. In previous methods, to develop a new release, the code would be copied into a very long-lived “branch” (a version of the code to receive independent enhancement). Ongoing “maintenance” fixes of the existing code base would also continue, and the two code bases would inevitably diverge. Switching over to the “new” code base might mean that once-fixed bugs (bugs that had been addressed by maintenance activities) would show up again, and logically, this would not be acceptable. So, when the newer development was complete, it would need to be merged back into the older line of code, and this was rarely if ever easy (again, “merge hell”). In a worst case scenario, the new development might have to be redone.
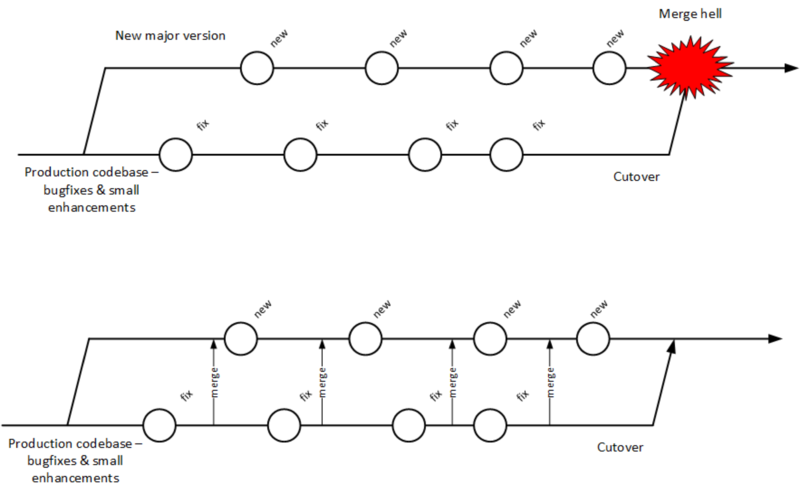
Enter continuous integration (see Big bang versus continuous integration). As presented in [86] the key practices (you will notice similarities to the pipeline discussion) include:
-
Developers run private builds including their automated tests before committing to source control
-
Developers check in to source control at least daily (hopefully, we have been harping on this enough that you are taking it seriously by now)
-
Distributed version control systems such as git are especially popular, although older centralized products are starting to adopt some of their functionality
-
Integration builds happen several times a day or more on a separate, dedicated machine
-
-
100% of tests must pass for each build, and fixing failed builds is the highest priority
-
A package or similar executable artifact is produced for functional testing
-
A defined package repository exists as a definitive location for the build output
These practices are well developed and represent a highly evolved understanding gained through the painful trial and error of many development teams over many years. Rather than locking a file so that only one person can work on it at a time, it’s been found that the best approach is to allow developers to actually make multiple copies of such a file or file set and work on them simultaneously. Wait, you say. How can that work?
This is the principle of continuous integration at work. If the developers are continually pulling each other’s work into their own working copies, and continually testing that nothing has broken, then distributed development can take place. So, if you are a developer, the day’s work might be as follows:
8 AM: check out files from master source repository to a local branch on your workstation. Because files are not committed unless they pass all tests, you know that you are checking out clean code. You pull user story (requirement) that you will now develop.
8:30 AM: You define a test and start developing the code to fulfill it.
10 AM: You are closing in on wrapping up the first requirement. You check the source repository. Your partner has checked in some new code, so you pull it down to your local repository. You run all the automated tests and nothing breaks, so you’re fine.
10:30 AM: You complete your first update of the day; it passes all tests on your workstation. You commit it to the master repository. The master repository is continually monitored by the build server, which takes the code you created and deploys it, along with all necessary configurations, to a dedicated build server (which might be just a virtual machine or transient container). All tests pass there (the test you defined as indicating success for the module, as well as a host of older tests that are routinely run whenever the code is updated).
11:00 AM: Your partner pulls your changes into their working directory. Unfortunately, some changes you made conflict with some work they are doing. You briefly consult and figure out a mutually acceptable approach.
Controlling simultaneous changes to a common file is only one benefit of continuous integration. When software is developed by teams, even if each team has its own artifacts, the system often fails to “come together” for higher-order testing to confirm that all the parts are working correctly together. Discrepancies are often found in the interfaces between components; when component A calls component B, it may receive output it did not expect and processing halts. Continuous integration ensures that such issues are caught early.
3.7.2. Build choreography
Go back to the pipeline picture and consider step 4. While we discussed version control, package management, and deployment management in Chapter 2, this is our first encounter with build choreography.
DevOps and continuous delivery call for automating everything that can be automated. This goal led to the creation of build choreography managers such as Hudson, Jenkins, Travis CI, and Bamboo. Build managers may control any or all of the following steps:
-
Detecting changes in version control repositories and building software in response
-
Alternately, building software on a fixed (e.g.,nightly) schedule
-
Compiling source code and linking it to libraries
-
Executing automated tests
-
Combining compiled artifacts with other resources into installable packages
-
Registering new and updated packages in the package management repository, for deployment into downstream environments
-
In some cases, driving deployment into downstream environments, including production. (This can be done directly by the build manager, or through the build manager sending a message to a deployment management tool).
Build managers play a critical, central role in the modern, automated pipeline and will likely be a center of attention for the new digital professional in their career.
3.8. Releasing software
3.8.1. Continuous deployment
(see Deployment)
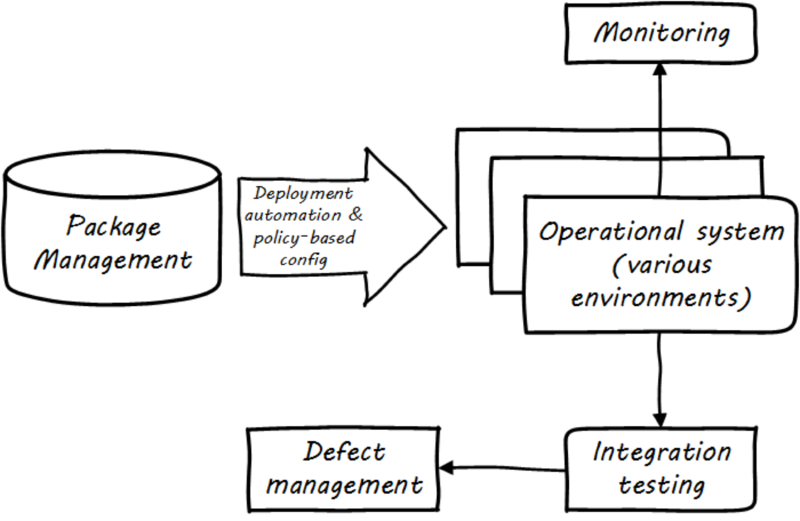
Once the software is compiled and built, the executable files that can be installed and run operationally should be checked into a Package Manager. At that point, the last mile steps can be taken, and deploy the now tested and built software to pre-production or production environments (see Deployment). The software can undergo usability testing, load testing, integration testing, and so forth. Once those tests are passed, it can be deployed to production.
(What is “production,” anyway? We’ll talk about environments in Section 2. For now, you just need to know that when an IT-based product is “in production,” that means it is live and available to its intended base of end users or customers).
Moving new code into production has always been a risky procedure. Changing a running system always entails some uncertainty. However, the practice of infrastructure as code coupled with increased virtualization has reduced the risk. Often, a rolling release strategy is employed so that code is deployed to small sets of servers while other servers continue to service the load. This requires careful design to allow the new and old code to co-exist at least for a brief time.
This is important so that the versions of software used in production are well controlled and consistent. The package manager can then be associated with some kind of deploy tool that keeps track of what versions are associated with which infrastructure.
Timing varies by organization. Some strive for true “continuous deployment”, in which the new code flows seamlessly from developer commit through build, test, package and deploy. Others put gates in between the developer and check-in to mainline, or source-to-build, or package-to-deploy so that some human governance remains in the toolchain. We will go into more detail on these topics in Chapter 6.
3.8.2. The concept of “release”
Release management, and the concept of a “release,” are among the most important and widely-seen concepts in all forms of digital management. Regardless of whether you are a cutting-edge Agile startup with 2 people or one of the largest banks with a portfolio of thousands of applications, you will likely be using releases for coordination and communication.
What is a “release?” Betz defined it this way in other work: “A significant evolution in an IT service, often based on new systems development, coordinated with affected services and stakeholders.” Release management’s role is to “Coordinate the assembly of IT functionality into a coherent whole and deliver this package Into a state in which the customer is getting the intended value”, [24 p. 68, 24 p. 119].
Even as a startup of one, you know when your product is “ready for prime time” or not. Your first “release” should be a cause for some celebration: you now are offering digital value to some part of the world.
We will talk much more about release management in Parts II and III. At this point, you may not see it as much different from simply deploying, but even at the smallest scale, you start to notice that some changes require more thought and communication than others. Simple bugfixes, or self-explanatory changes to the product’s interfaces, can flow through your pipeline. But if you are going to change the system radically -— even if you only have one customer -— you need to communicate with them about this. And so, the concept of release management becomes part of your world.
3.9. Application development topics
3.9.1. Application architecture
The design and architecture of applications is a large topic (see, for example, [104, 96]) and this text only touches lightly on it. ISO/IEC 42010 defines architecture as "The fundamental concepts or properties of a system in its environment embodied in its elements, relationships, and in the principles of its design and evolution [144]."
A computer program can be as simple as "Hello World." Such a program requires only one or a few files to compile and execute. However, significant applications and systems require hardware and software configurations of tremendous complexity. Specialized visual notations are used to describe this complexity (see Software architecture tool [5]). We will discuss this further in Chapter 12.
3.9.2. Applications and project management
Because the initial applications were implemented as a kind of systems engineering and were expensive to build and maintain, the technique of choice was project management. Project management will not be covered in this book until Part III, as it is not appropriate to the earlier stages of this book’s emergence model.
This history of project managed systems engineering produced any number of successes, but by the early 1990s there were significant concerns about the rate of large project failures [107], which occurred despite seemingly extensive and rigorous bureaucratic overhead, evidenced by frameworks such as CMMI and PMBOK. Both project management and CMMI have come in for significant criticism [162, 150] and will be discussed further in Sections 3 and 4.
3.10. Conclusion
Applications are why computers exist. Supporting applications are increasingly less about systems engineering, and more about quickly provisioning standard, shared infrastructure. Application development has moved decisively in the past 20 years to Agile delivery models, based on techniques such as:
-
Story mapping
-
Test-driven development
-
Refactoring
-
Continuous integration
-
Continuous deployment
Application delivery, software development, and the Agile movement are broad, complex, and evolving topics. For those of you familiar with Agile, we have only scratched the surface in this chapter. In future chapters, we will go into more detail on topics such as:
-
Product management, including behavior-driven development and continuous design (much more on requirements, user stories, etc.).
-
The importance of feedback
-
Prioritization and cost of delay
-
Scrum and Kanban
-
Tracking tasks and effort
-
Closing the loop from operations to development, and coping with interrupt-driven work
and much more.
3.10.1. Discussion questions
-
What is your exposure to application programming?
-
Can you think of examples of waterfall and agile approaches in your daily life (not necessarily related to IT?)
-
Have you been on a project that needed more planning (IT or not)? For example, have you ever gone to the hardware store 5 times in one day, and felt by the end that you should have thought a little more at first?
-
Have you ever been in a situation where planning never seemed to end? Why?
-
If you are a developer, read Things You Should Never Do, Part I. What do you think? Are you ever tempted to re-write something instead of figuring out how it works?
3.10.2. Research & practice
-
Review the debates over Agile in IEEE Software in the early 2000s and write a retrospective report on the thinking at the time.
-
Review Amazon’s AWS CodePipeline
3.10.3. Further reading
Books
-
Martin Fowler, Refactoring
-
McConnell, Steve, Code Complete
-
Jez Humble & David Farley, Continuous Delivery
-
Gene Kim et al., Phoenix Project
-
Paul Duvall et al., Continuous Integration
-
Michael Nygard, Release IT
Articles